Sas: jak połączyć zbiory danych w oparciu o dwie zmienne
Możesz użyć poniższej podstawowej składni, aby połączyć dwa zbiory danych w SAS-ie na podstawie dopasowania dwóch zmiennych:
data final_data;
merge data1(in=a) data2(in=b);
by ID Store;
if a and b;
run ;
W tym konkretnym przykładzie zestawy danych zwane data1 i data2 są łączone w oparciu o zmienne zwane ID i Store i zwracane są tylko te wiersze, w których w obu zestawach danych istnieje wartość.
Poniższy przykład pokazuje, jak zastosować tę składnię w praktyce.
Przykład: Scal zestawy danych w SAS-ie na podstawie dwóch zmiennych
Załóżmy, że mamy następujący zbiór danych w SAS-ie, który zawiera informacje o sprzedawcach firmy:
/*create first dataset*/
data data1;
inputStoreID $;
datalines ;
1A
1B
1 C
2A
2C
3A
3 B
;
run ;
/*view first dataset*/
title "data1";
proc print data = data1;
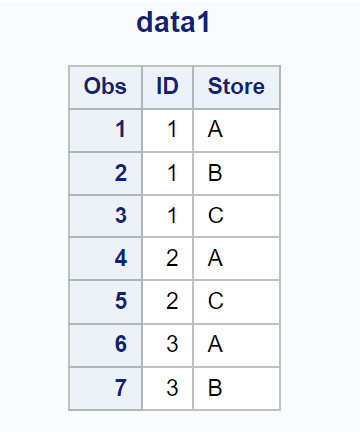
Załóżmy, że mamy inny zbiór danych zawierający informacje o sprzedaży dokonanej w różnych sklepach przez każdego współpracownika:
/*create second dataset*/
data data2;
input Store ID $Sales;
datalines ;
1 to 22
1 B 25
2 to 40
2 B 24
2 C 29
3 to 12
3 B 15
;
run ;
/*view second dataset*/
title "data2";
proc print data = data2;
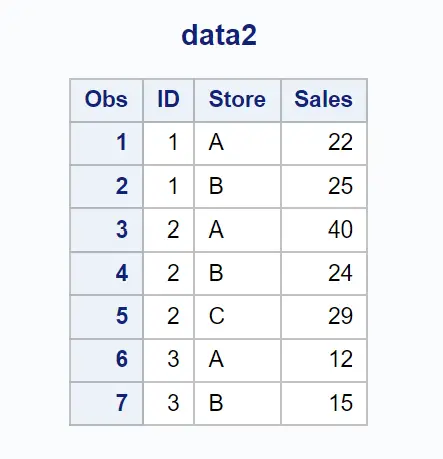
Możemy użyć poniższej instrukcji merge , aby połączyć dwa zbiory danych na podstawie pasujących wartości w kolumnach ID i Store , a następnie zwrócić tylko te wiersze, w których wartość istnieje w obu kolumnach:
/*perform merge*/
data final_data;
merge data1(in=a) data2(in=b);
by ID Store;
if a and b;
run ;
/*view results*/
title "final_data";
proc print data =final_data;
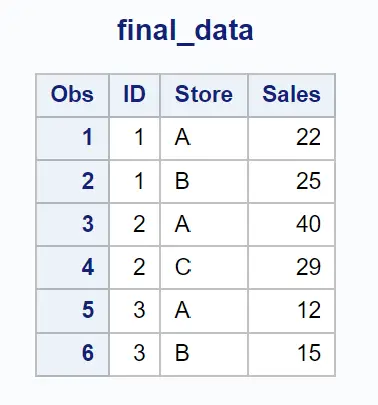
Wynikowy zbiór danych zwraca wiersze, w których wartości kolumn ID i Store są zgodne.
Uwaga : Pełną dokumentację instrukcji scalania SAS-owej znajdziesz tutaj .
Dodatkowe zasoby
Poniższe samouczki wyjaśniają, jak wykonywać inne typowe zadania w SAS-ie:
SAS: Jak wykonać połączenie jeden do wielu
SAS: Jak używać (in=a) w instrukcji scalania
SAS: Jak połączyć, jeśli A nie jest B
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej