Voor- en nadelen van het gebruik van gemiddelde in statistieken
Het gemiddelde van een dataset vertegenwoordigt de gemiddelde waarde van de dataset.
Het wordt als volgt berekend:
Gemiddeld = Σx i / n
Goud:
- Σ: Een symbool dat “som” betekent
- x i : De i- de observatie in een dataset
- n: het totale aantal waarnemingen in de dataset
Er zijn twee belangrijke voordelen aan het gebruik van het gemiddelde om het ‘centrum’ of ‘gemiddelde’ van een dataset te beschrijven:
Voordeel #1: Het gemiddelde gebruikt bij de berekening alle waarnemingen uit een dataset. In de statistiek is dit over het algemeen een goede zaak, omdat er wordt gezegd dat alle beschikbare informatie in een dataset wordt gebruikt.
Voordeel #2: Het gemiddelde is eenvoudig te berekenen en te interpreteren. Het gemiddelde is de som van alle waarnemingen gedeeld door het totale aantal waarnemingen. Het is zowel gemakkelijk te berekenen (zelfs handmatig) als gemakkelijk te interpreteren.
Het gebruik van het gemiddelde om een dataset samen te vatten heeft echter twee potentiële nadelen:
Nadeel #1: Het gemiddelde wordt beïnvloed door uitschieters. Als een dataset een extreme uitschieter heeft, heeft dit invloed op het gemiddelde en wordt het een onbetrouwbare maatstaf voor het centrum van een dataset.
Nadeel #2: Het gemiddelde kan misleidend zijn bij scheve datasets. Wanneer een dataset naarlinks of rechts wordt gekanteld, kan middeling een misleidende manier zijn om het midden van een dataset te meten.
De volgende voorbeelden illustreren deze voor- en nadelen in de praktijk.
Voorbeeld 1: De voordelen van het gebruik van het gemiddelde
Stel dat we het volgende histogram hebben dat de salarissen van inwoners van een bepaalde stad laat zien:
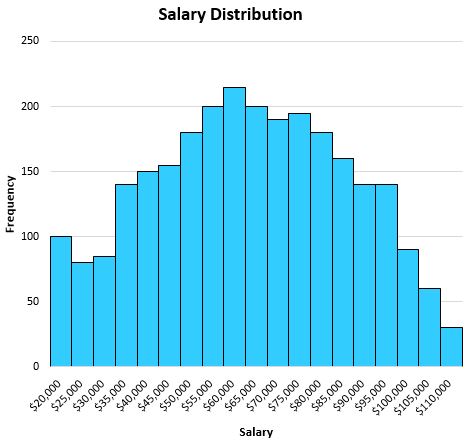
Omdat deze verdeling over het algemeen symmetrisch is (als je hem in het midden splitst, ziet elke helft er ongeveer gelijk uit) en er geen uitschieters zijn, is het gemiddelde een nuttige manier om het middelpunt van deze reeks gegevens te beschrijven.
Het gemiddelde blijkt $63.000 te zijn, wat ongeveer in het midden van de verdeling ligt:
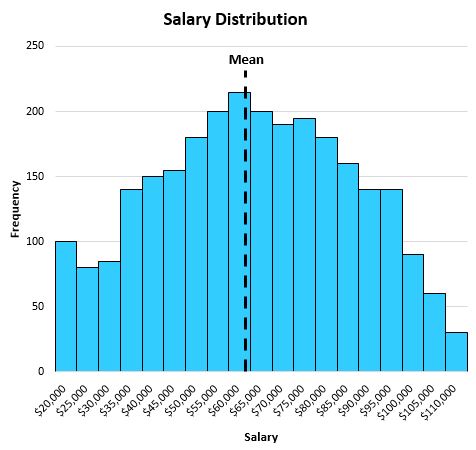
In dit specifieke voorbeeld konden we beide voordelen van middelen gebruiken:
Voordeel #1: Het gemiddelde gebruikt bij de berekening alle waarnemingen uit een dataset.
Omdat de verdeling in wezen symmetrisch was en er geen extreme uitschieters waren, konden we alle beschikbare salarissen gebruiken om het gemiddelde te berekenen, waardoor we een goed beeld kregen van het ‘gemiddelde’ of ‘typische’ salaris in deze specifieke stad.
Voordeel #2: Het gemiddelde is eenvoudig te berekenen en te interpreteren. Het is gemakkelijk te begrijpen dat het gemiddelde salaris van $63.000 het ‘gemiddelde’ salaris van een individu in deze stad vertegenwoordigt.
Hoewel sommige individuen veel meer verdienen dan dit en anderen veel minder, geeft deze gemiddelde waarde ons een goed idee van een ‘typisch’ salaris in deze stad.
Voorbeeld 2: De nadelen van het gebruik van het gemiddelde
Stel dat we een zeer scheve salarisverdeling hebben en we besluiten zowel het gemiddelde als het mediaansalaris te berekenen:
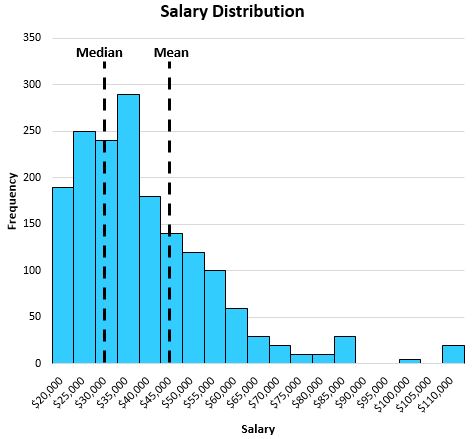
Hogere waarden aan de staart van de verdeling verplaatsen het gemiddelde van het midden naar de lange staart.
In dit voorbeeld vertelt het gemiddelde ons dat een gemiddeld individu ongeveer $47.000 per jaar verdient, terwijl de mediaan ons vertelt dat het typische individu slechts ongeveer $32.000 per jaar verdient, wat veel representatiever is voor het typische individu.
In dit voorbeeld geeft het gemiddelde de „typische“ of „gemiddelde“ waarde in deze verdeling slecht weer, omdat de verdeling scheef is.
Of stel dat we een andere verdeling hebben die informatie bevat over de vierkante meters van huizen in een bepaalde straat en we besluiten zowel het gemiddelde als de mediaan van de dataset te berekenen:
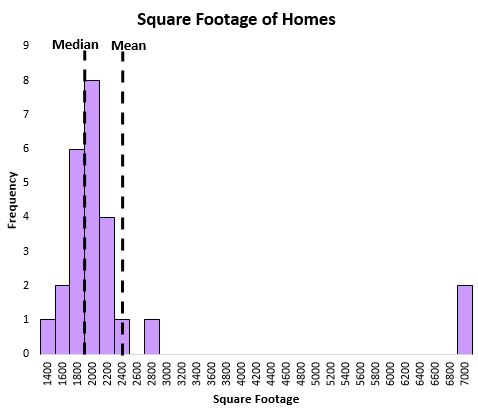
Het gemiddelde wordt beïnvloed door enkele extreem grote huizen, waardoor deze een veel hogere waarde aannemen.
Dit maakt de gemiddelde vierkante meterwaarde misleidend en geeft een slechte maatstaf voor de ‘typische’ vierkante meter van een huis in die straat.
Aanvullende bronnen
De volgende tutorials bieden aanvullende informatie over het gemiddelde en de mediaan in statistieken:
Hoe beïnvloeden uitbijters het gemiddelde?
Hoe u het gemiddelde en de mediaan van elk histogram kunt schatten
Hoe u het gemiddelde en de mediaan van stengel- en bladplots kunt vinden
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder