Hoe een verdeling in seaborn uit te zetten: met voorbeelden
U kunt de volgende methoden gebruiken om een verdeling van waarden in Python te plotten met behulp van de seaborn datavisualisatiebibliotheek:
Methode 1: Teken de verdeling met behulp van het histogram
sns. displot (data)
Methode 2: Teken de verdeling met behulp van de dichtheidscurve
sns. displot (data, kind=' kde ')
Methode 3: Teken de verdeling met behulp van histogram en dichtheidscurve
sns. displot (data, kde= True )
De volgende voorbeelden laten zien hoe u elke methode in de praktijk kunt gebruiken.
Voorbeeld 1: De verdeling uitzetten met behulp van een histogram
De volgende code laat zien hoe u de verdeling van waarden in een NumPy-array kunt plotten met behulp van de functie displot() in seaborn:
import seaborn as sns
import numpy as np
#make this example reproducible
n.p. random . seed ( 1 )
#create array of 1000 values that follows a normal distribution with mean of 10
data = np. random . normal (size= 1000 , loc= 10 )
#create histogram to visualize distribution of values
sns. displot (data)
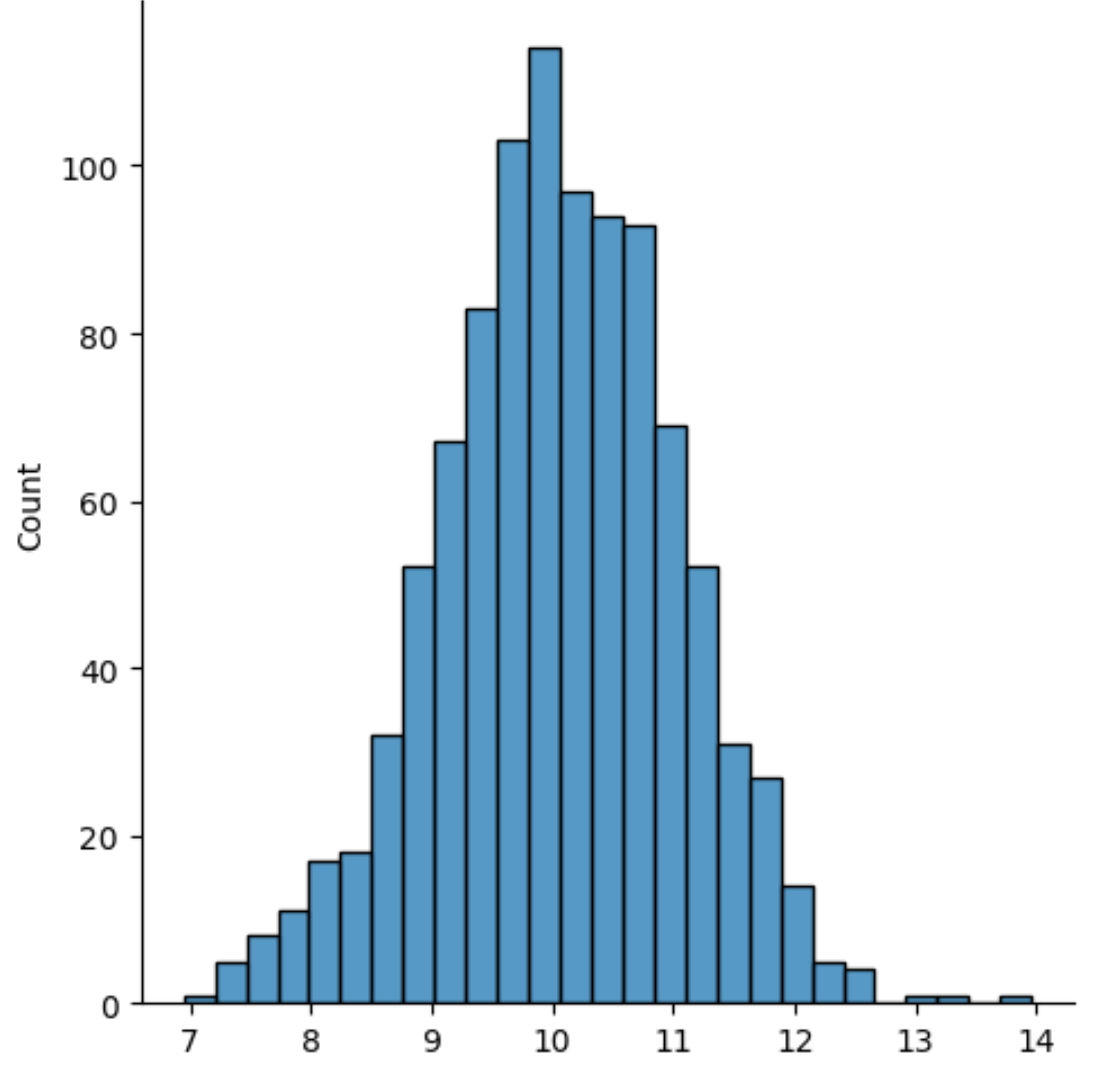
De X-as geeft de waarden van de verdeling weer en de Y-as geeft het aantal van elke waarde weer.
Om het aantal bakken dat in het histogram wordt gebruikt te wijzigen, kunt u een getal opgeven met behulp van het argument bakken :
import seaborn as sns
import numpy as np
#make this example reproducible
n.p. random . seed ( 1 )
#create array of 1000 values that follows a normal distribution with mean of 10
data = np. random . normal (size= 1000 , loc= 10 )
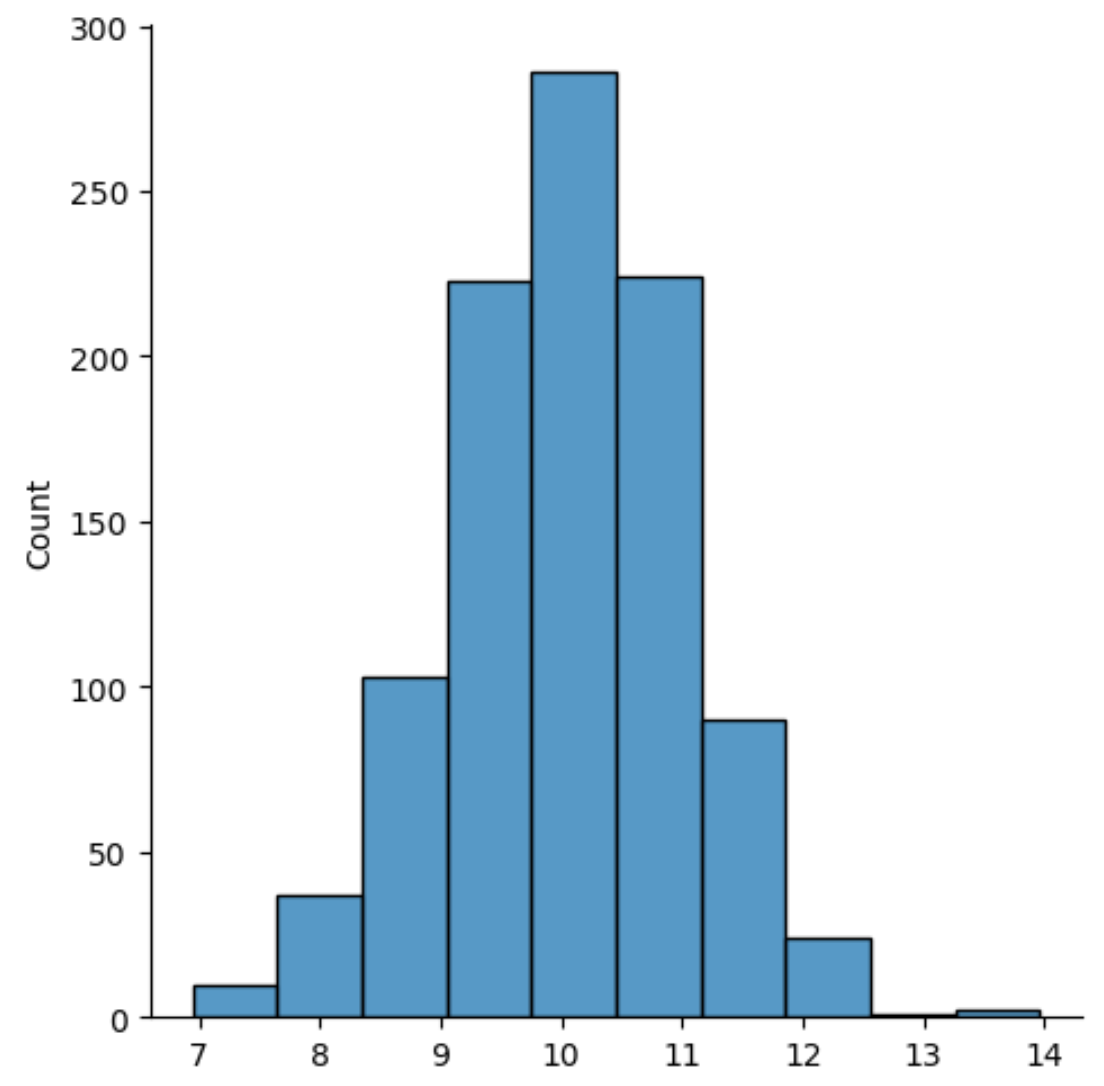
#create histogram using 10 bins
sns. displot (data, bins= 10 )
Voorbeeld 2: De verdeling uitzetten met behulp van de dichtheidscurve
De volgende code laat zien hoe u de verdeling van waarden in een NumPy-array kunt plotten met behulp van een dichtheidscurve:
import seaborn as sns
import numpy as np
#make this example reproducible
n.p. random . seed ( 1 )
#create array of 1000 values that follows a normal distribution with mean of 10
data = np. random . normal (size= 1000 , loc= 10 )
#create density curve to visualize distribution of values
sns. displot (data, kind=' kde ')
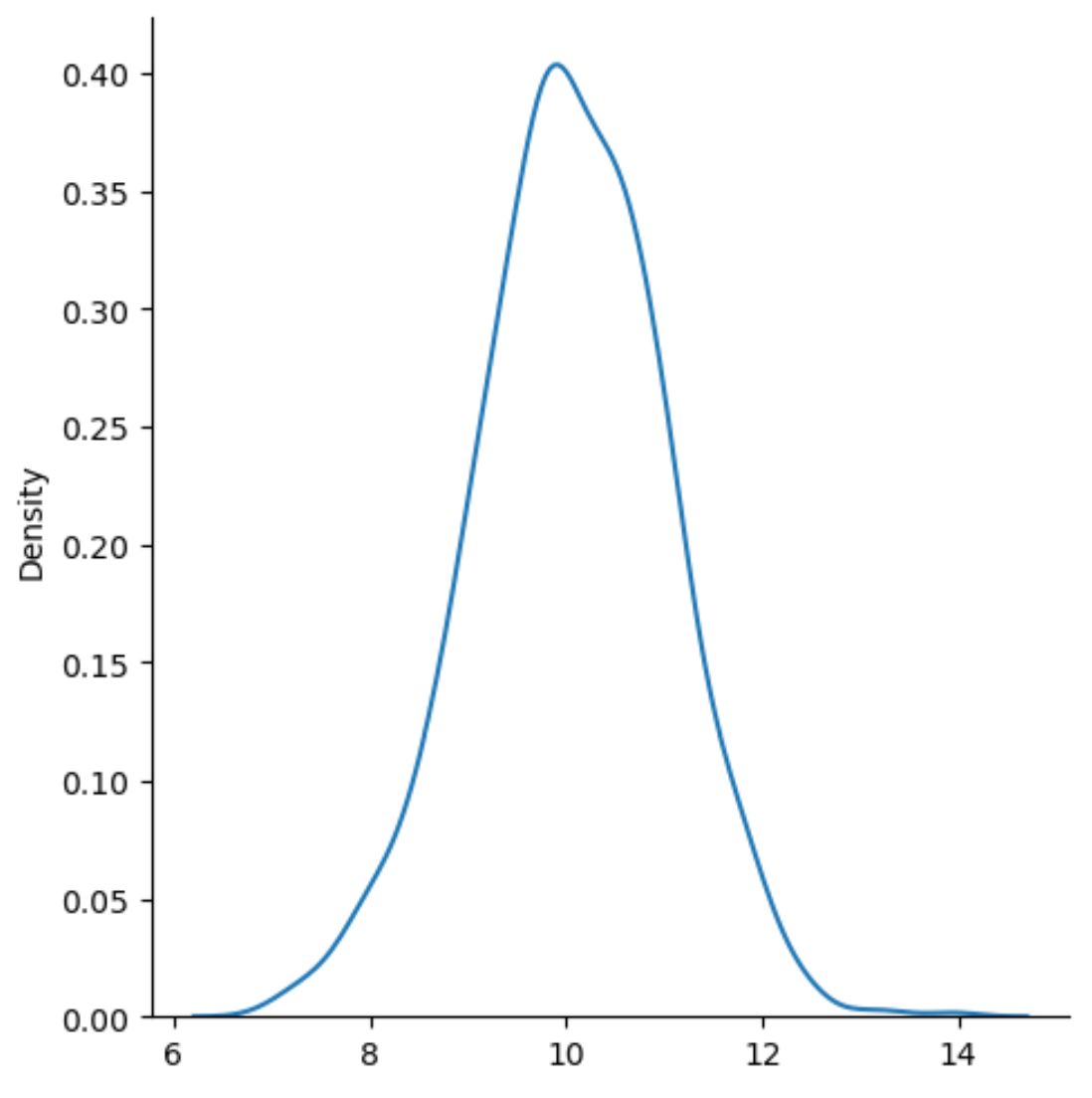
De x-as geeft de waarden van de verdeling weer en de y-as geeft de relatieve frequentie van elke waarde weer.
Merk op dat kind=’kde‘ seaborn vertelt om kernel density estimation te gebruiken, wat een vloeiende curve oplevert die de verdeling van de waarden van een variabele samenvat.
Voorbeeld 3: De verdeling uitzetten met behulp van het histogram en de dichtheidscurve
De volgende code laat zien hoe u de verdeling van waarden in een NumPy-array kunt plotten met behulp van een histogram waarop een dichtheidscurve is geplaatst:
import seaborn as sns
import numpy as np
#make this example reproducible
n.p. random . seed ( 1 )
#create array of 1000 values that follows a normal distribution with mean of 10
data = np. random . normal (size= 1000 , loc= 10 )
#create histogram with density curve overlaid to visualize distribution of values
sns. displot (data, kde= True )
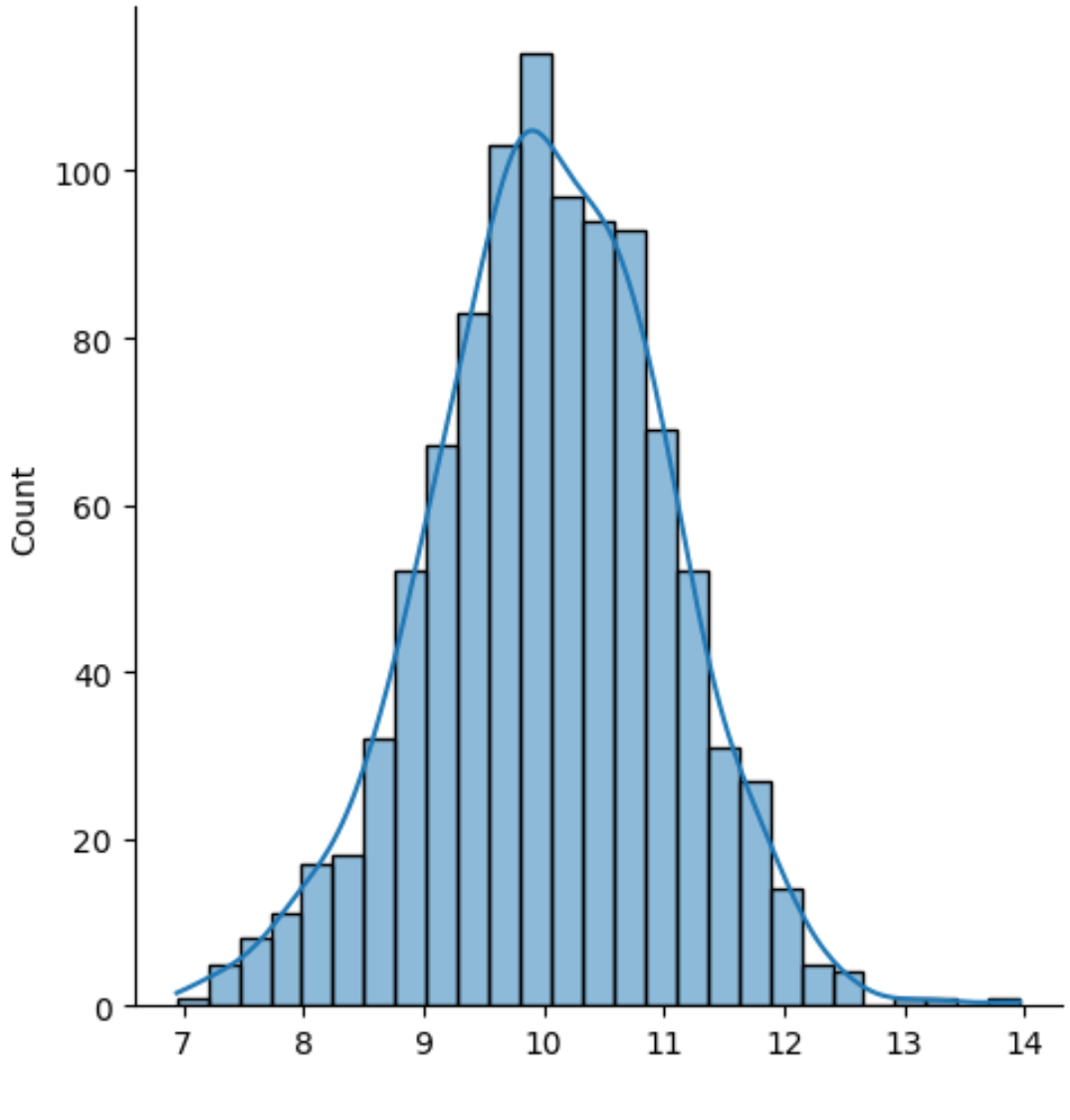
Het resultaat is een histogram met daarop een dichtheidscurve.
Opmerking : u kunt de volledige documentatie voor de functie seaborn displot() hier vinden.
Aanvullende bronnen
In de volgende tutorials wordt uitgelegd hoe u andere veelvoorkomende taken kunt uitvoeren met behulp van seaborn:
Een titel toevoegen aan Seaborn-plots
Hoe de lettergrootte in Seaborn-plots te wijzigen
Hoe u het aantal ticks in Seaborn-plots kunt aanpassen
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder