Ciągły rozkład prawdopodobieństwa
W tym artykule wyjaśniono, czym są ciągłe rozkłady prawdopodobieństwa i do czego służą w statystyce. W ten sposób dowiesz się, co to znaczy, że rozkład prawdopodobieństwa jest ciągły, jakie są przykłady rozkładów ciągłych i jakie są różne typy rozkładów ciągłych.
Co to jest ciągły rozkład prawdopodobieństwa?
Ciągły rozkład prawdopodobieństwa to taki, którego funkcja rozkładu jest ciągła. Dlatego ciągły rozkład prawdopodobieństwa definiuje prawdopodobieństwa ciągłej zmiennej losowej .
Na przykład rozkład normalny i rozkład t-Studenta są ciągłymi rozkładami prawdopodobieństwa.
Jedną z cech ciągłych rozkładów prawdopodobieństwa jest to, że mogą przyjmować dowolną wartość w przedziale. Zatem w przeciwieństwie do dyskretnych rozkładów prawdopodobieństwa, ciągłe rozkłady prawdopodobieństwa mogą przyjmować wartości dziesiętne.
W rozkładach ciągłych, aby obliczyć prawdopodobieństwo skumulowane, należy znaleźć pole pod krzywą rozkładu, zatem w tego typu rozkładach prawdopodobieństwa funkcja skumulowanego prawdopodobieństwa jest równoważna całce z funkcji gęstości .
![\displaystyle P[X\leq x]=\int_{-\infty}^x f(x)dx](https://statorials.org/wp-content/ql-cache/quicklatex.com-4a24c53cda32a192e8dd8773df5b8ff6_l3.png "Rendered by QuickLaTeX.com")
Przykłady ciągłych rozkładów prawdopodobieństwa
Kiedy już zapoznamy się z definicją ciągłego rozkładu prawdopodobieństwa, zobaczymy kilka przykładów tego typu rozkładu, aby lepiej zrozumieć tę koncepcję.
Przykłady ciągłych rozkładów prawdopodobieństwa:
- Waga uczniów w kursie.
- Żywotność elementu elektrycznego.
- Rentowność akcji spółek notowanych na giełdzie.
- Prędkość samochodu.
- Cena niektórych akcji.
Rodzaje ciągłych rozkładów prawdopodobieństwa
Główne typy ciągłych rozkładów prawdopodobieństwa to:
- Równomierna i ciągła dystrybucja
- Normalna dystrybucja
- Rozkład lognormalny
- Rozkład chi-kwadrat
- Rozkład t-Studenta
- Dystrybucja Snedecor F
- Rozkład wykładniczy
- Dystrybucja wersji beta
- Rozkład gamma
- Dystrybucja Weibula
- Rozkład Pareto
Poniżej szczegółowo wyjaśniono każdy typ ciągłego rozkładu prawdopodobieństwa.
Równomierna i ciągła dystrybucja
Ciągły rozkład równomierny , zwany także rozkładem prostokątnym , jest rodzajem ciągłego rozkładu prawdopodobieństwa, w którym wszystkie wartości mają to samo prawdopodobieństwo wystąpienia. Innymi słowy, ciągły rozkład równomierny to rozkład, w którym prawdopodobieństwo jest równomiernie rozłożone w pewnym przedziale.
Ciągły rozkład równomierny służy do opisu zmiennych ciągłych, które mają stałe prawdopodobieństwo. Podobnie ciągły rozkład równomierny służy do definiowania procesów losowych, ponieważ jeśli wszystkie wyniki mają to samo prawdopodobieństwo, oznacza to, że wynik jest losowy.
Ciągły rozkład równomierny ma dwa charakterystyczne parametry, aib , które definiują przedział równoważnego prawdopodobieństwa. Zatem symbolem ciągłego rozkładu równomiernego jest U(a,b) , gdzie a i b są charakterystycznymi wartościami rozkładu.

Na przykład, jeśli wynik losowego eksperymentu może przyjąć dowolną wartość z zakresu od 5 do 9, a wszystkie możliwe wyniki mają to samo prawdopodobieństwo wystąpienia, eksperyment można symulować za pomocą ciągłego równomiernego rozkładu U(5,9).
Normalna dystrybucja
Rozkład normalny to ciągły rozkład prawdopodobieństwa, którego wykres ma kształt dzwonu i jest symetryczny względem średniej. W statystyce rozkład normalny służy do modelowania zjawisk o bardzo różnych charakterystykach, dlatego ten rozkład jest tak ważny.
W rzeczywistości w statystyce rozkład normalny jest zdecydowanie najważniejszym rozkładem wszystkich rozkładów prawdopodobieństwa, ponieważ nie tylko może modelować dużą liczbę zjawisk w świecie rzeczywistym, ale rozkład normalny można również wykorzystać do aproksymacji innych typów rozkładów dystrybucje. pod pewnymi warunkami.
Symbolem rozkładu normalnego jest wielka litera N. Zatem, aby wskazać, że zmienna ma rozkład normalny, jest ona oznaczona literą N, a wartości jej średniej arytmetycznej i odchylenia standardowego są dodawane w nawiasach.

Rozkład normalny ma wiele różnych nazw, w tym rozkład Gaussa , rozkład Gaussa i rozkład Laplace’a-Gaussa .
Rozkład lognormalny
Rozkład lognormalny lub rozkład lognormalny to rozkład prawdopodobieństwa definiujący zmienną losową, której logarytm ma rozkład normalny.
Zatem jeśli zmienna X ma rozkład normalny, to funkcja wykładnicza e x ma rozkład logarytmiczno-normalny.

Należy pamiętać, że rozkład lognormalny można zastosować tylko wtedy, gdy wartości zmiennej są dodatnie, ponieważ logarytm jest funkcją, która akceptuje tylko jeden dodatni argument.
Wśród różnych zastosowań rozkładu lognormalnego w statystyce wyróżniamy wykorzystanie tego rozkładu do analizy inwestycji finansowych i przeprowadzania analiz niezawodności.
Rozkład lognormalny jest również znany jako rozkład Tinauta , czasami zapisywany także jako rozkład lognormalny lub rozkład logarytmiczno-normalny .
Rozkład chi-kwadrat
Rozkład chi-kwadrat jest rozkładem prawdopodobieństwa, którego symbolem jest χ². Dokładniej, rozkład chi-kwadrat jest sumą kwadratów k niezależnych zmiennych losowych o rozkładzie normalnym.
Zatem rozkład Chi-kwadrat ma k stopni swobody. Dlatego rozkład Chi-kwadrat ma tyle stopni swobody, ile reprezentuje suma kwadratów zmiennych o rozkładzie normalnym.
![\displaystyle X\sim\chi^2_k \ \color{orange}\bm{\longrightarrow}\color{black}\ \begin{array}{l}\text{Distribuci\'on chi-cuadrado}\\[2ex]\text{con k grados de libertad}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-9ea0bf7a87071883ceae5e419bae9e71_l3.png "Rendered by QuickLaTeX.com")
Rozkład Chi-kwadrat jest również znany jako rozkład Pearsona .
Rozkład chi-kwadrat jest szeroko stosowany we wnioskowaniu statystycznym, na przykład w testowaniu hipotez i przedziałach ufności. Zobaczymy poniżej, jakie są zastosowania tego typu rozkładu prawdopodobieństwa.
Rozkład t-Studenta
Rozkład t-Studenta jest rozkładem prawdopodobieństwa szeroko stosowanym w statystyce. W szczególności rozkład t-Studenta jest używany w teście t-Studenta w celu określenia różnicy między średnimi z dwóch próbek i ustalenia przedziałów ufności.
Rozkład t-Studenta został opracowany przez statystyka Williama Sealy’ego Gosseta w 1908 roku pod pseudonimem „Student”.
Rozkład t-Studenta definiuje się jako liczbę stopni swobody otrzymaną poprzez odjęcie jednej jednostki od całkowitej liczby obserwacji. Zatem wzór na określenie stopni swobody rozkładu t-Studenta to ν=n-1 .
![\begin{array}{c}\nu=n-1\\[2ex]X\sim t_\nu\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-1c805dc2d6ca050feb70dad99de53402_l3.png "Rendered by QuickLaTeX.com")
Dystrybucja Snedecor F
Rozkład F Snedecora , zwany także rozkładem F Fishera – Snedecora lub po prostu rozkładem F , jest ciągłym rozkładem prawdopodobieństwa stosowanym we wnioskowaniu statystycznym, szczególnie w analizie wariancji.
Jedną z właściwości rozkładu Snedecora F jest to, że jest on zdefiniowany przez wartość dwóch rzeczywistych parametrów m i n , które wskazują ich stopnie swobody. Zatem symbolem rozkładu Snedecora F jest F m, n , gdzie m i n są parametrami definiującymi rozkład.
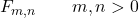
![\left.\begin{array}{c} X\sim \chi_m^2\\[2ex] Y\sim \chi_n^2\end{array}\right\}\color{orange}\bm{\longrightarrow}\color{black}\ F_{m,n}= \cfrac{X/m}{Y/n}](https://statorials.org/wp-content/ql-cache/quicklatex.com-d407869e61ca4357ffbcb40df3bd83ab_l3.png "Rendered by QuickLaTeX.com")
Rozkład Fishera-Snedecora F swoją nazwę zawdzięcza angielskiemu statystykowi Ronaldowi Fisherowi i amerykańskiemu statystykowi George’owi Snedecorowi.
W statystyce rozkład Fishera-Snedecora F ma różne zastosowania. Na przykład rozkład F Fishera-Snedecora wykorzystuje się do porównywania różnych modeli regresji liniowej, a ten rozkład prawdopodobieństwa wykorzystuje się w analizie wariancji (ANOVA).
Rozkład wykładniczy
Rozkład wykładniczy jest ciągłym rozkładem prawdopodobieństwa stosowanym do modelowania czasu oczekiwania na wystąpienie zjawiska losowego.
Dokładniej, rozkład wykładniczy umożliwia opisanie czasu oczekiwania pomiędzy dwoma zjawiskami, który jest zgodny z rozkładem Poissona. Dlatego rozkład wykładniczy jest ściśle powiązany z rozkładem Poissona.
Rozkład wykładniczy ma charakterystyczny parametr, oznaczony grecką literą λ, który wskazuje, ile razy przewidywane jest wystąpienie badanego zdarzenia w danym okresie.

Podobnie rozkład wykładniczy jest również używany do modelowania czasu do wystąpienia awarii. Dlatego rozkład wykładniczy ma kilka zastosowań w teorii niezawodności i przetrwania.
Dystrybucja wersji beta
Rozkład beta jest rozkładem prawdopodobieństwa zdefiniowanym na przedziale (0,1) i sparametryzowanym dwoma dodatnimi parametrami: α i β. Innymi słowy, wartości rozkładu beta zależą od parametrów α i β.
Dlatego rozkład beta służy do definiowania ciągłych zmiennych losowych, których wartość mieści się w przedziale od 0 do 1.
Istnieje kilka oznaczeń wskazujących, że ciągła zmienna losowa podlega rozkładowi beta. Najpopularniejsze to:
![\begin{array}{c}X\sim B(\alpha,\beta)\\[2ex]X\sim Beta(\alpha,\beta)\\[2ex]X\sim \beta_{\alpha,\beta}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-ee1d0d8a1624a017b8ef9ce8a67c694e_l3.png "Rendered by QuickLaTeX.com")
W statystykach dystrybucja beta ma bardzo różnorodne zastosowania. Na przykład rozkład beta służy do badania różnic procentowych w różnych próbkach. Podobnie w zarządzaniu projektami dystrybucja beta służy do przeprowadzania analizy Pert.
Rozkład gamma
Rozkład gamma jest ciągłym rozkładem prawdopodobieństwa zdefiniowanym przez dwa charakterystyczne parametry, α i λ. Inaczej mówiąc, rozkład gamma zależy od wartości jego dwóch parametrów: α jest parametrem kształtu, a λ jest parametrem skali.
Symbolem rozkładu gamma jest wielka grecka litera Γ. Zatem, jeśli zmienna losowa ma rozkład gamma, zapisuje się ją w następujący sposób:

Rozkład gamma można również parametryzować za pomocą parametru kształtu k = α i parametru odwrotnej skali θ = 1/λ. We wszystkich przypadkach dwa parametry definiujące rozkład gamma są dodatnimi liczbami rzeczywistymi.
Zazwyczaj rozkład gamma jest używany do modelowania zbiorów danych skośnych w prawo, dzięki czemu po lewej stronie wykresu występuje większa koncentracja danych. Na przykład rozkład gamma służy do modelowania niezawodności komponentów elektrycznych.
Dystrybucja Weibula
Rozkład Weibulla jest ciągłym rozkładem prawdopodobieństwa zdefiniowanym przez dwa charakterystyczne parametry: parametr kształtu α i parametr skali λ.
W statystyce rozkład Weibulla jest używany głównie do analizy przeżycia. Podobnie rozkład Weibulla ma wiele zastosowań w różnych dziedzinach.

Zdaniem autorów rozkład Weibulla można również parametryzować za pomocą trzech parametrów. Następnie dodawany jest trzeci parametr zwany wartością progową, który wskazuje odciętą, od której rozpoczyna się wykres rozkładu.
Rozkład Weibulla został nazwany na cześć Szweda Waloddiego Weibulla, który szczegółowo go opisał w 1951 r. Jednakże rozkład Weibulla został odkryty przez Maurice’a Frécheta w 1927 r., a po raz pierwszy zastosowany przez Rosina i Rammlera w 1933 r.
Rozkład Pareto
Rozkład Pareto to ciągły rozkład prawdopodobieństwa stosowany w statystyce do modelowania zasady Pareto. Zatem rozkład Pareto jest rozkładem prawdopodobieństwa, który ma kilka wartości, których prawdopodobieństwo wystąpienia jest znacznie większe niż pozostałych wartości.
Pamiętaj, że prawo Pareto, zwane także zasadą 80-20, jest zasadą statystyczną, która mówi, że za większość przyczyn zjawiska odpowiada niewielka część populacji.
Rozkład Pareto ma dwa charakterystyczne parametry: parametr skali x m i parametr kształtu α.

Pierwotnie rozkład Pareto był używany do opisania rozkładu bogactwa w populacji, ponieważ większość z niego wynikała z małej części populacji. Ale obecnie rozkład Pareto ma wiele zastosowań, na przykład w kontroli jakości, w ekonomii, w nauce, w obszarze społecznym itp.
Ciągły i dyskretny rozkład prawdopodobieństwa
Rozkłady prawdopodobieństwa można podzielić na rozkłady ciągłe i rozkłady dyskretne. Na koniec zobaczymy, jaka jest różnica między tymi dwoma typami rozkładów prawdopodobieństwa.
Różnica między ciągłymi rozkładami prawdopodobieństwa a dyskretnymi rozkładami prawdopodobieństwa polega na liczbie wartości, jakie mogą one przyjąć. Rozkłady ciągłe mogą przyjmować w przedziale nieskończoną liczbę wartości, natomiast rozkłady dyskretne mogą przyjmować w przedziale tylko przeliczalną liczbę wartości.
Dlatego ogólnie rzecz biorąc, jednym ze sposobów odróżnienia rozkładów ciągłych od dyskretnych jest rodzaj liczb, jakie mogą przyjmować. Zwykle rozkład ciągły może przyjmować dowolną wartość, w tym liczby dziesiętne, podczas gdy rozkłady dyskretne mogą przyjmować tylko liczby całkowite.
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej