Dystrybucja próbek
W tym artykule wyjaśniono, czym jest rozkład próbkowania w statystyce i do czego się go używa. W ten sposób znajdziesz znaczenie rozkładu próbkowania, konkretny przykład rozkładu próbkowania, a ponadto wzory na najczęstsze typy rozkładów próbkowania.
Jaki jest rozkład próbkowania?
Rozkład próbkowania lub rozkład próbkowania to rozkład wynikający z uwzględnienia wszystkich możliwych próbek z populacji. Innymi słowy, rozkład próbkowania to rozkład uzyskany poprzez obliczenie parametru próbkowania wszystkich możliwych próbek z populacji.
Na przykład, jeśli wyodrębnimy wszystkie możliwe próbki z populacji statystycznej i obliczymy średnią każdej próbki, zbiór średnich z próby tworzy rozkład próbkowania. Dokładniej, ponieważ obliczony parametr jest średnią arytmetyczną, jest to rozkład średniej z próbkowania.
W statystyce rozkład próbkowania służy do obliczenia prawdopodobieństwa zbliżenia się do wartości parametru populacji podczas badania pojedynczej próby. Podobnie rozkład próbkowania pozwala oszacować błąd próbkowania dla danej liczebności próby.
Przykład rozkładu próbkowania
Teraz, gdy znamy definicję rozkładu próbkowania, spójrzmy na prosty przykład, aby w pełni zrozumieć tę koncepcję.
- Do pudełka wkładamy trzy kule i na każdej z nich zapisana jest liczba od 1 do 3, tak aby jedna kula miała numer 1, druga kula miała numer 2, a ostatnia kula miała numer 3. Dla próbki o rozmiarze n = 2, oblicza prawdopodobieństwa rozkładu średniej w przypadku wybrania próbek z zastępowaniem.
Próbki wybierane są z wymianą, czyli kula zebrana w celu wybrania pierwszego elementu próbki wraca do pudełka i może zostać ponownie wybrana podczas drugiej ekstrakcji. Dlatego wszystkie możliwe próbki z populacji to:
1,1 1,2 1,3
2.1 2.2 2.3
3.1 3.2 3.3
W ten sposób obliczamy średnią arytmetyczną każdej możliwej próbki:









Zatem prawdopodobieństwa uzyskania każdej wartości średniej próby przy wyborze próby losowej z populacji są następujące:
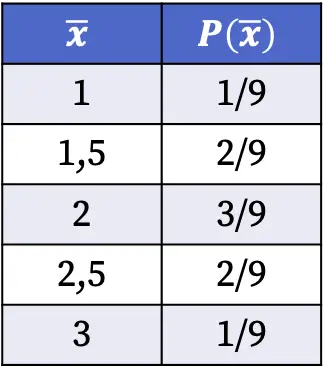
Prawdopodobieństwa rozkładu próbkowania pokazane w powyższej tabeli obliczono dzieląc liczbę próbek posiadających wspomnianą wartość średnią przez całkowitą liczbę możliwych przypadków. Na przykład: średnia próbki wynosi 1,5 w dwóch przypadkach na dziewięć możliwych, zatem P(1,5)=2/9.
Rodzaje rozkładów próbkowania
Rozkłady próbkowania (lub rozkłady próbkowania) można klasyfikować na podstawie parametru próbkowania, z którego zostały uzyskane. Zatem najczęstsze typy dystrybucji są następujące:
- Rozkład średniej próby : Jest to rozkład próby wynikający z obliczenia średniej arytmetycznej każdej próbki.
- Proporcjonalny rozkład próbkowania : Jest to rozkład próbkowania uzyskany poprzez obliczenie proporcji wszystkich próbek.
- Rozkład wariancji próbkowania : jest to rozkład próbkowania, który tworzy zbiór wszystkich wariancji w próbie.
- Różnica rozkładu średnich prób z dwóch różnych populacji.
- Różnica w proporcjonalnym rozkładzie próbkowania : jest rozkładem próbkowania uzyskanym przez odjęcie wszystkich możliwych proporcji próbkowania z dwóch populacji.
Każdy rodzaj rozkładu próbkowania wyjaśniono bardziej szczegółowo poniżej.
Próbkowanie rozkładu średniej
Biorąc pod uwagę populację, która ma normalny rozkład prawdopodobieństwa ze średnią

i odchylenie standardowe

i pobierane są próbki wielkości

, rozkład średniej próby będzie również określony rozkładem normalnym mającym następujące cechy:
![\begin{array}{c}\mu_{\overline{x}}=\mu \qquad \sigma_{\overline{x}}=\cfrac{\sigma}{\sqrt{n}}\\[4ex]\displaystyle N_{\overline{x}}\left(\mu, \frac{\sigma}{\sqrt{n}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-44571aa7337b095ab9c9fa1f746e93a5_l3.png "Rendered by QuickLaTeX.com")
Złoto

jest średnią rozkładu próby średniej i

jest jego odchyleniem standardowym. Ponadto,

jest błędem standardowym rozkładu próbkowania.
Uwaga: Jeżeli populacja nie ma rozkładu normalnego, ale wielkość próby jest duża (n>30), rozkład średniej próby można również przybliżyć do powyższego rozkładu normalnego za pomocą granicy centralnego twierdzenia.
Dlatego też, ponieważ rozkład średniej z próby ma rozkład normalny, wzór na obliczenie prawdopodobieństwa związanego ze średnią z próbki jest następujący:

Złoto:
-

to przykładowe środki.
-
To jest średnia populacji.
-

jest odchyleniem standardowym populacji.
-
to wielkość próbki.
-

jest zmienną zdefiniowaną przez standardowy rozkład normalny N(0,1).
Próbkowanie rozkładu proporcji
Tak naprawdę, badając część próby, analizujemy przypadki sukcesu. Dlatego zmienna losowa w badaniu ma dwumianowy rozkład prawdopodobieństwa.
Zgodnie z centralnym twierdzeniem granicznym, dla dużych rozmiarów (n>30) możemy przybliżyć rozkład dwumianowy do rozkładu normalnego. Dlatego rozkład próbkowania proporcji jest zbliżony do rozkładu normalnego z następującymi parametrami:
![\begin{array}{c}\displaystyle\mu_{p}=p \qquad \sigma_{p}=\sqrt{\frac{pq}{n}}\\[4ex]\displaystyle N_{p}\left(p, \sqrt{\frac{pq}{n}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-f3408076893f390bb65baecfe38e6eff_l3.png "Rendered by QuickLaTeX.com")
Złoto

jest prawdopodobieństwem sukcesu i

jest prawdopodobieństwo niepowodzenia

.
Uwaga: Rozkład dwumianowy można przybliżyć do rozkładu normalnego tylko wtedy, gdy:


I

.
Ponieważ zatem rozkład próbkowania tej proporcji można przybliżyć do rozkładu normalnego, wzór na obliczenie prawdopodobieństwa związanego z proporcją próbki jest następujący:

Złoto:
-

jest proporcją próbki.
-
jest odsetek populacji.
-
jest prawdopodobieństwem niepowodzenia populacji,
.
-
to wielkość próbki.
-
jest zmienną zdefiniowaną przez standardowy rozkład normalny N(0,1).
Próbkowanie Rozkład wariancji
Rozkład wariancji próbkowania jest zdefiniowany przez rozkład prawdopodobieństwa chi-kwadrat. Dlatego wzór na statystykę rozkładu wariancji z próby jest następujący:

Złoto:
-

jest statystyką rozkładu wariancji z próbkowania, która jest zgodna z rozkładem chi-kwadrat.
-
to wielkość próbki.
-

jest wariancją próbki.
-

jest wariancją populacji.
Próbkowanie rozkładu różnicy średnich
Jeżeli wielkość próby jest wystarczająco duża (n 1 ≥30 i n 2 ≥30), rozkład średniej różnicy w próbce jest zgodny z rozkładem normalnym. Dokładniej, parametry wspomnianego rozkładu oblicza się w następujący sposób:
![\begin{array}{c}\displaystyle \mu_{\overline{x_1}-\overline{x_2}}=\mu_1-\mu_2 \qquad \sigma_{\overline{x_1}-\overline{x_2}}=\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}\\[6ex]\displaystyle N_{\overline{x_1}-\overline{x_2}}\left(\mu_1-\mu_2, \sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-90c67b74b4e9326b7869d641a59725d9_l3.png "Rendered by QuickLaTeX.com")
Uwaga: Jeżeli obie populacje mają rozkłady normalne, wówczas rozkład różnicy średnich w próbce jest zgodny z rozkładem normalnym niezależnie od wielkości próby.
Dlatego też, ponieważ rozkład próbkowania różnicy średnich jest określony przez rozkład normalny, wzór na obliczenie statystyki rozkładu próbkowania różnicy średnich jest następujący:

Złoto:
-

jest średnią próbki i.
-

jest średnią populacji, tj.
-

jest odchyleniem standardowym populacji, tj.
-

to wielkość próbki, tj.
-
jest zmienną zdefiniowaną przez standardowy rozkład normalny N(0,1).
Należy pamiętać, że próbki z różnych populacji mogą mieć różną wielkość próby.
Próbkowanie rozkładu różnicy proporcji
Próby wybrane do różnicy proporcji rozkładu próbkowania są definiowane przez rozkłady dwumianowe, ponieważ dla celów praktycznych proporcja jest stosunkiem przypadków zakończonych sukcesem do całkowitej liczby obserwacji.
Jednakże, dzięki centralnemu twierdzeniu granicznemu, rozkłady dwumianowe można aproksymować do normalnych rozkładów prawdopodobieństwa. Dlatego rozkład próbkowania różnicy proporcji można przybliżyć do rozkładu normalnego o następujących cechach:
![\begin{array}{c}\displaystyle\mu_{\widehat{p_1}-\widehat{p_2}}=p_1-p_2 \qquad \sigma_{\widehat{p_1}-\widehat{p_2}}=\sqrt{\frac{p_1q_1}{n_1}+\frac{p_2q_2}{n_2}}\\[6ex]\displaystyle N_{p}\left(p_1-p_2, \sqrt{\frac{p_1q_1}{n_1}+\frac{p_2q_2}{n_2}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-a1ce359b5dd6d80f8d27b0b9a1034bed_l3.png "Rendered by QuickLaTeX.com")
Uwaga: Rozkład próbkowania różnicy proporcji można przybliżyć do rozkładu normalnego tylko wtedy, gdy:

,

,

,

,

I

.
Ponieważ zatem rozkład próbkowania różnicy proporcji można przybliżyć do rozkładu normalnego, wzór na obliczenie statystyki rozkładu próbkowania różnicy proporcji jest następujący:

Złoto:
-

jest proporcją próbki, tj.
-

to odsetek populacji, tj.
-

jest prawdopodobieństwem niepowodzenia populacji i,

.
-
to wielkość próbki, tj.
-
jest zmienną zdefiniowaną przez standardowy rozkład normalny N(0,1).
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej