Drzewo decyzyjne a lasy losowe: jaka jest różnica?
Drzewo decyzyjne to rodzaj modelu uczenia maszynowego stosowanego, gdy relacja między zestawem zmiennych predykcyjnych a zmienną odpowiedzi jest nieliniowa.
Podstawową ideą drzewa decyzyjnego jest skonstruowanie „drzewa” przy użyciu zestawu zmiennych predykcyjnych, które przewiduje wartość zmiennej odpowiedzi przy użyciu reguł decyzyjnych.
Na przykład moglibyśmy użyć zmiennych predykcyjnych „lata gry” i „średnia liczba home runów”, aby przewidzieć roczne wynagrodzenie zawodowych graczy w baseball.
Korzystając z tego zbioru danych, model drzewa decyzyjnego mógłby wyglądać tak:
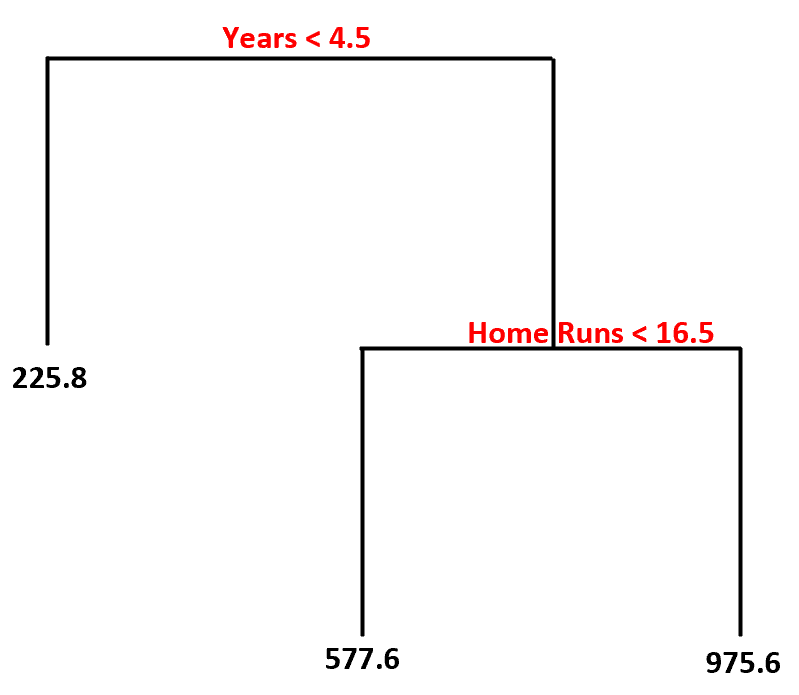
Oto jak interpretowalibyśmy to drzewo decyzyjne:
- Gracze, którzy grają krócej niż 4,5 roku, mają przewidywaną pensję na poziomie 225,8 tys. dolarów .
- Gracze, którzy grali dłużej niż 4,5 roku lub dłużej i średnio mieli mniej niż 16,5 home runów, mają przewidywaną pensję w wysokości 577,6 tys. dolarów .
- Gracze z co najmniej 4,5-letnim doświadczeniem i średnio 16,5 lub więcej home runami mają oczekiwaną pensję w wysokości 975,6 tys. dolarów .
Główną zaletą drzewa decyzyjnego jest to, że można je szybko dostosować do zbioru danych, a ostateczny model można wyraźnie zwizualizować i zinterpretować za pomocą diagramu „drzewa”, takiego jak ten powyżej.
Główną wadą jest to, że drzewo decyzyjne ma tendencję do nadmiernego dopasowania zbioru danych szkoleniowych, co oznacza, że prawdopodobnie będzie słabo działać na niewidocznych danych. Duży wpływ na to mogą mieć także wartości odstające w zbiorze danych.
Rozszerzeniem drzewa decyzyjnego jest model znany jako las losowy , który w istocie jest zbiorem drzew decyzyjnych.
Oto kroki, których używamy do utworzenia losowego modelu lasu:
1. Pobierz próbki bootstrap z oryginalnego zbioru danych.
2. Dla każdej próbki bootstrap utwórz drzewo decyzyjne, korzystając z losowego podzbioru zmiennych predykcyjnych.
3. Uśrednij przewidywania z każdego drzewa, aby otrzymać ostateczny model.
Zaletą lasów losowych jest to, że na niewidocznych danych zwykle działają znacznie lepiej niż drzewa decyzyjne i są mniej podatne na wartości odstające.
Wadą losowych lasów jest to, że nie ma możliwości wizualizacji ostatecznego modelu, a ich budowanie może zająć dużo czasu, jeśli nie masz wystarczającej mocy obliczeniowej lub zbiór danych, z którym pracujesz, jest bardzo obszerny.
Zalety i wady: drzewa decyzyjne vs. Losowe lasy
Poniższa tabela podsumowuje zalety i wady drzew decyzyjnych w porównaniu z lasami losowymi:
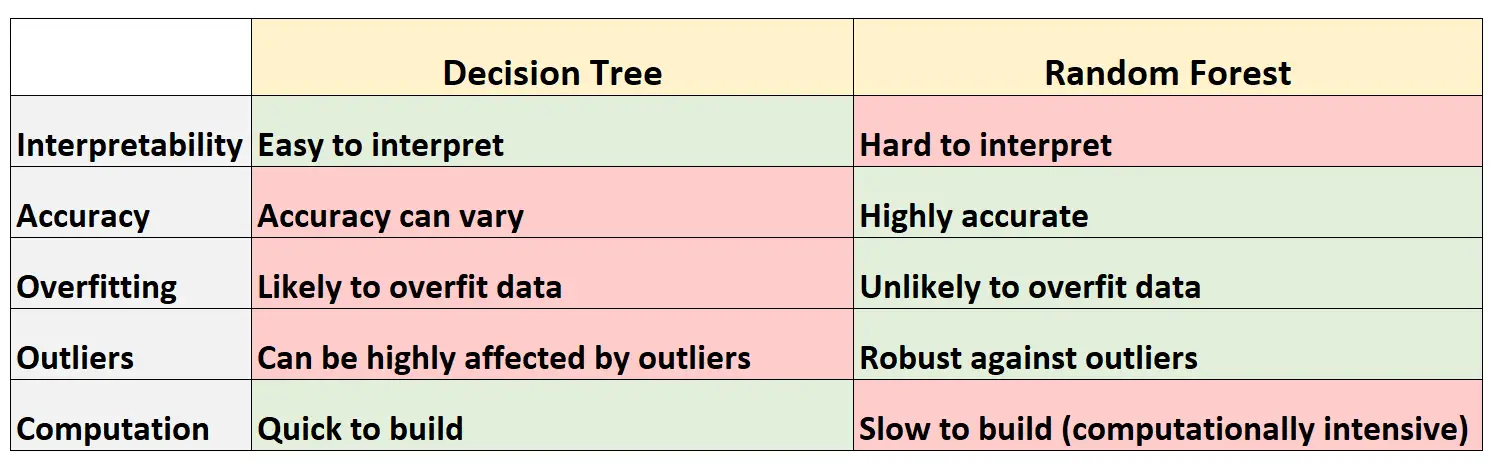
Oto krótkie wyjaśnienie każdego wiersza w tabeli:
1. Interpretowalność
Drzewa decyzyjne są łatwe do interpretacji, ponieważ możemy utworzyć diagram drzewa w celu wizualizacji i zrozumienia ostatecznego modelu.
I odwrotnie, nie możemy wizualizować losowego lasu i często może być trudno zrozumieć, w jaki sposób ostateczny model losowego lasu podejmuje decyzje.
2. Dokładność
Ponieważ drzewa decyzyjne prawdopodobnie nadmiernie dopasowują się do zbioru danych szkoleniowych, zwykle działają gorzej w przypadku niewidocznych zbiorów danych.
I odwrotnie, lasy losowe są zwykle bardzo dokładne w przypadku niewidocznych zbiorów danych, ponieważ pozwalają uniknąć nadmiernego dopasowania zbiorów danych szkoleniowych.
3. Nadmierne dopasowanie
Jak wspomniano wcześniej, drzewa decyzyjne często nadmiernie dopasowują się do danych szkoleniowych: oznacza to, że prawdopodobnie dostosują się do „szumu” zbioru danych, w przeciwieństwie do prawdziwego modelu bazowego.
I odwrotnie, ponieważ lasy losowe wykorzystują tylko pewne zmienne predykcyjne do konstruowania każdego indywidualnego drzewa decyzyjnego, ostateczne drzewa są zwykle dekorowane, co oznacza, że jest mało prawdopodobne, aby modele lasów losowych przekształciły zbiory danych.
4. Wartości odstające
Drzewa decyzyjne są bardzo podatne na wpływ wartości odstających.
I odwrotnie, ponieważ losowy model lasu buduje wiele indywidualnych drzew decyzyjnych, a następnie pobiera średnią z przewidywań z tych drzew, znacznie mniej prawdopodobne jest, że będą miały na niego wpływ wartości odstające.
5. Obliczenia
Drzewa decyzyjne można szybko dostosować do zbiorów danych.
Z drugiej strony losowe lasy wymagają znacznie większej mocy obliczeniowej, a ich utworzenie może zająć dużo czasu, w zależności od rozmiaru zbioru danych.
Kiedy używać drzew decyzyjnych lub lasów losowych
Ogólnie:
Jeśli chcesz szybko stworzyć model nieliniowy i móc łatwo zinterpretować sposób, w jaki model podejmuje decyzje, powinieneś skorzystać z drzewa decyzyjnego .
Jeśli jednak dysponujesz dużą mocą obliczeniową i chcesz utworzyć model, który prawdopodobnie będzie bardzo dokładny, nie martwiąc się o to, jak go zinterpretować, powinieneś użyć lasu losowego.
W prawdziwym świecie inżynierowie zajmujący się uczeniem maszynowym i badacze danych często korzystają z lasów losowych, ponieważ są one bardzo dokładne, a nowoczesne komputery i systemy często radzą sobie z dużymi zbiorami danych, z którymi wcześniej nie można było sobie poradzić.
Dodatkowe zasoby
Poniższe samouczki stanowią wprowadzenie do drzew decyzyjnych i modeli lasów losowych:
Poniższe samouczki wyjaśniają, jak dopasować drzewa decyzyjne i losowe lasy w R:
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej