Hoe voorspelde waarden en residuen in stata te krijgen
Lineaire regressie is een methode die we kunnen gebruiken om de relatie tussen een of meer verklarende variabelen en een responsvariabele te begrijpen.
Wanneer we lineaire regressie uitvoeren op een dataset, krijgen we een regressievergelijking die kan worden gebruikt om de waarden van een responsvariabele te voorspellen, gegeven de waarden van de verklarende variabelen.
We kunnen vervolgens het verschil meten tussen de voorspelde waarden en de werkelijke waarden om de residuen voor elke voorspelling te verkrijgen. Dit helpt ons een idee te krijgen van hoe goed ons regressiemodel de responswaarden voorspelt.
In deze tutorial wordt uitgelegd hoe u zowel voorspelde waarden als residuen kunt verkrijgen voor een regressiemodel in Stata.
Voorbeeld: hoe u voorspelde waarden en residuen kunt verkrijgen
Voor dit voorbeeld gebruiken we de ingebouwde Stata-gegevensset genaamd auto . We zullen mpg en verplaatsing gebruiken als verklarende variabelen en prijs als responsvariabele.
Gebruik de volgende stappen om een lineaire regressie uit te voeren en verkrijg vervolgens de voorspelde waarden en residuen voor het regressiemodel.
Stap 1: Gegevens laden en weergeven.
Eerst zullen we de gegevens laden met behulp van de volgende opdracht:
automatisch gebruik van het systeem
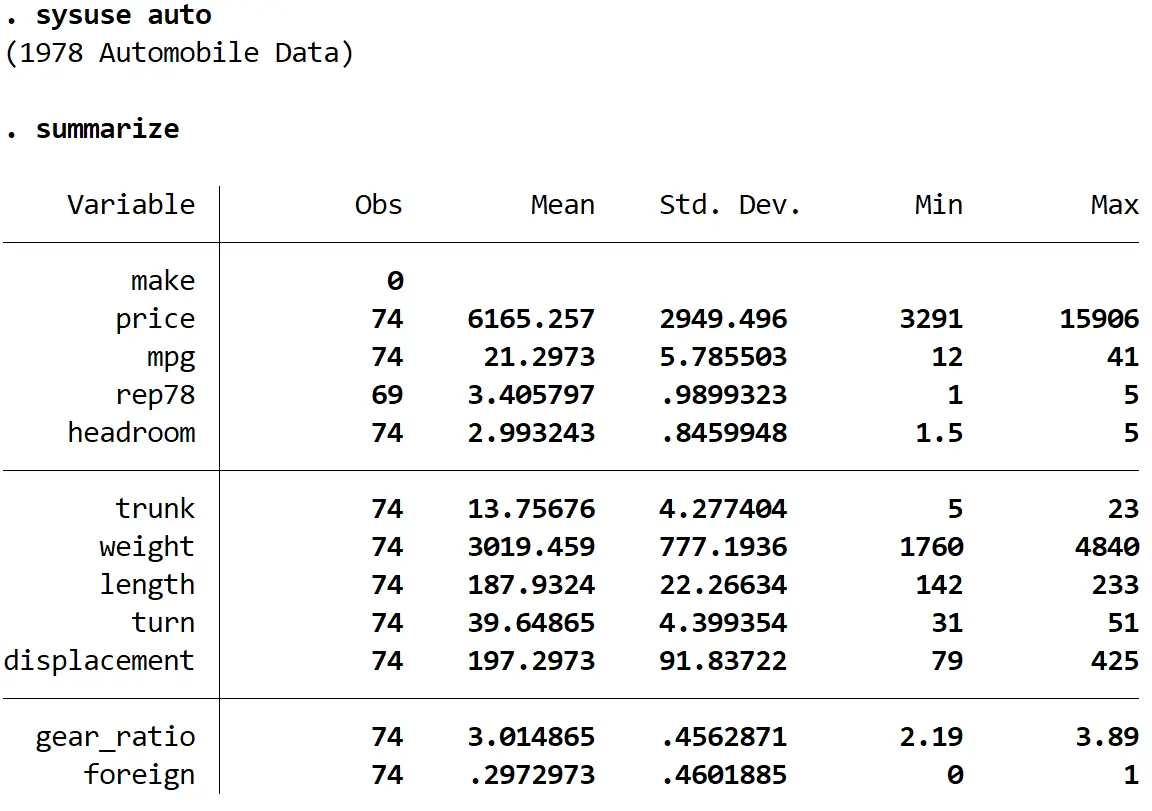
Vervolgens krijgen we een snel overzicht van de gegevens met behulp van de volgende opdracht:
samenvatten
Stap 2: Pas het regressiemodel aan.
Vervolgens zullen we de volgende opdracht gebruiken om het regressiemodel aan te passen:
regressie prijs mpg verplaatsing
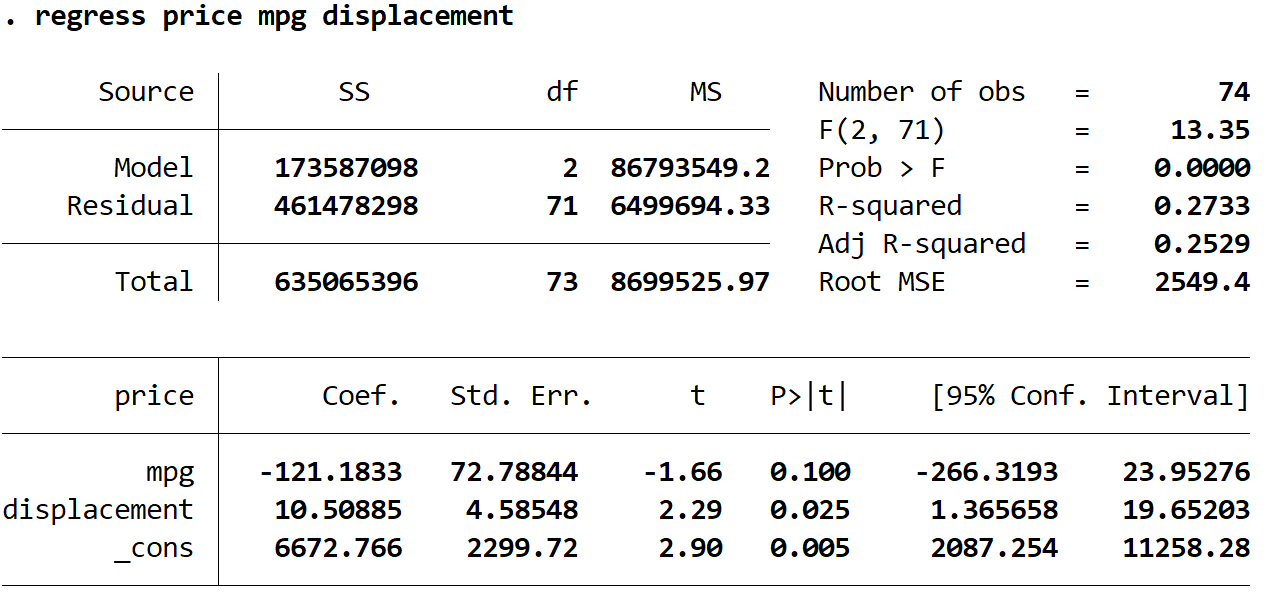
De geschatte regressievergelijking is:
geschatte prijs = 6672,766 -121,1833*(mpg) + 10,50885*(verplaatsing)
Stap 3: Haal de voorspelde waarden op.
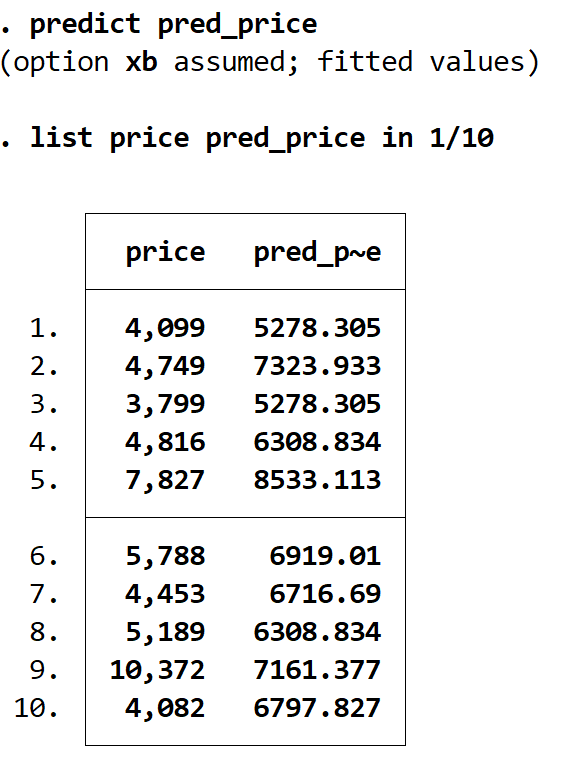
We kunnen de voorspelde waarden verkrijgen door het voorspellen- commando te gebruiken en deze waarden op te slaan in een variabele met de naam zoals wij dat willen. In dit geval gebruiken we de naam pred_price :
voorspel pred_price
We kunnen werkelijke prijzen en voorspelde prijzen naast elkaar weergeven met behulp van de lijstopdracht . Er zijn in totaal 74 voorspelde waarden, maar we zullen alleen de eerste 10 weergeven met behulp van het commando in 1/10 :
catalogusprijs pred_price in 1/10
Stap 4: Haal het residu op.
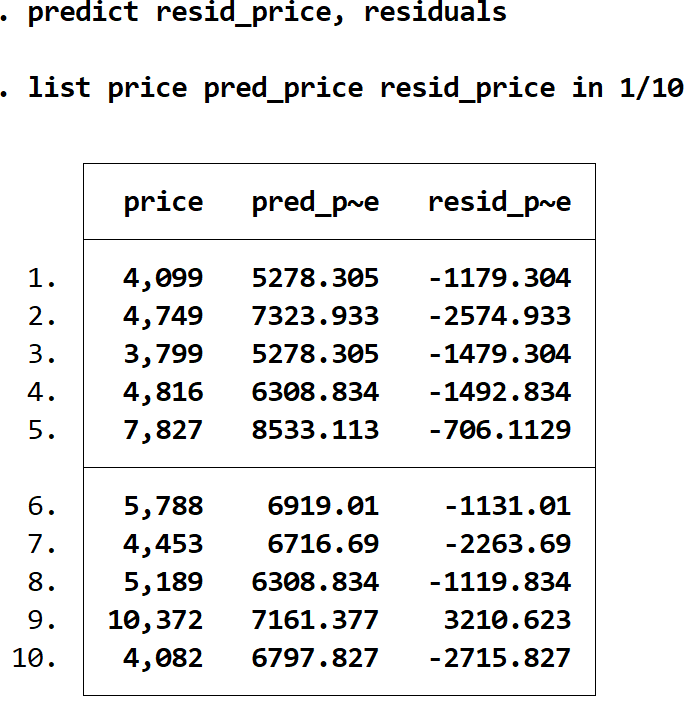
We kunnen de residuen van elke voorspelling verkrijgen door het commando residuen te gebruiken en deze waarden op te slaan in een variabele met de naam welke we maar willen. In dit geval gebruiken we de naam resid_price :
voorspel verblijfsprijs, residuen
We kunnen de werkelijke prijs, de verwachte prijs en de residuen naast elkaar weergeven met behulp van het lijstcommando :
catalogusprijs pred_price resid_price in 1/10
Stap 5: Maak een plot van voorspelde waarden tegen residuen.
Ten slotte kunnen we een spreidingsdiagram maken om de relatie tussen de voorspelde waarden en de residuen te visualiseren:
spreiding verblijf_prijs pred_prijs
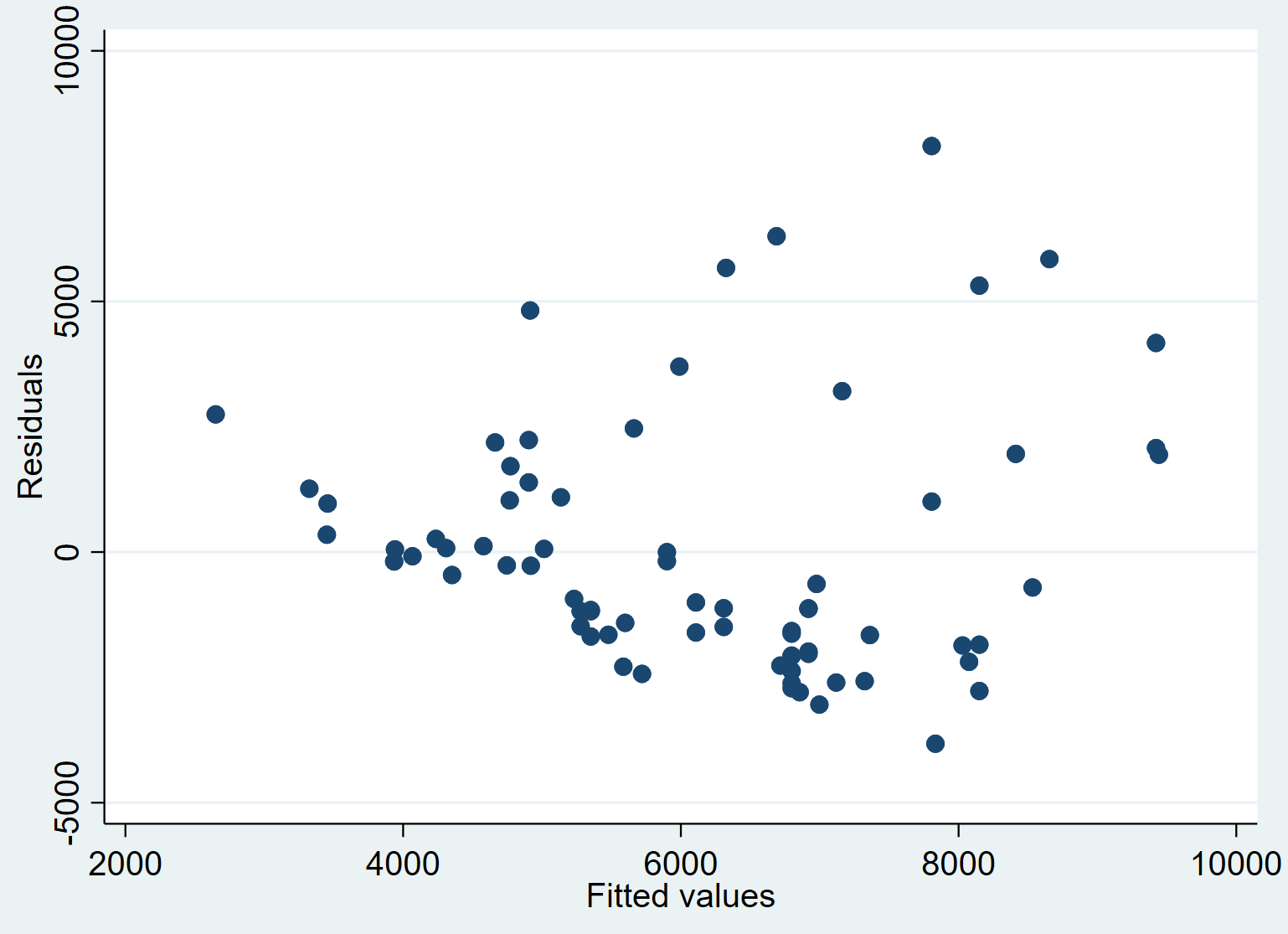
We kunnen zien dat de residuen gemiddeld genomen de neiging hebben toe te nemen naarmate de aangepaste waarden toenemen. Dit zou een teken kunnen zijn van heteroskedasticiteit – wanneer de verdeling van de residuen niet constant is op elk responsniveau.
We zouden formeel kunnen testen op heteroscedasticiteit met behulp van de Breusch-Pagan-test en dit kunnen aanpakken met behulp van robuuste standaardfouten .
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder