Co to jest otwarta dystrybucja?
W statystyce dystrybucja otwarta to rozkład częstotliwości, w którym otwarta jest jedna lub więcej klas (lub „przedziałów”).
Na przykład następujący rozkład częstotliwości reprezentuje rozkład otwarty, w którym otwarta jest najmniejsza klasa:
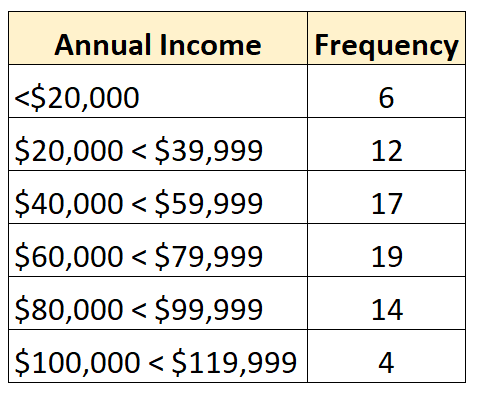
Poniższy rozkład częstotliwości przedstawia rozkład otwarty, w którym otwarta jest największa klasa:
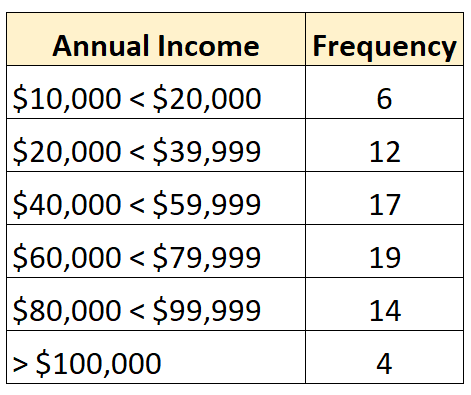
I odwrotnie, rozkład zamknięty to taki, w którym każda klasa rozkładu częstotliwości ma górną i dolną granicę, na przykład:
Co powoduje otwarte dystrybucje?
Otwarte dystrybucje są często wynikiem decyzji badaczy o gromadzeniu danych w taki sposób, że jedna z klas staje się otwarta.
Załóżmy na przykład, że badacz przeprowadza ankietę wśród mieszkańców określonego miasta i pyta ich o roczny dochód gospodarstwa domowego.
Badacz może wybrać najszerszą możliwą odpowiedź „> 100 000 dolarów”, ponieważ wie, że mieszkańcy o wysokich dochodach mogą nie czuć się komfortowo dzieląc się swoimi zarobkami, jeśli są one znacznie wyższe niż 100 000 dolarów.
I odwrotnie, badacz może zdecydować się na udzielenie najkrótszej możliwej odpowiedzi, ponieważ wie, że mieszkańcy, którzy zarabiają bardzo mało, również nie będą czuli się komfortowo dzieląc się tym, co zarabiają.
Krótko mówiąc, badacze często uwzględniają w swoich ankietach kursy otwarte, ponieważ chcą zmaksymalizować liczbę osób, które czują się komfortowo, odpowiadając na pytania zawarte w ankiecie.
Problem z otwartymi dystrybucjami
Problem z otwartymi dystrybucjami polega na tym, że prawdziwe dane są cenzurowane . Innymi słowy, możemy poznać liczbę osób, które w danym mieście zarabiają ponad 100 000 dolarów, ale tak naprawdę nie znamy ich dokładnych rocznych dochodów.
Możliwe, że niektórzy ludzie zarabiają 150 000, 250 000 dolarów, 500 000 dolarów lub nawet więcej, ale nie mamy pojęcia, ponieważ żadna z tych osób nie może wykazać w „dochodzeniu, że zarabia „> 100 000 dolarów”.
Ponieważ dane są cenzurowane w otwartych rozkładach, nie jesteśmy również w stanie obliczyć dokładnej średniej i odchylenia standardowego wartości w zbiorze danych, ponieważ nie mamy dostępu do wszystkich wartości w surowych danych.
Jak analizować dystrybucję otwartą
Ponieważ nie możemy obliczyć dokładnej średniej rozkładu otwartego, często używamy mediany jako miary „środka” zbioru danych.
Przypomnijmy, że mediana reprezentuje środkową wartość zbioru danych.
Pracując z otwartymi rozkładami, możemy użyć następującego wzoru, aby znaleźć najlepsze oszacowanie mediany:
Najlepsze oszacowanie mediany: L + ((n/2 – F) / f) * w
Złoto:
- L: Dolna granica grupy środkowej
- n: Całkowita liczba obserwacji
- F: Częstotliwość skumulowana do grupy środkowej
- f: Częstotliwość grupy środkowej
- w: szerokość grupy środkowej
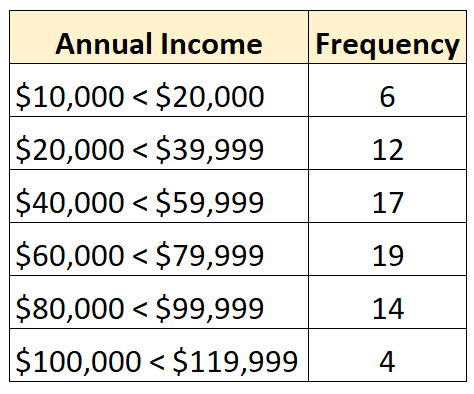
Załóżmy na przykład, że mamy następującą dystrybucję otwartą:
W zbiorze danych znajdują się łącznie 72 wartości. Wiemy zatem, że mediana będzie znajdować się pomiędzy 36. a 37. największą wartością w zbiorze danych. Każda z tych wartości mieści się w klasie „60 000 – 79 999 dolarów”, więc wiemy, że średni dochód mieści się w tym przedziale.
Nasze najlepsze oszacowanie mediany byłoby następujące:
Mediana: 60 000 + ((72/2 – 25) / 19) * 19 999 = 71 578 USD
Wartość ta reprezentuje nasze najlepsze oszacowanie średniego rocznego dochodu osób w tym zbiorze danych.
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej