Hoe fisher's least significant difference (lsd) te gebruiken in r
Een eenrichtings-ANOVA wordt gebruikt om te bepalen of er al dan niet een statistisch significant verschil bestaat tussen de gemiddelden van drie of meer onafhankelijke groepen.
De aannames die bij een eenrichtings-ANOVA worden gebruikt, zijn:
- H 0 : De gemiddelden zijn voor elke groep gelijk.
- H A : Minstens één van de manieren is anders dan de andere.
Als de p-waarde van de ANOVA onder een bepaald significantieniveau ligt (zoals α = 0,05), kunnen we de nulhypothese verwerpen en concluderen dat ten minste één van de groepsgemiddelden verschilt van de andere.
Maar om precies te weten welke groepen van elkaar verschillen, moeten we een post-hoc test doen.
Een veelgebruikte post-hoc-test is de Fisher’s minst significante verschil (LSD)-test .
U kunt de functie LSD.test() uit het agricolae- pakket gebruiken om deze test in R uit te voeren.
Het volgende voorbeeld laat zien hoe u deze functie in de praktijk kunt gebruiken.
Voorbeeld: Fisher’s LSD-test in R
Stel dat een hoogleraar wil weten of drie verschillende studietechnieken wel of niet tot verschillende toetsscores onder studenten leiden.
Om dit te testen wijst ze willekeurig 10 studenten toe om elke studietechniek te gebruiken en registreert ze hun examenresultaten.
De volgende tabel toont de examenresultaten van elke student op basis van de gebruikte studietechniek:
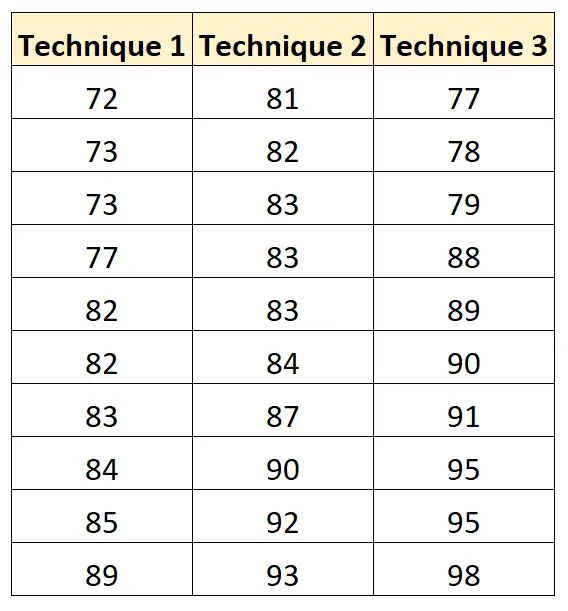
We kunnen de volgende code gebruiken om deze dataset te maken en er een one-way ANOVA op uit te voeren in R:
#create data frame
df <- data. frame (technique = rep(c("tech1", "tech2", "tech3"), each = 10 ),
score = c(72, 73, 73, 77, 82, 82, 83, 84, 85, 89,
81, 82, 83, 83, 83, 84, 87, 90, 92, 93,
77, 78, 79, 88, 89, 90, 91, 95, 95, 98))
#view first six rows of data frame
head(df)
technical score
1 tech1 72
2 tech1 73
3 tech1 73
4 tech1 77
5 tech1 82
6 tech1 82
#fit one-way ANOVA
model <- aov(score ~ technique, data = df)
#view summary of one-way ANOVA
summary(model)
Df Sum Sq Mean Sq F value Pr(>F)
technical 2 341.6 170.80 4.623 0.0188 *
Residuals 27,997.6 36.95
---
Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Omdat de p-waarde in de ANOVA-tabel (0,0188) kleiner is dan 0,05, kunnen we concluderen dat niet alle gemiddelde examenscores tussen de drie groepen gelijk zijn.
We kunnen dus de Fisher’s LSD-test uitvoeren om te bepalen welke groepsgemiddelden verschillend zijn.
De volgende code laat zien hoe u dit doet:
library (agricolae)
#perform Fisher's LSD
print( LSD.test (model," technic "))
$statistics
MSerror Df Mean CV t.value LSD
36.94815 27 84.6 7.184987 2.051831 5.57767
$parameters
test p.adjusted name.t ntr alpha
Fisher-LSD none technical 3 0.05
$means
std score r LCL UCL Min Max Q25 Q50 Q75
tech1 80.0 5.868939 10 76.05599 83.94401 72 89 74.00 82.0 83.75
tech2 85.8 4.391912 10 81.85599 89.74401 81 93 83.00 83.5 89.25
tech3 88.0 7.557189 10 84.05599 91.94401 77 98 81.25 89.5 94.00
$comparison
NULL
$groups
score groups
tech3 88.0 a
tech2 85.8a
tech1 80.0 b
attr(,"class")
[1] “group”
Het deel van het resultaat dat ons het meest interesseert, is de sectie genaamd $groups . Technieken met verschillende karakters in de groepenkolom zijn heel verschillend.
Uit het resultaat kunnen we zien:
- Techniek 1 en Techniek 3 hebben significant verschillende gemiddelde examenscores (aangezien tech1 de waarde “b” heeft en tech3 de waarde “a”).
- Techniek 1 en Techniek 2 hebben significant verschillende gemiddelde examenscores (aangezien tech1 de waarde “b” heeft en tech2 de waarde “a”).
- Techniek 2 en Techniek 3 hebben geen significant verschillende gemiddelde examenscores (aangezien ze allebei een “a”-waarde hebben)
Aanvullende bronnen
In de volgende tutorials wordt uitgelegd hoe u andere veelvoorkomende taken in R kunt uitvoeren:
Eenrichtings-ANOVA uitvoeren in R
Een Bonferroni post-hoc-test uitvoeren in R
Hoe de Scheffe post-hoc-test uit te voeren in R
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder