Co to są dane wielowymiarowe? (definicja i przykłady)
Dane wielowymiarowe odnoszą się do zbioru danych, w którym liczba cech p jest większa niż liczba obserwacji N , często zapisywana jako p >> N.
Na przykład zbiór danych zawierający p = 6 cech i tylko N = 3 obserwacji będzie uważany za dane wielowymiarowe, ponieważ liczba cech jest większa niż liczba obserwacji.
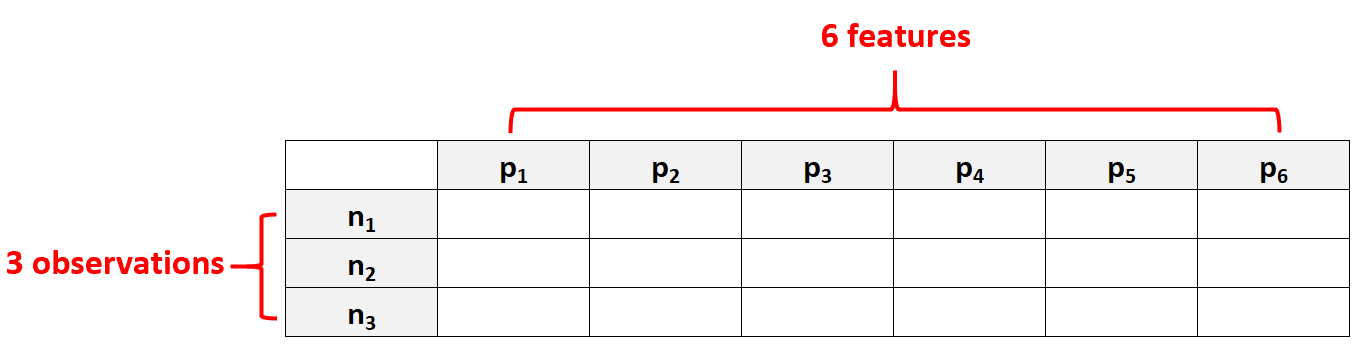
Częstym błędem popełnianym przez ludzi jest założenie, że „dane wielowymiarowe” oznaczają po prostu zbiór danych o wielu funkcjach. Jest to jednak nieprawidłowe. Zbiór danych może zawierać 10 000 obiektów, ale jeśli zawiera 100 000 obserwacji, nie jest wielowymiarowy.
Uwaga: Szczegółowe omówienie matematyki stojącej za danymi wielowymiarowymi można znaleźć w rozdziale 18 książki Elementy uczenia się statystycznego .
Dlaczego dane wielowymiarowe stanowią problem?
Kiedy liczba obiektów w zbiorze danych przekracza liczbę obserwacji, nigdy nie otrzymamy deterministycznej odpowiedzi.
Innymi słowy, znalezienie modelu, który mógłby opisać związek między zmiennymi predykcyjnymi azmienną odpowiedzi , staje się niemożliwe, ponieważ nie mamy wystarczającej liczby obserwacji, na podstawie których można trenować model.
Przykłady danych wielowymiarowych
Poniższe przykłady ilustrują wielowymiarowe zbiory danych w różnych domenach.
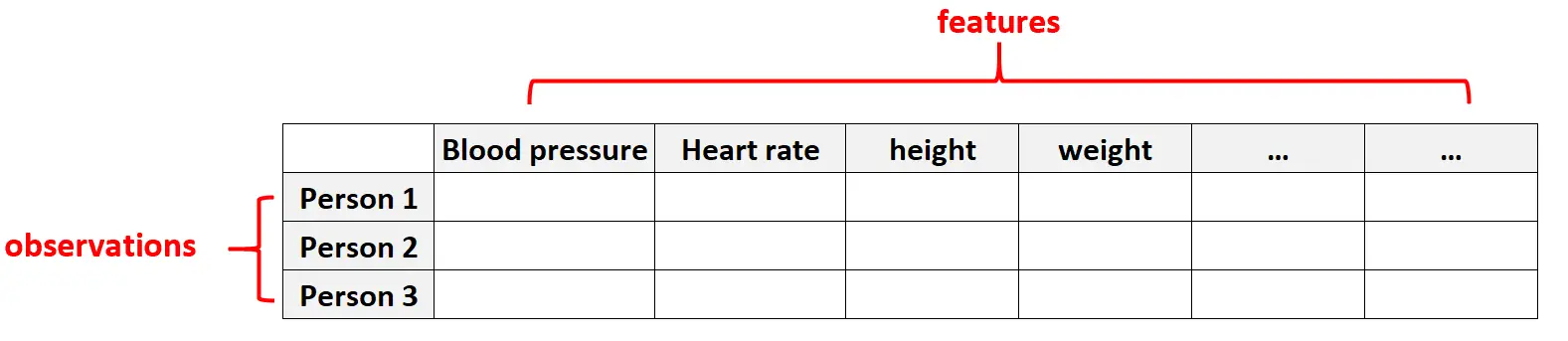
Przykład 1: Dane dotyczące zdrowia
Dane wielowymiarowe są powszechne w zbiorach danych dotyczących opieki zdrowotnej, gdzie liczba cech danej osoby może być ogromna (tj. ciśnienie krwi, tętno spoczynkowe, stan układu odpornościowego, historia operacji, wzrost, waga, istniejące schorzenia itp.).
W tych zbiorach danych często liczba cech jest większa niż liczba obserwacji.
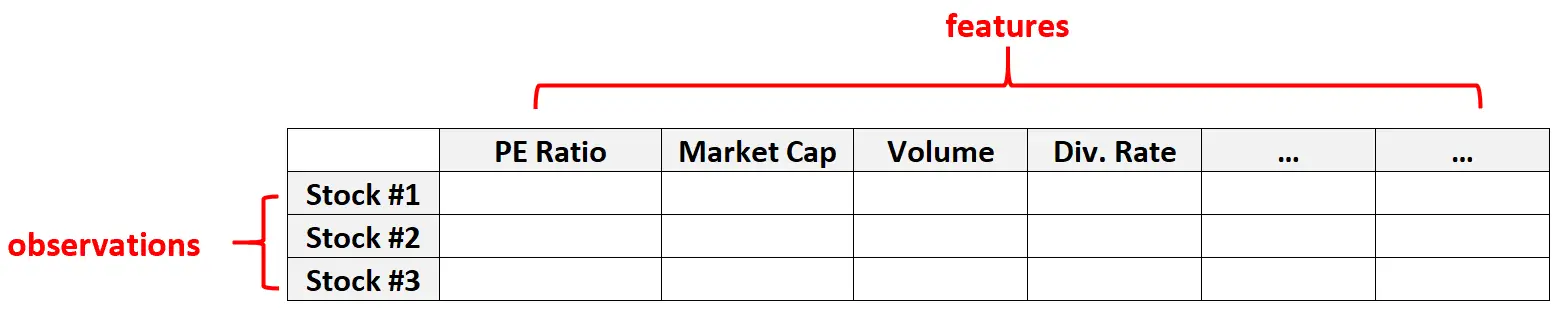
Przykład 2: dane finansowe
Dane wielowymiarowe są również powszechne w zbiorach danych finansowych, gdzie liczba cech danej akcji może być dość duża (tj. współczynnik PE, kapitalizacja rynkowa, wolumen obrotu, stopa dywidendy itp.).
W tego typu zbiorach danych często liczba jednostek jest znacznie większa niż liczba poszczególnych działań.
Przykład 3: Genomika
Dane wielowymiarowe są powszechne także w dziedzinie genomiki, gdzie liczba cech genetycznych danego osobnika może być ogromna.

Jak radzić sobie z dużymi danymi
Istnieją dwa popularne sposoby przetwarzania danych wielowymiarowych:
1. Wybierz mniejszą liczbę funkcji.
Najbardziej oczywistym sposobem na uniknięcie zajmowania się danymi wielowymiarowymi jest po prostu uwzględnienie mniejszej liczby funkcji w zbiorze danych.
Istnieje kilka sposobów decydowania, które funkcje usunąć ze zbioru danych, w tym:
- Usuń funkcje z wieloma brakami danych: jeśli dana kolumna w zestawie danych ma wiele braków danych, możesz je całkowicie usunąć bez utraty dużej ilości informacji.
- Usuń cechy o niskiej wariancji: Jeśli dana kolumna w zbiorze danych ma wartości, które zmieniają się bardzo mało, być może uda się ją usunąć, ponieważ jest mało prawdopodobne, aby oferowała tyle przydatnych informacji o zmiennej odpowiedzi, co inne funkcje.
- Usuń cechy o niskiej korelacji ze zmienną odpowiedzi: Jeśli dana cecha nie jest silnie skorelowana ze zmienną odpowiedzi, która Cię interesuje, prawdopodobnie możesz usunąć ją ze zbioru danych, ponieważ jest mało prawdopodobne, że jest to użyteczna funkcja w modelu.
2. Użyj metody regularyzacji.
Innym sposobem obsługi danych wielowymiarowych bez usuwania funkcji ze zbioru danych jest użycie techniki regularyzacji, takiej jak:
Każdą z tych technik można zastosować do wydajnego przetwarzania danych wielowymiarowych.
Pełną listę wszystkich samouczków dotyczących statystycznego uczenia maszynowego znajdziesz na tej stronie .
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej