Proste wprowadzenie do usprawniania uczenia maszynowego
Większość nadzorowanych algorytmów uczenia maszynowego opiera się na użyciu jednego modelu predykcyjnego, takiego jak regresja liniowa , regresja logistyczna , regresja grzbietowa itp.
Jednakże metody takie jak pakowanie i lasy losowe pozwalają zbudować wiele różnych modeli w oparciu o powtarzające się próbki z oryginalnym zbiorem danych ładowane metodą ładowania początkowego. Prognoz na podstawie nowych danych dokonuje się na podstawie średniej przewidywań poszczególnych modeli.
Metody te zwykle oferują poprawę dokładności przewidywania w porównaniu z metodami, które wykorzystują tylko jeden model predykcyjny, ponieważ wykorzystują następujący proces:
- Najpierw zbuduj indywidualne modele o dużej wariancji i niskim obciążeniu (np. głęboko rozwinięte drzewa decyzyjne ).
- Następnie uśrednij przewidywania poszczególnych modeli, aby zmniejszyć wariancję.
Inną metodą, która zapewnia jeszcze większą poprawę dokładności przewidywań, jest wzmacnianie .
Co to jest wzmacnianie?
Wzmocnienie to metoda, którą można zastosować w przypadku dowolnego typu modelu, ale najczęściej stosuje się ją w przypadku drzew decyzyjnych.
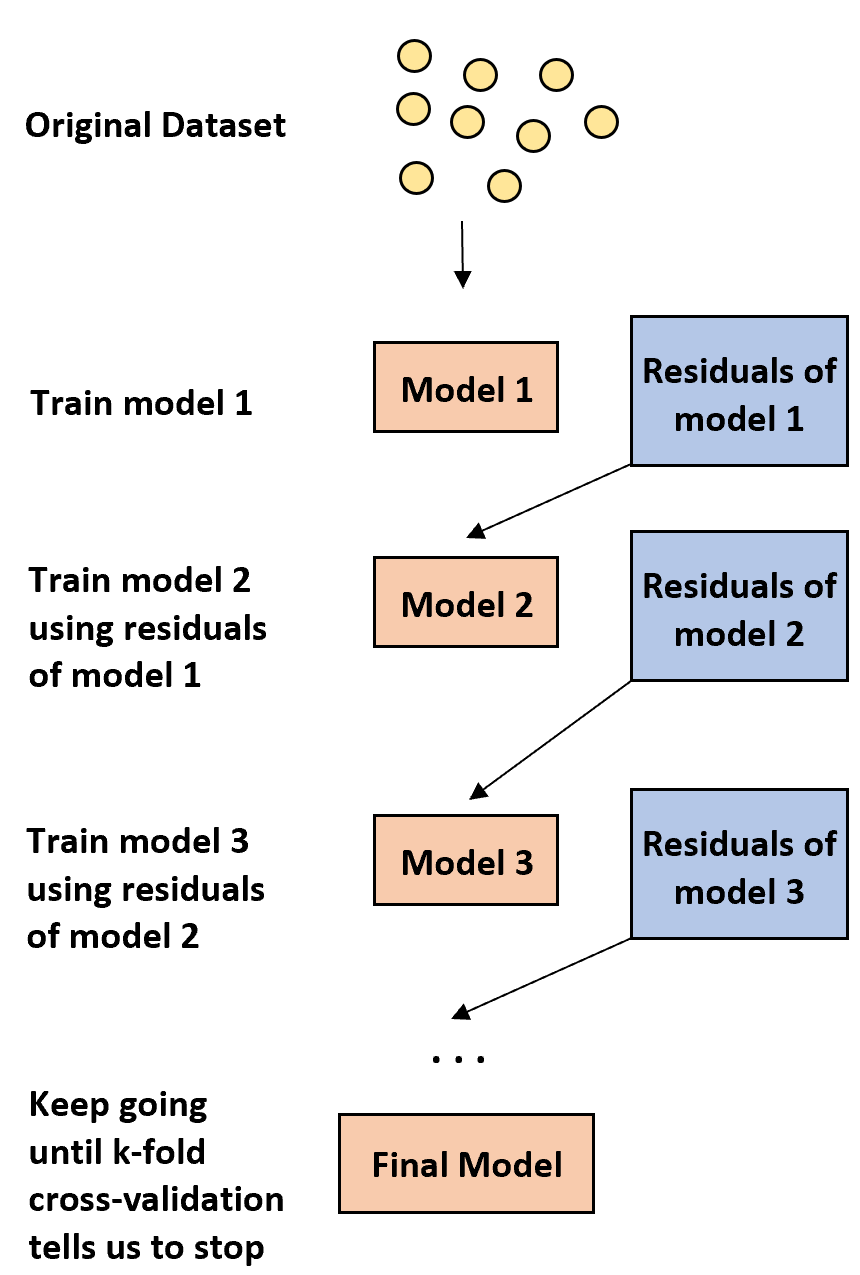
Idea wzmocnienia jest prosta:
1. Najpierw zbuduj słaby model.
- Model „słaby” to taki, w którym poziom błędu jest tylko nieznacznie większy niż oszacowanie losowe.
- W praktyce jest to zazwyczaj drzewo decyzyjne składające się tylko z jednego lub dwóch podziałów.
2. Następnie zbuduj kolejny słaby model w oparciu o reszty z poprzedniego modelu.
- W praktyce używamy reszt z poprzedniego modelu (tj. błędów w naszych przewidywaniach), aby dopasować nowy model, który nieznacznie poprawia ogólny poziom błędu.
3. Kontynuuj ten proces, aż k-krotna walidacja krzyżowa nie każe nam przestać.
- W praktyce używamy k-krotnej walidacji krzyżowej, aby określić, kiedy powinniśmy zaprzestać opracowywania wzmocnionego modelu.
Stosując tę metodę, możemy zacząć od słabego modelu i kontynuować „poprawianie” jego wydajności poprzez sekwencyjne budowanie nowych drzew, które poprawiają wydajność poprzedniego drzewa, aż do uzyskania ostatecznego modelu o dużej dokładności predykcyjnej.
Dlaczego boostowanie działa?
Okazuje się, że wspomaganie jest w stanie wygenerować jedne z najpotężniejszych modeli w całym uczeniu maszynowym.
W wielu branżach modele ulepszone są używane jako modele referencyjne w produkcji, ponieważ mają tendencję do przewyższania wszystkich innych modeli.
Powodem, dla którego ulepszone szablony działają tak dobrze, jest zrozumienie prostego pomysłu:
1. Po pierwsze, ulepszone modele konstruują słabe drzewo decyzyjne o niskiej dokładności predykcyjnej. Mówi się, że to drzewo decyzyjne ma niską wariancję i duże obciążenie.
2. Ponieważ ulepszone modele podążają za procesem sekwencyjnego doskonalenia poprzednich drzew decyzyjnych, ogólny model jest w stanie powoli zmniejszać błąd systematyczny na każdym etapie bez znaczącego zwiększania wariancji.
3. Ostateczny dopasowany model ma zazwyczaj wystarczająco niskie obciążenie i wariancję, co prowadzi do modelu zdolnego do generowania niskich poziomów błędów testowych na nowych danych.
Zalety i wady boostingu
Oczywistą zaletą wzmacniania jest to, że umożliwia ono tworzenie modeli o dużej dokładności predykcyjnej w porównaniu z prawie wszystkimi innymi typami modeli.
Potencjalną wadą jest to, że dopasowany ulepszony model jest bardzo trudny do interpretacji. Chociaż może zaoferować ogromną zdolność przewidywania wartości odpowiedzi nowych danych, trudno jest wyjaśnić dokładny proces, którego używa, aby to osiągnąć.
W praktyce większość analityków danych i praktyków uczenia maszynowego tworzy ulepszone modele, ponieważ chcą móc dokładnie przewidzieć wartości odpowiedzi nowych danych. Zatem fakt, że ulepszone modele są trudne w interpretacji, generalnie nie stanowi problemu.
Booster w praktyce
W praktyce istnieje wiele rodzajów algorytmów stosowanych do boostowania, m.in.:
W zależności od rozmiaru zbioru danych i mocy obliczeniowej komputera jedna z tych metod może być lepsza od drugiej.
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej