Jak przeprowadzić analizę jednowymiarową w pythonie: z przykładami
Termin analiza jednowymiarowa odnosi się do analizy jednej zmiennej. Możesz to zapamiętać, ponieważ przedrostek „uni” oznacza „jeden”.
Istnieją trzy popularne sposoby przeprowadzania analizy jednowymiarowej zmiennej:
1. Statystyka podsumowująca – mierzy środek i rozkład wartości.
2. Tabela częstotliwości – opisuje, jak często pojawiają się różne wartości.
3. Wykresy – służą do wizualizacji rozkładu wartości.
W tym samouczku przedstawiono przykład przeprowadzania analizy jednowymiarowej przy użyciu następującej ramki DataFrame pand:
import pandas as pd #createDataFrame df = pd. DataFrame ({' points ': [1, 1, 2, 3.5, 4, 4, 4, 5, 5, 6.5, 7, 7.4, 8, 13, 14.2], ' assists ': [5, 7, 7, 9, 12, 9, 9, 4, 6, 8, 8, 9, 3, 2, 6], ' rebounds ': [11, 8, 10, 6, 6, 5, 9, 12, 6, 6, 7, 8, 7, 9, 15]}) #view first five rows of DataFrame df. head () points assists rebounds 0 1.0 5 11 1 1.0 7 8 2 2.0 7 10 3 3.5 9 6 4 4.0 12 6
1. Oblicz statystyki podsumowujące
Możemy użyć następującej składni do obliczenia różnych statystyk podsumowujących dla zmiennej „punkty” w ramce DataFrame:
#calculate mean of 'points' df[' points ']. mean () 5.706666666666667 #calculate median of 'points' df[' points ']. median () 5.0 #calculate standard deviation of 'points' df[' points ']. std () 3.858287308169384
2. Utwórz tabelę częstości
Możemy użyć następującej składni, aby utworzyć tabelę częstości dla zmiennej „punkty”:
#create frequency table for 'points' df[' points ']. value_counts () 4.0 3 1.0 2 5.0 2 2.0 1 3.5 1 6.5 1 7.0 1 7.4 1 8.0 1 13.0 1 14.2 1 Name: points, dtype: int64
To mówi nam, że:
- Wartość 4 pojawia się 3 razy
- Wartość 1 pojawia się dwukrotnie
- Wartość 5 pojawia się dwukrotnie
- Wartość 2 pojawia się 1 raz
I tak dalej.
Powiązane: Jak tworzyć tabele częstotliwości w Pythonie
3. Utwórz wykresy
Możemy użyć następującej składni, aby utworzyć wykres pudełkowy dla zmiennej „punkty”:
import matplotlib. pyplot as plt df. boxplot (column=[' points '], grid= False , color=' black ')
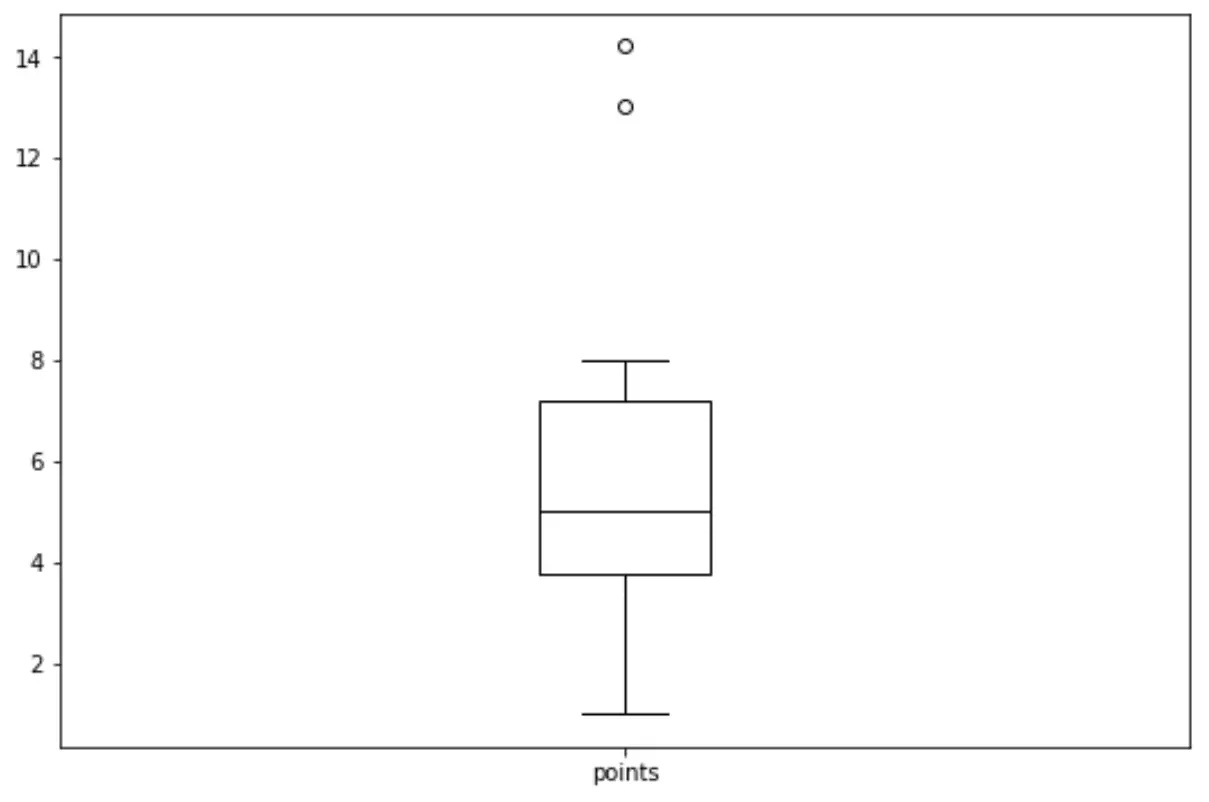
Powiązane: Jak utworzyć wykres pudełkowy z ramki danych Pandas
Możemy użyć następującej składni, aby utworzyć histogram dla zmiennej „punkty”:
import matplotlib. pyplot as plt df. hist (column=' points ', grid= False , edgecolor=' black ')
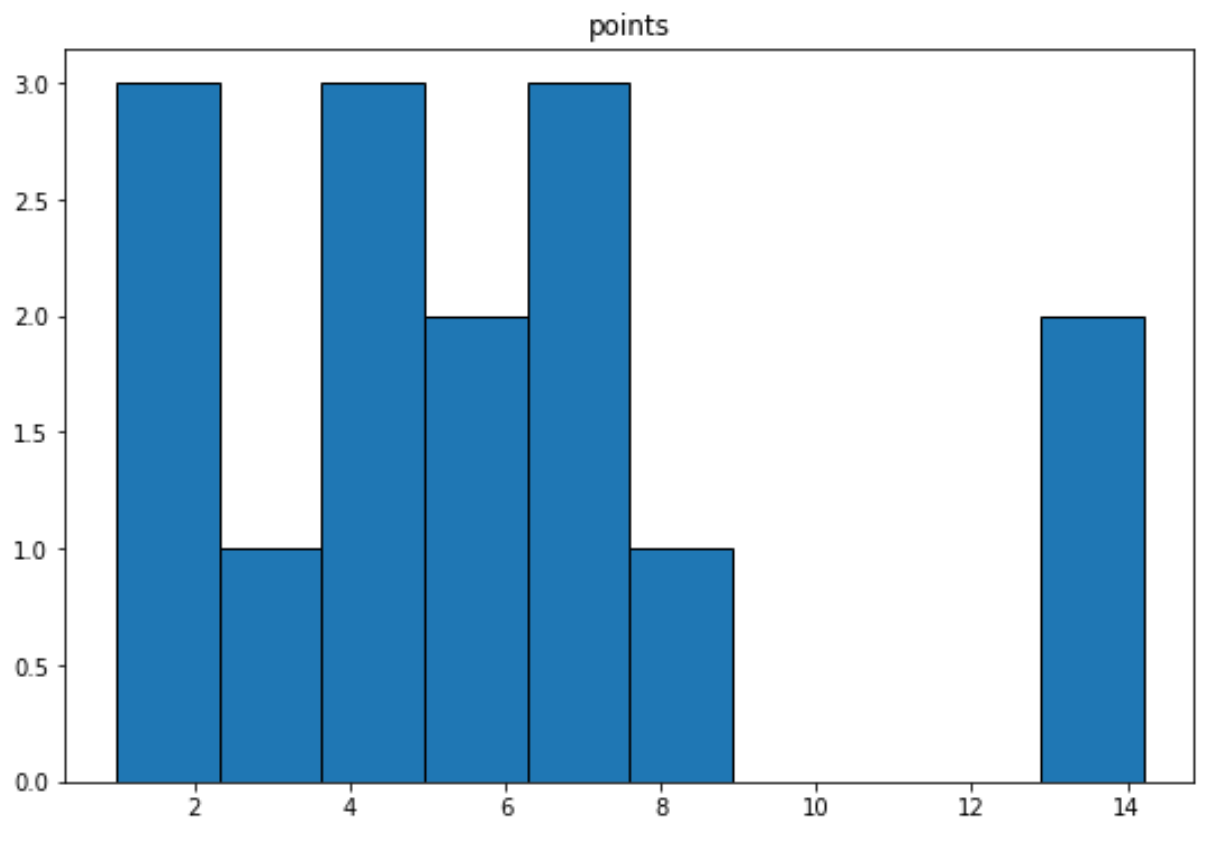
Powiązane: Jak utworzyć histogram z ramki danych Pandas
Możemy użyć następującej składni, aby utworzyć krzywą gęstości dla zmiennej „punkty”:
import seaborn as sns sns. kdeplot (df[' points '])
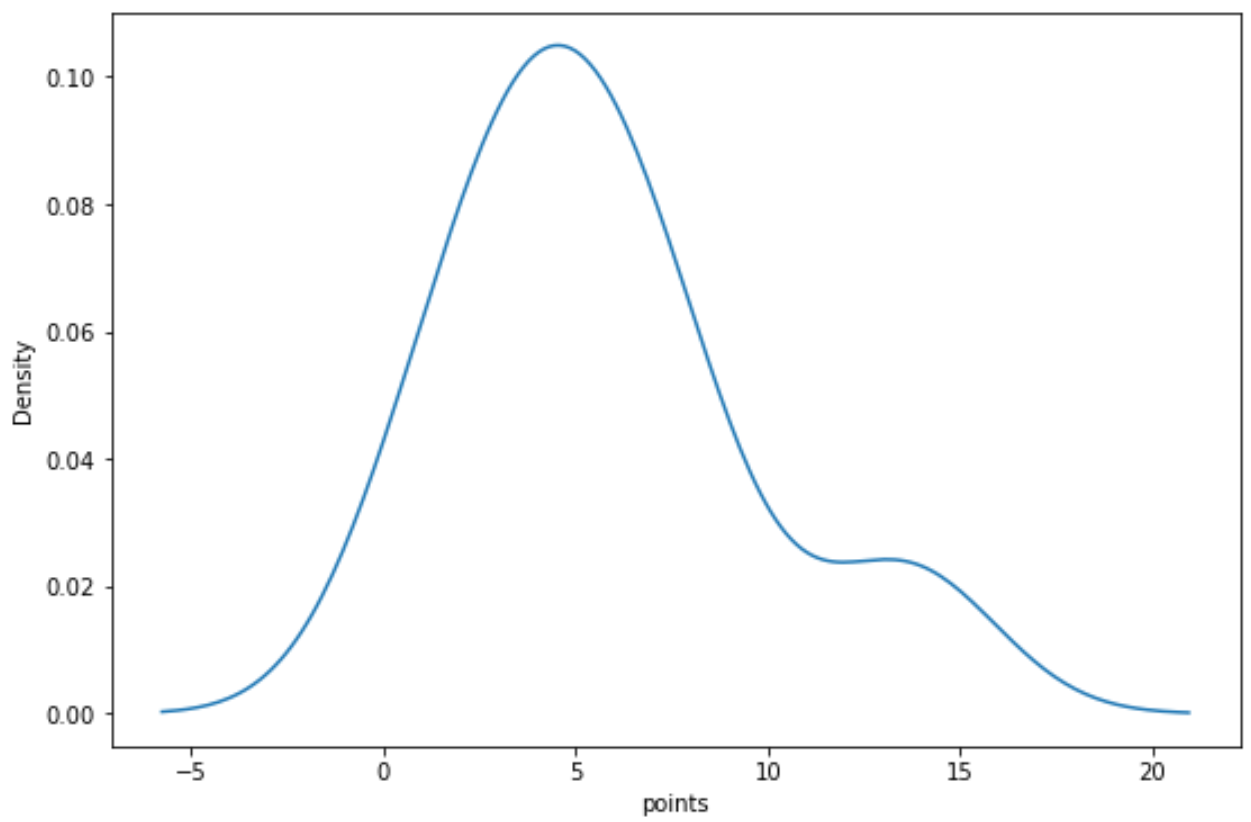
Powiązane: Jak utworzyć wykres gęstości w Matplotlib
Każdy z tych wykresów daje nam unikalny sposób wizualizacji rozkładu wartości zmiennej „punkty”.
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej