Jak wykreślić dane kategoryczne w r (z przykładami)
W statystyce dane kategoryczne reprezentują dane, które mogą przyjmować nazwy lub etykiety.
Przykłady obejmują:
- Status palenia („palacz”, „niepalący”)
- Kolor oczu („niebieski”, „zielony”, „piwne”)
- Poziom wykształcenia (np. „liceum”, „licencjat”, „magister”)
Trzy powszechnie używane wykresy do wizualizacji tego typu danych to:
- Wykres słupkowy
- Działki mozaikowe
- Wykresy pudełkowe według grup
Poniższe przykłady pokazują, jak utworzyć każdy z tych wykresów w R.
Przykład 1: Wykresy słupkowe
Poniższy kod pokazuje, jak utworzyć wykres słupkowy wizualizujący częstotliwość przesunięć w określonej ramce danych:
library (ggplot2) #create data frame df <- data. frame (result = c('W', 'L', 'W', 'W', 'W', 'L', 'W', 'L', 'W', 'L'), team = c('B', 'B', 'B', 'B', 'D', 'A', 'A', 'A', 'C', 'C'), points = c(12, 28, 19, 22, 32, 45, 22, 28, 13, 19), rebounds = c(5, 7, 7, 12, 11, 4, 10, 7, 8, 8)) #create bar chart of teams ggplot(df, aes (x=team)) + geom_bar()
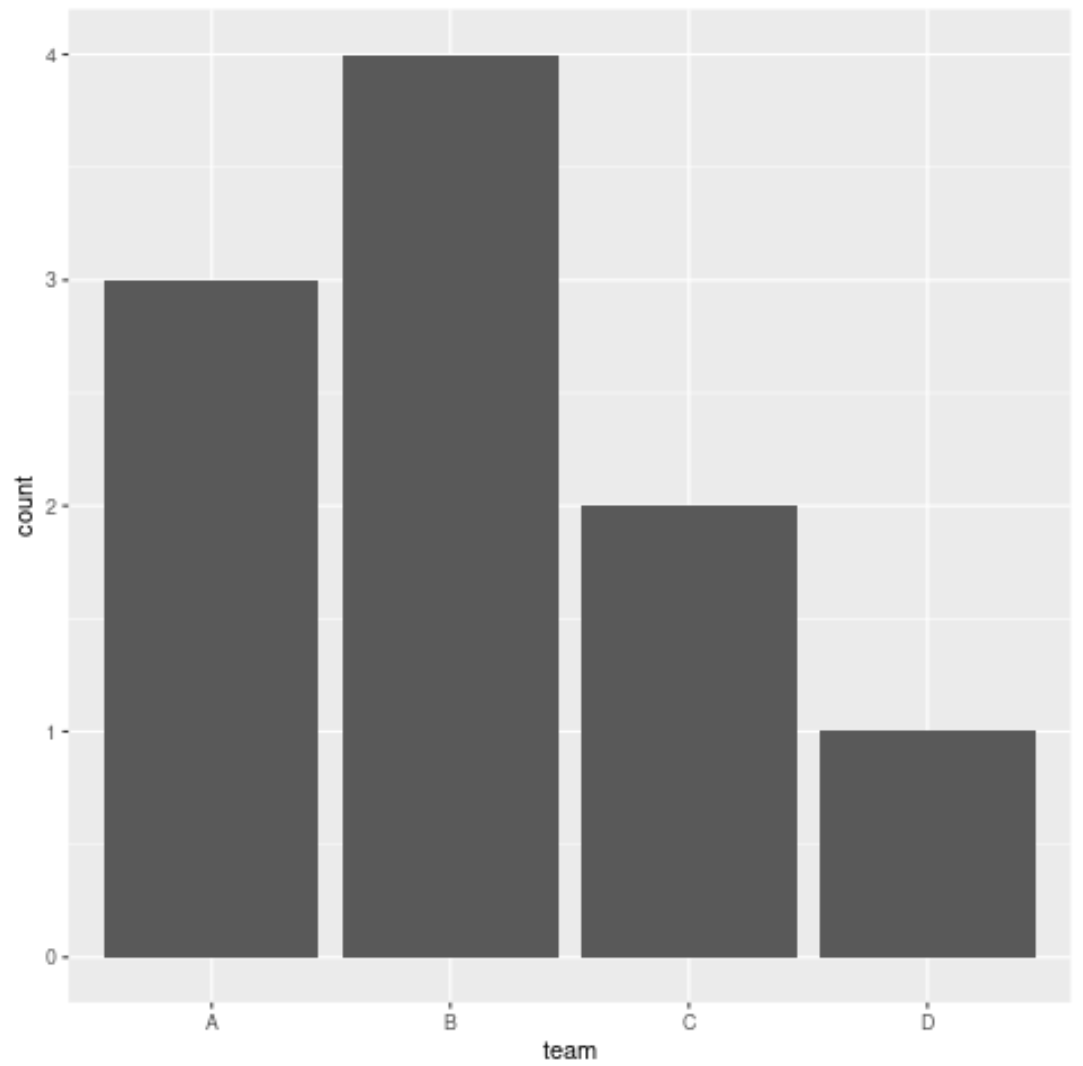
Oś x pokazuje nazwę każdego zespołu, a oś y pokazuje częstotliwość każdego zespołu w ramce danych.
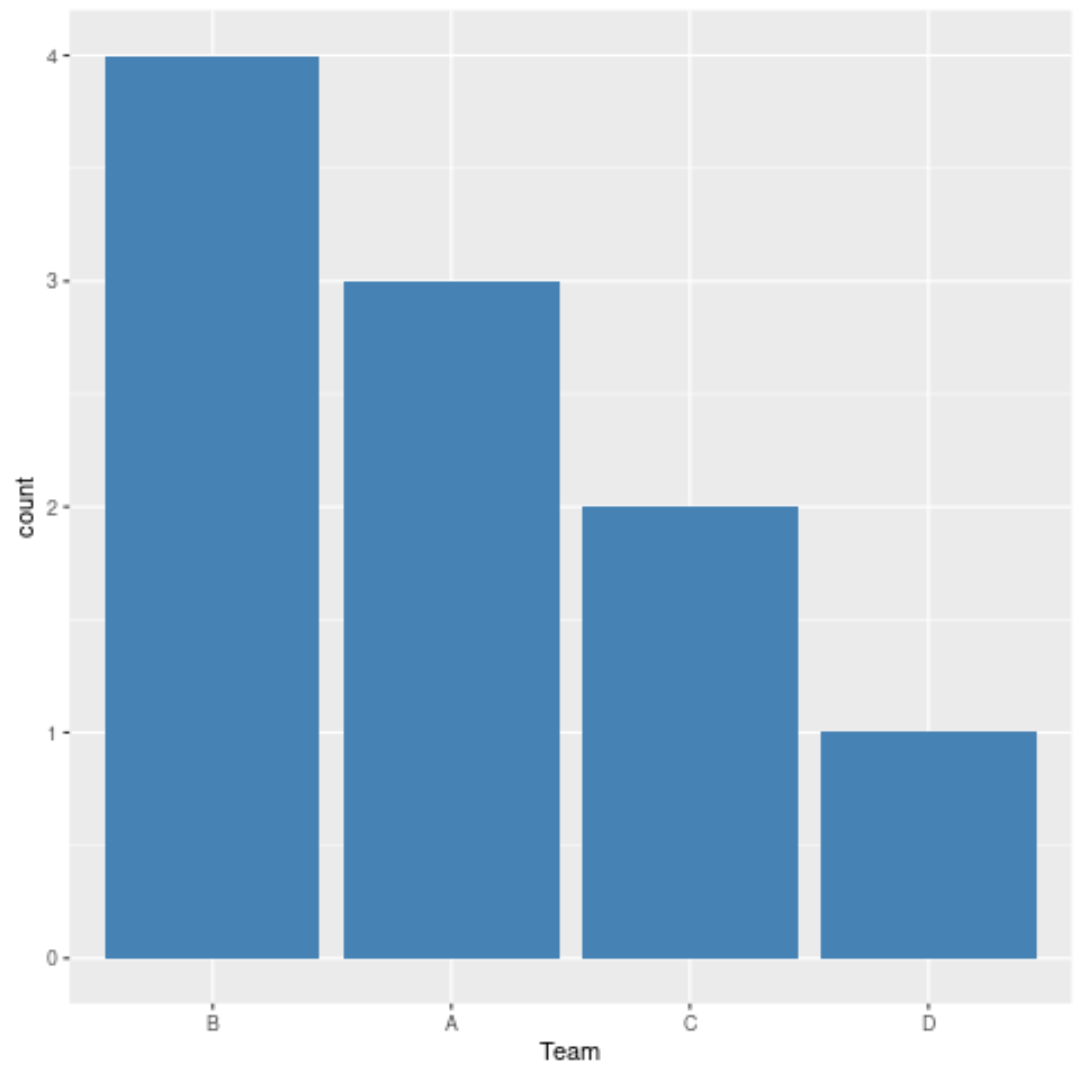
Możemy również użyć poniższego kodu, aby uporządkować słupki na wykresie od największego do najmniejszego:
#create bar chart of teams, ordered from large to small ggplot(df, aes (x= reorder (team, team, function (x)- length (x)))) + geom_bar(fill=' steelblue ') + labs(x=' Team ')
Przykład 2: Wykresy pudełkowe według grup
Skupione wykresy pudełkowe są użytecznym sposobem wizualizacji zmiennej numerycznej pogrupowanej według zmiennej jakościowej.
Na przykład poniższy kod pokazuje, jak utworzyć wykresy pudełkowe pokazujące rozkład zdobytych punktów, pogrupowane według drużyn:
library (ggplot2) #create data frame df <- data. frame (result = c('W', 'L', 'W', 'W', 'W', 'L', 'W', 'L', 'W', 'L'), team = c('B', 'B', 'B', 'B', 'D', 'A', 'A', 'A', 'C', 'C'), points = c(12, 28, 19, 22, 32, 45, 22, 28, 13, 19), rebounds = c(5, 7, 7, 12, 11, 4, 10, 7, 8, 8)) #create boxplots of points, grouped by team ggplot(df, aes (x=team, y=points)) + geom_boxplot(fill=' steelblue ')
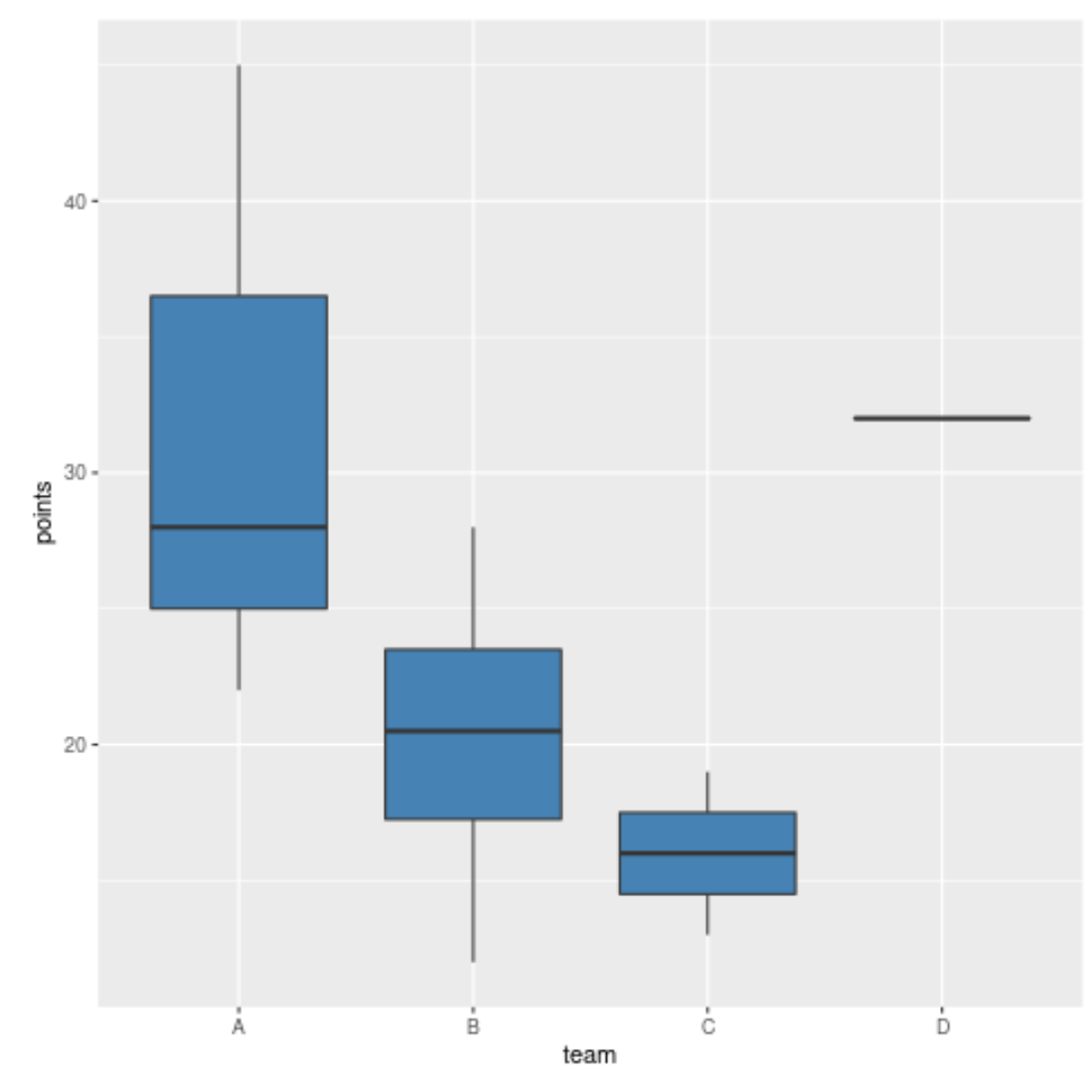
Oś x przedstawia drużyny, oś y przedstawia rozkład punktów zdobytych przez każdą drużynę.
Przykład 3: wykres mozaikowy
Wykres kafelkowy to rodzaj wykresu przedstawiający częstości występowania dwóch różnych zmiennych kategorycznych na jednym wykresie.
Na przykład poniższy kod pokazuje, jak utworzyć wykres mozaikowy przedstawiający częstotliwość występowania zmiennych kategorialnych „wynik” i „zespół” na jednym wykresie:
#create data frame df <- data. frame (result = c('W', 'L', 'W', 'W', 'W', 'L', 'W', 'L', 'W', 'L'), team = c('B', 'B', 'B', 'B', 'D', 'A', 'A', 'A', 'C', 'C'), points = c(12, 28, 19, 22, 32, 45, 22, 28, 13, 19), rebounds = c(5, 7, 7, 12, 11, 4, 10, 7, 8, 8)) #create table of counts counts <- table(df$result, df$team) #create mosaic plot mosaicplot(counts, xlab=' Game Result ', ylab=' Team ', main=' Wins by Team ', col=' steelblue ')
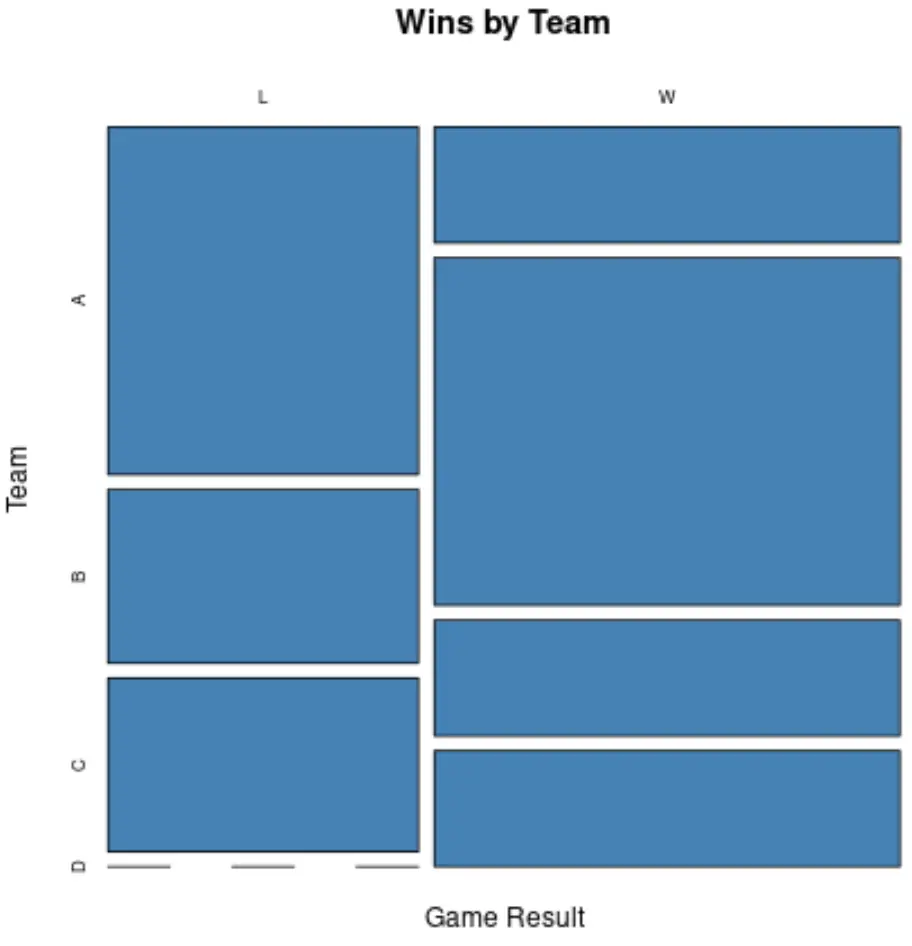
Oś x przedstawia wynik gry, a oś y przedstawia cztery różne drużyny.
Dodatkowe zasoby
Poniższe samouczki wyjaśniają, jak tworzyć inne typowe wykresy w R:
Jak utworzyć skumulowany wykres słupkowy w R
Jak utworzyć skupiony wykres słupkowy w R
Jak utworzyć skumulowany wykres punktowy w R
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej