Jak obliczyć statystyki dźwigni w r
W statystyce obserwację uważa się za wartość odstającą , jeśli jej wartość dla zmiennej odpowiedzi jest znacznie większa niż pozostałych obserwacji w zbiorze danych.
Podobnie obserwację uważa się za o dużej dźwigni , jeśli ma jedną lub więcej wartości zmiennych predykcyjnych, które są znacznie bardziej ekstremalne w porównaniu z resztą obserwacji w zbiorze danych.
Jednym z pierwszych kroków w każdym rodzaju analizy jest przyjrzenie się bliżej obserwacjom, które mają dużą dźwignię, ponieważ mogą mieć duży wpływ na wyniki danego modelu.
W tym samouczku przedstawiono krok po kroku przykład obliczania i wizualizacji dźwigni dla każdej obserwacji w modelu w języku R.
Krok 1: Utwórz model regresji
Najpierw utworzymy model regresji liniowej wielokrotnej , korzystając ze zbioru danych mtcars wbudowanego w R:
#load the dataset data(mtcars) #fit a regression model model <- lm(mpg~disp+hp, data=mtcars) #view model summary summary(model) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 30.735904 1.331566 23.083 < 2nd-16 *** available -0.030346 0.007405 -4.098 0.000306 *** hp -0.024840 0.013385 -1.856 0.073679 . --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.127 on 29 degrees of freedom Multiple R-squared: 0.7482, Adjusted R-squared: 0.7309 F-statistic: 43.09 on 2 and 29 DF, p-value: 2.062e-09
Krok 2: Oblicz dźwignię dla każdej obserwacji
Następnie użyjemy funkcji hatvalues() do obliczenia dźwigni dla każdej obserwacji w modelu:
#calculate leverage for each observation in the model hats <- as . data . frame (hatvalues(model)) #display leverage stats for each observation hats hatvalues(model) Mazda RX4 0.04235795 Mazda RX4 Wag 0.04235795 Datsun 710 0.06287776 Hornet 4 Drive 0.07614472 Hornet Sportabout 0.08097817 Valiant 0.05945972 Duster 360 0.09828955 Merc 240D 0.08816960 Merc 230 0.05102253 Merc 280 0.03990060 Merc 280C 0.03990060 Merc 450SE 0.03890159 Merc 450SL 0.03890159 Merc 450SLC 0.03890159 Cadillac Fleetwood 0.19443875 Lincoln Continental 0.16042361 Chrysler Imperial 0.12447530 Fiat 128 0.08346304 Honda Civic 0.09493784 Toyota Corolla 0.08732818 Toyota Corona 0.05697867 Dodge Challenger 0.06954069 AMC Javelin 0.05767659 Camaro Z28 0.10011654 Pontiac Firebird 0.12979822 Fiat X1-9 0.08334018 Porsche 914-2 0.05785170 Lotus Europa 0.08193899 Ford Pantera L 0.13831817 Ferrari Dino 0.12608583 Maserati Bora 0.49663919 Volvo 142E 0.05848459
Zazwyczaj przyglądamy się bliżej obserwacjom z wartością dźwigni większą niż 2.
Prostym sposobem na osiągnięcie tego jest posortowanie obserwacji na podstawie ich wartości dźwigni, w kolejności malejącej:
#sort observations by leverage, descending hats[ order (-hats[' hatvalues(model) ']), ] [1] 0.49663919 0.19443875 0.16042361 0.13831817 0.12979822 0.12608583 [7] 0.12447530 0.10011654 0.09828955 0.09493784 0.08816960 0.08732818 [13] 0.08346304 0.08334018 0.08193899 0.08097817 0.07614472 0.06954069 [19] 0.06287776 0.05945972 0.05848459 0.05785170 0.05767659 0.05697867 [25] 0.05102253 0.04235795 0.04235795 0.03990060 0.03990060 0.03890159 [31] 0.03890159 0.03890159
Widzimy, że najwyższa wartość dźwigni wynosi 0,4966 . Ponieważ liczba ta nie jest większa niż 2, wiemy, że żadna z obserwacji w naszym zbiorze danych nie ma dużej dźwigni.
Krok 3: Wizualizuj dźwignię dla każdej obserwacji
Na koniec możemy stworzyć szybki wykres wizualizujący dźwignię dla każdej obserwacji:
#plot leverage values for each observation plot(hatvalues(model), type = ' h ')
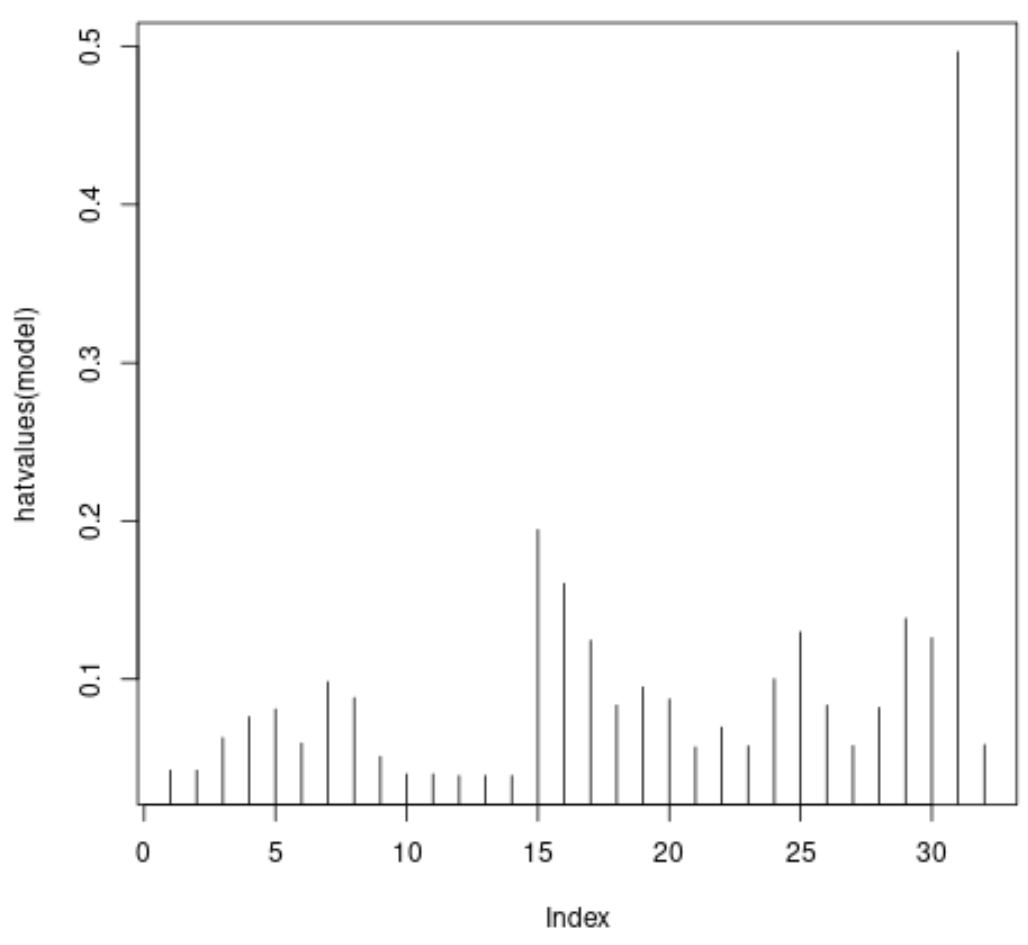
Oś x przedstawia indeks każdej obserwacji w zbiorze danych, a wartość y przedstawia odpowiednią statystykę dźwigni dla każdej obserwacji.
Dodatkowe zasoby
Jak wykonać prostą regresję liniową w R
Jak wykonać wielokrotną regresję liniową w R
Jak utworzyć wykres rezydualny w R
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej