Jak korzystać z dystrybucji t w pythonie
Rozkład t jest rozkładem prawdopodobieństwa podobnym do rozkładu normalnego , z tą różnicą, że ma cięższe „ogony” niż rozkład normalny.
Inaczej mówiąc, więcej wartości w rozkładzie znajduje się na końcach niż w środku w porównaniu do rozkładu normalnego:
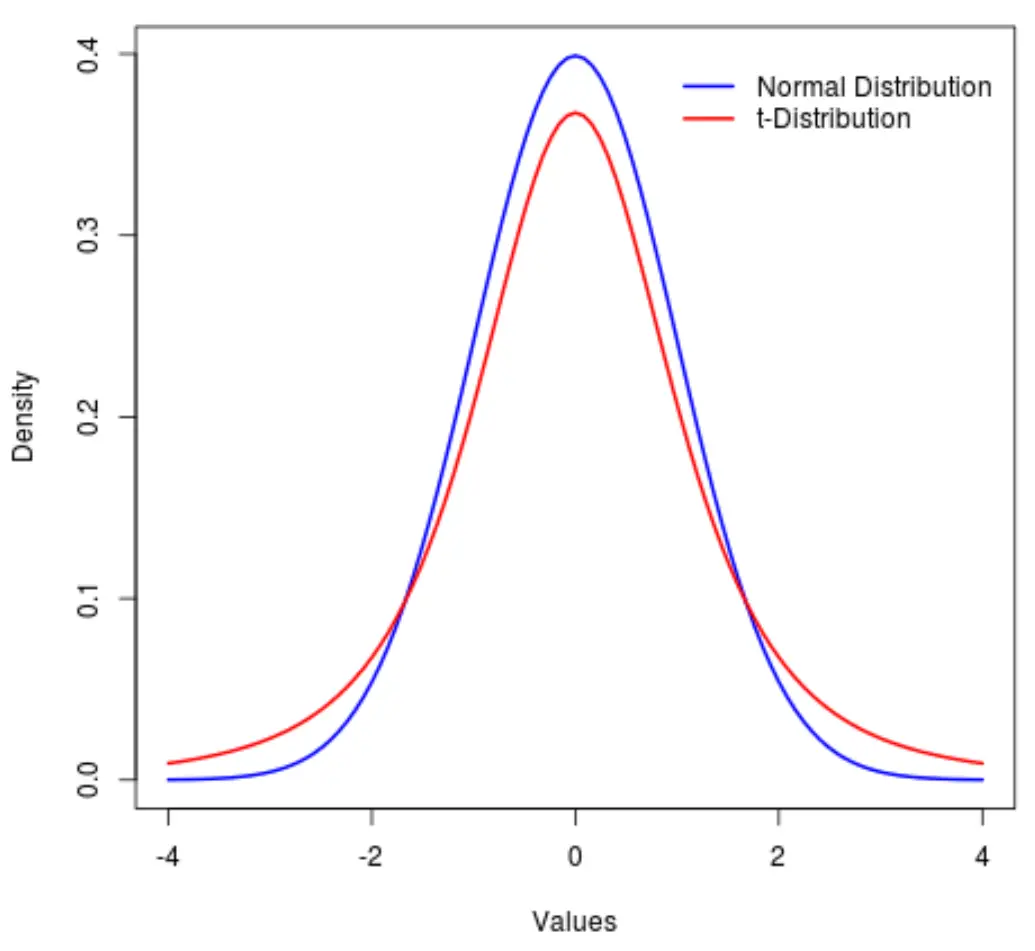
W tym samouczku wyjaśniono, jak używać dystrybucji t w Pythonie.
Jak wygenerować, aby rozpowszechniać
Za pomocą funkcji t.rvs(df, size) możesz wygenerować losowe wartości z rozkładu o określonych stopniach swobody i wielkości próby:
from scipy. stats import t #generate random values from t distribution with df=6 and sample size=10 t. rvs (df= 6 , size= 10 ) array([-3.95799716, -0.01099963, -0.55953846, -1.53420055, -1.41775611, -0.45384974, -0.2767931, -0.40177789, -0.3602592, 0.38262431])
Wynikiem jest tabela zawierająca 10 wartości, które następują po sobie według rozkładu o 6 stopniach swobody.
Jak obliczyć wartości P za pomocą rozkładu t
Możemy użyć funkcji t.cdf(x, df, loc=0, skala=1), aby znaleźć wartość p związaną ze statystyką testu t.
Przykład 1: Znajdowanie jednostronnej wartości P
Załóżmy, że przeprowadzamy jednostronny test hipotezy i otrzymujemy statystykę testową wynoszącą -1,5 i stopnie swobody = 10 .
Możemy użyć następującej składni, aby obliczyć wartość p odpowiadającą tej statystyce testowej:
from scipy. stats import t #calculate p-value t. cdf (x=-1.5, df=10) 0.08225366322272008
Jednostronna wartość p odpowiadająca statystyce testowej wynoszącej -1,5 przy 10 stopniach swobody wynosi 0,0822 .
Przykład 2: Znajdowanie dwukierunkowej wartości P
Załóżmy, że przeprowadzamy dwustronny test hipotez i otrzymujemy statystykę testową wynoszącą 2,14 i stopnie swobody = 20 .
Możemy użyć następującej składni, aby obliczyć wartość p odpowiadającą tej statystyce testowej:
from scipy. stats import t #calculate p-value (1 - t. cdf (x=2.14, df=20)) * 2 0.04486555082549959
Dwustronna wartość p odpowiadająca statystyce testowej wynoszącej 2,14 przy 20 stopniach swobody wynosi 0,0448 .
Uwaga : możesz sprawdzić te odpowiedzi za pomocą kalkulatora odwrotnego rozkładu t.
Jak śledzić dystrybucję
Aby wykreślić rozkład z określonymi stopniami swobody, można zastosować następującą składnię:
from scipy. stats import t import matplotlib. pyplot as plt #generate t distribution with sample size 10000 x = t. rvs (df= 12 , size= 10000 ) #create plot of t distribution plt. hist (x, density= True , edgecolor=' black ', bins= 20 )
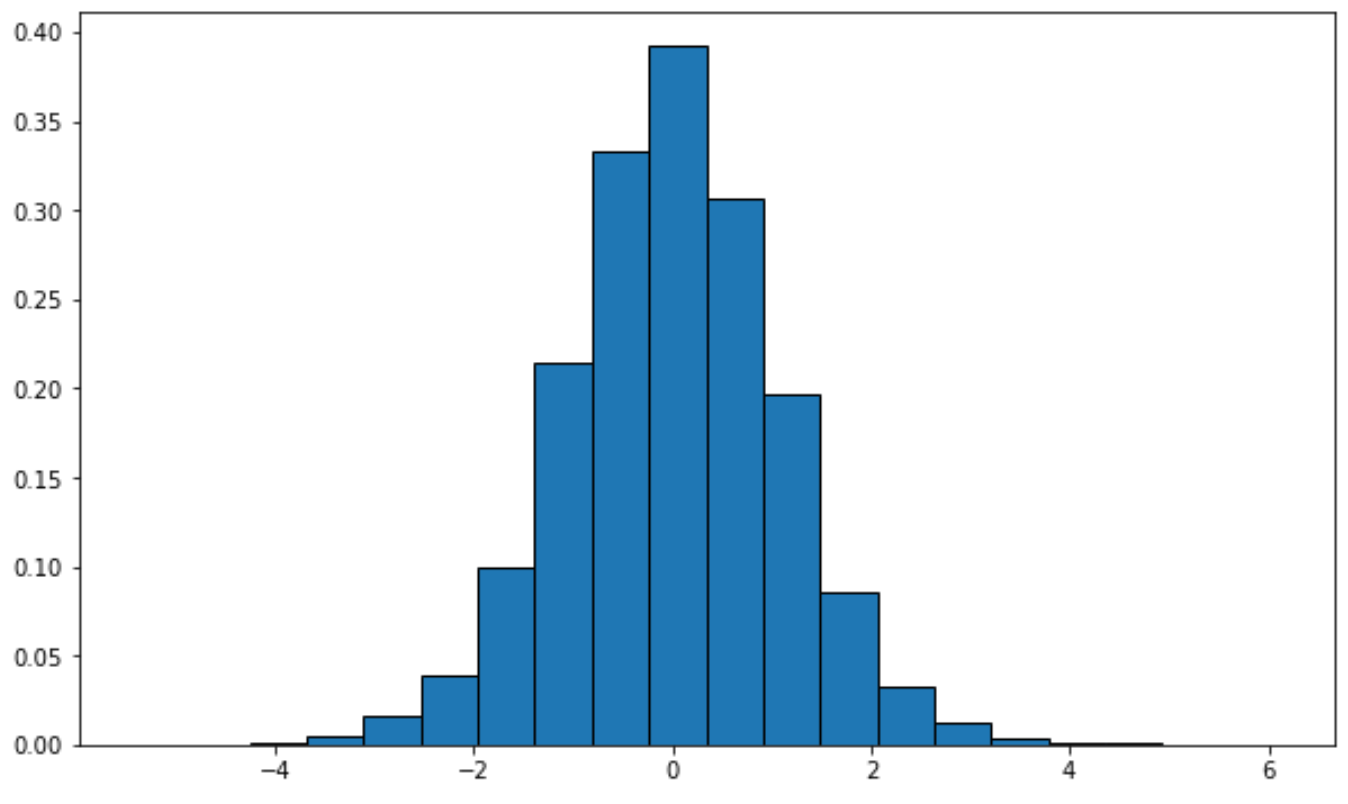
Alternatywnie możesz utworzyć krzywą gęstości za pomocą pakietu wizualizacji Seaborn :
import seaborn as sns #create density curve sns. kdeplot (x)
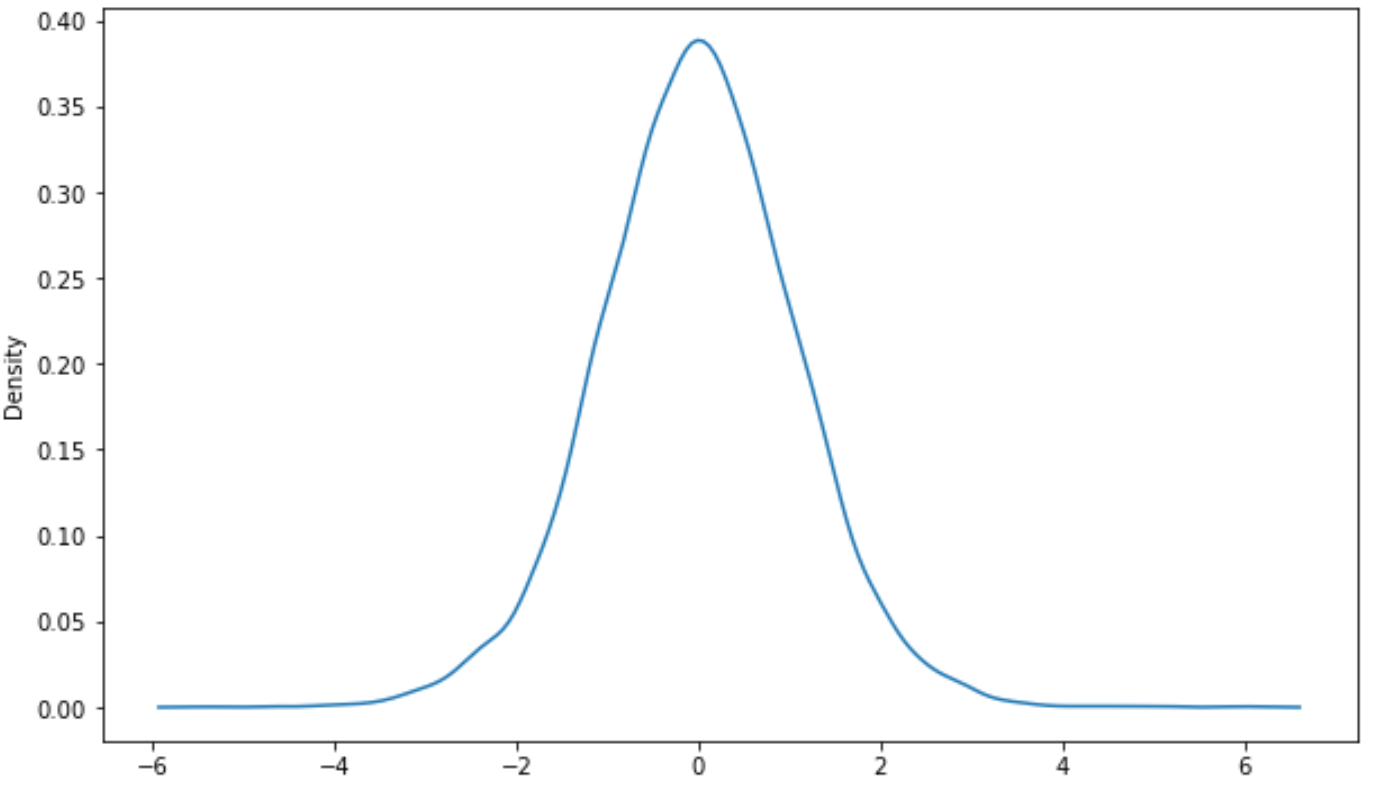
Dodatkowe zasoby
Poniższe samouczki zawierają dodatkowe informacje na temat dystrybucji:
Rozkład normalny a rozkład t: jaka jest różnica?
Kalkulator odwrotnego rozkładu t
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej