Jak obliczyć przedział ufności dla wyrazu regresji
Prostą regresję liniową stosuje się do ilościowego określenia związku między zmienną predykcyjną a zmienną odpowiedzi.
Metoda ta znajduje wiersz, który najlepiej „pasuje” do zbioru danych i przyjmuje następującą postać:
ŷ = b 0 + b 1 x
Złoto:
- ŷ : Szacowana wartość odpowiedzi
- b 0 : Początek linii regresji
- b 1 : Nachylenie linii regresji
- x : Wartość zmiennej predykcyjnej
Często interesuje nas wartość b 1 , która mówi nam o średniej zmianiezmiennej odpowiedzi związanej ze wzrostem o jedną jednostkę zmiennej predykcyjnej.
Jednak w rzadkich przypadkach interesuje nas również wartość b0 , która mówi nam średnią wartość zmiennej odpowiedzi, gdy zmienna predykcyjna wynosi zero.
Możemy użyć poniższego wzoru do obliczenia przedziału ufności dla wartości β 0 , prawdziwej stałej populacji:
Przedział ufności dla β 0 : b 0 ± t α/2, n-2 * se(b 0 )
Poniższy przykład pokazuje, jak w praktyce obliczyć przedział ufności dla wyrazu wolnego.
Przykład: Przedział ufności dla punktu przecięcia regresji
Załóżmy, że chcemy dopasować prosty model regresji liniowej, wykorzystując przestudiowane godziny jako zmienną predykcyjną i wyniki egzaminów jako zmienną odpowiedzi dla 15 uczniów w określonej klasie:
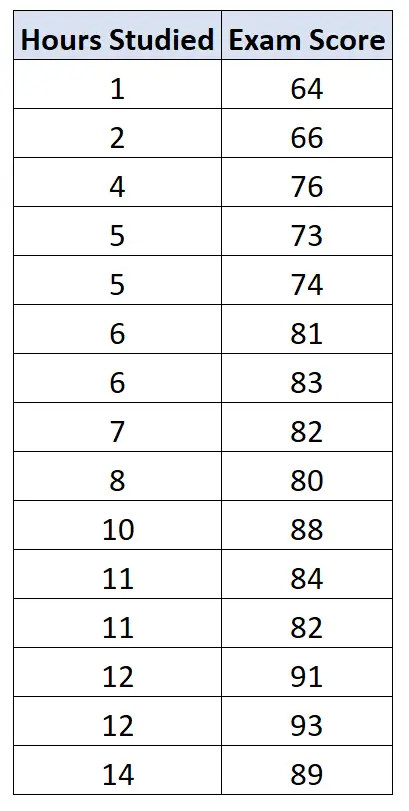
Poniższy kod pokazuje, jak dopasować ten prosty model regresji liniowej w R:
#create data frame df <- data. frame (hours=c(1, 2, 4, 5, 5, 6, 6, 7, 8, 10, 11, 11, 12, 12, 14), score=c(64, 66, 76, 73, 74, 81, 83, 82, 80, 88, 84, 82, 91, 93, 89)) #fit simple linear regression model fit <- lm(score ~ hours, data=df) #view summary of model summary(fit) Call: lm(formula = score ~ hours, data = df) Residuals: Min 1Q Median 3Q Max -5,140 -3,219 -1,193 2,816 5,772 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 65,334 2,106 31,023 1.41e-13 *** hours 1.982 0.248 7.995 2.25e-06 *** --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.641 on 13 degrees of freedom Multiple R-squared: 0.831, Adjusted R-squared: 0.818 F-statistic: 63.91 on 1 and 13 DF, p-value: 2.253e-06
Korzystając z oszacowań współczynników w wyniku, możemy napisać dopasowany prosty model regresji liniowej w następujący sposób:
Wynik = 65,334 + 1,982*(Godziny nauki)
Wartość przecięcia wynosi 65,334. To mówi nam, że szacowany średni wynik egzaminu dla studenta studiującego zero godzin wynosi 65 334 .
Możemy użyć następującego wzoru do obliczenia 95% przedziału ufności dla wyrazu wolnego:
- 95% CI dla β 0 : b 0 ± t α/2, n-2 * se(b 0 )
- 95% CI dla β 0 : 65,334 ± t 0,05/2,15-2 * 2,106
- 95% CI dla β 0 : 65,334 ± 2,1604 * 2,106
- 95% CI dla β 0 : [60,78, 69,88]
Interpretujemy to w ten sposób, że mamy 95% pewności, że rzeczywisty średni wynik egzaminu uczniów studiujących zero godzin mieści się w przedziale od 60,78 do 69,88.
Uwaga : Użyliśmy kalkulatora odwrotnego rozkładu t, aby znaleźć krytyczną wartość t, która odpowiada 95% poziomowi ufności z 13 stopniami swobody.
Środki ostrożności dotyczące obliczania przedziału ufności dla wyrazu wolnego regresji
W praktyce często nie obliczamy przedziału ufności dla wyrazu wolnego regresji, ponieważ zazwyczaj nie ma sensu interpretować wartości wyrazu wolnego w regresji modelu.
Załóżmy na przykład, że dopasowujemy model regresji, który wykorzystuje wzrost koszykarza jako zmienną predykcyjną i średnią punktów na mecz jako zmienną odpowiedzi.
Nie jest możliwe, aby zawodnik miał zero stóp wzrostu, więc nie ma sensu dosłownie interpretować przechwytu w tym modelu.
Istnieje niezliczona ilość takich scenariuszy, w których zmienna predykcyjna nie może przyjąć wartości zero. Zatem nie ma sensu interpretować pierwotnej wartości modelu ani tworzyć przedziału ufności dla początku.
Rozważmy na przykład następujące potencjalne zmienne predykcyjne w modelu:
- Powierzchnia domu
- Długość samochodu
- Waga osoby
Żadna z tych zmiennych predykcyjnych nie może przyjąć wartości zero. Dlatego w żadnej z tych okoliczności obliczanie przedziału ufności dla początku modelu regresji nie miałoby sensu.
Dodatkowe zasoby
Poniższe samouczki zawierają dodatkowe informacje na temat regresji liniowej:
Wprowadzenie do prostej regresji liniowej
Wprowadzenie do wielokrotnej regresji liniowej
Jak czytać i interpretować tabelę regresji
Jak raportować wyniki regresji
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej