Excel: jak używać funkcji reglinp do przeprowadzenia wielokrotnej regresji liniowej
Za pomocą funkcji REGLINP w programie Excel można dopasować model regresji liniowej do zbioru danych.
Ta funkcja wykorzystuje następującą podstawową składnię:
= LINEST ( known_y's, [known_x's], [const], [stats] )
Złoto:
- znane_y : tablica znanych wartości y
- znane_x : tablica znanych wartości x
- const : Argument opcjonalny. Jeśli TRUE, stała b jest przetwarzana normalnie. Jeśli FALSE, stała b jest ustawiona na 1.
- statystyki : argument opcjonalny. Jeśli TRUE, zwracane są dodatkowe statystyki regresji. Jeśli FALSE, dodatkowe statystyki regresji nie są zwracane.
Poniższy przykład krok po kroku pokazuje, jak w praktyce wykorzystać tę funkcję.
Krok 1: Wprowadź dane
Najpierw wprowadźmy następujący zestaw danych do Excela:
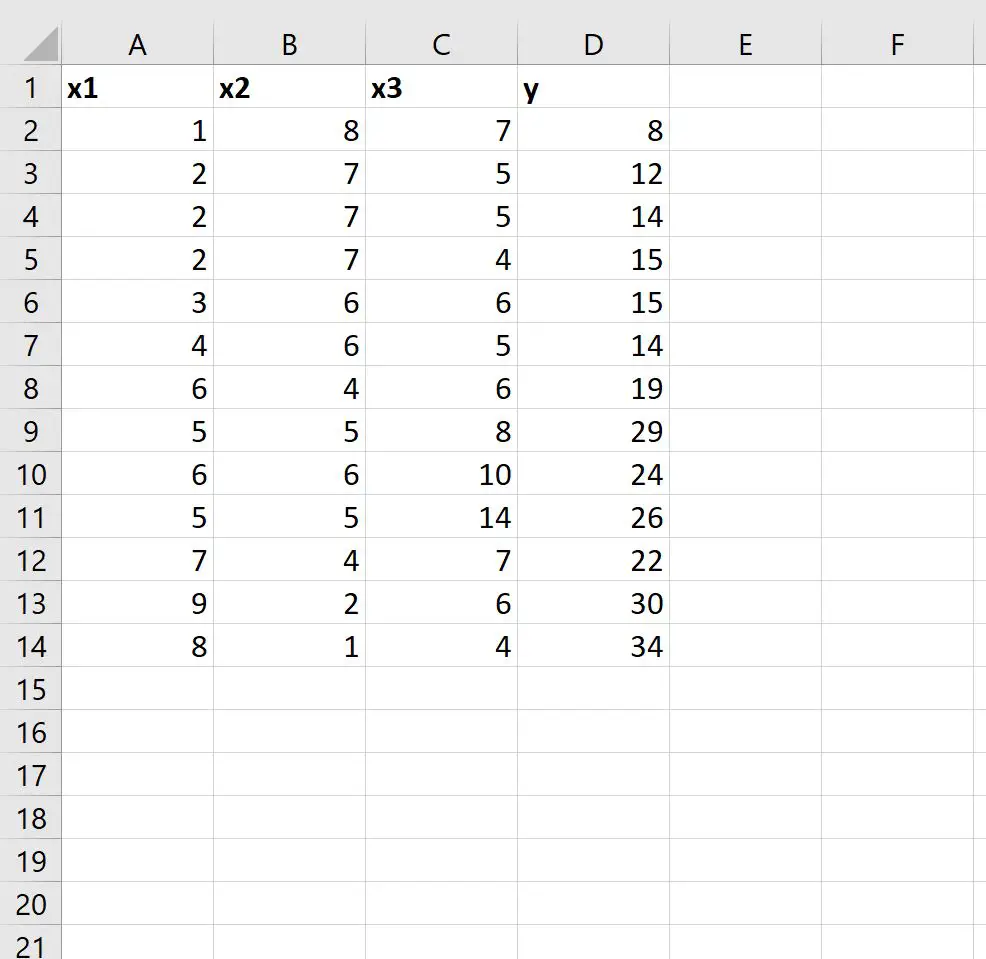
Krok 2: Użyj funkcji REGLINP, aby dopasować model regresji liniowej
Załóżmy, że chcemy dopasować model regresji liniowej, używając x1 , x2 i x3 jako zmiennych predykcyjnych oraz y jako zmiennej odpowiedzi.
Aby to zrobić, możemy wpisać następującą formułę w dowolnej komórce, aby dopasować ją do modelu regresji liniowej wielokrotnej
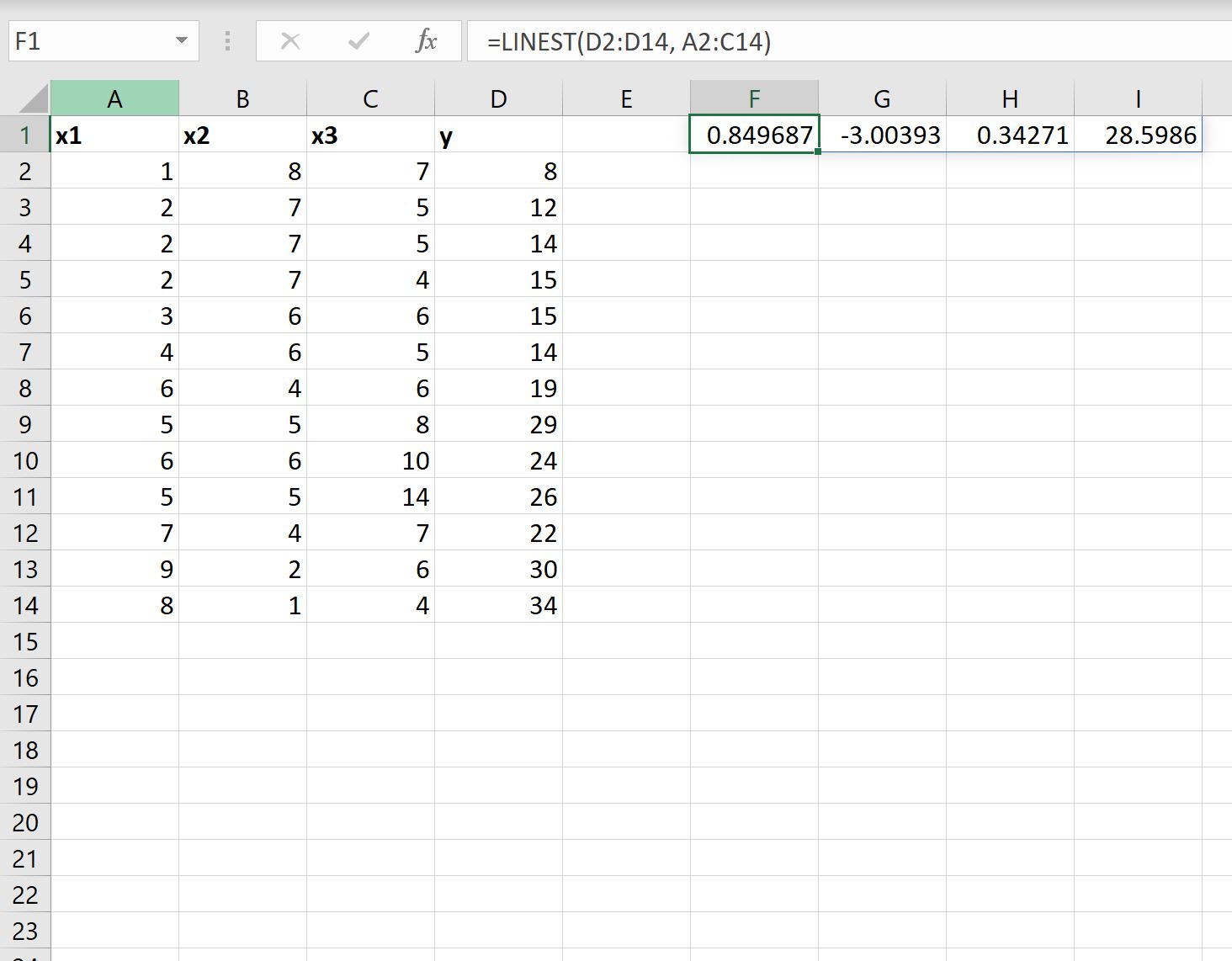
=LINEST( D2:D14 , A2:C14 )
Poniższy zrzut ekranu pokazuje, jak zastosować tę formułę w praktyce:
Oto jak zinterpretować wynik:
- Współczynnik wyrazu wolnego wynosi 28,5986 .
- Współczynnik dla x1 wynosi 0,34271 .
- Współczynnik dla x2 wynosi -3,00393 .
- Współczynnik dla x3 wynosi 0,849687 .
Korzystając z tych współczynników, możemy zapisać dopasowane równanie regresji w następujący sposób:
y = 28,5986 + 0,34271(x1) – 3,00393(x2) + 0,849687(x3)
Krok 3 (opcjonalnie): Wyświetl dodatkowe statystyki regresji
Możemy także ustawić wartość argumentu stats w funkcji REGLINP na PRAWDA , aby wyświetlić dodatkowe statystyki regresji dla dopasowanego równania regresji:
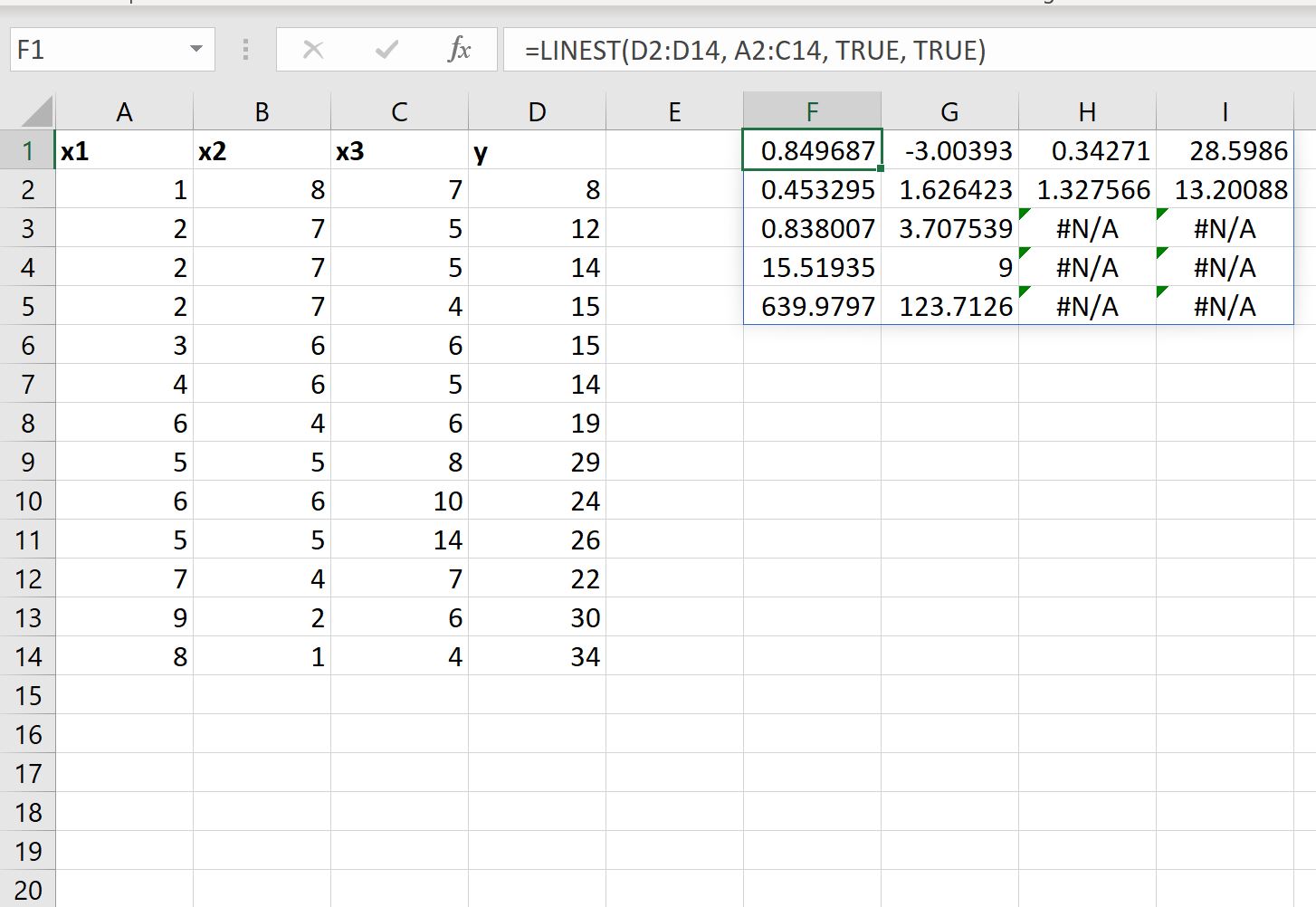
Dopasowane równanie regresji jest nadal takie samo:
y = 28,5986 + 0,34271(x1) – 3,00393(x2) + 0,849687(x3)
Oto jak interpretować pozostałe wartości wyniku:
- Standardowy błąd dla x3 wynosi 0,453295 .
- Standardowy błąd dla x2 to 1,626423 .
- Standardowy błąd dla x1 to 1,327566 .
- Standardowy błąd przechwytywania to 13.20088 .
- R 2 modelu to .838007 .
- Resztkowy błąd standardowy dla y wynosi 3,707539 .
- Ogólna statystyka F wynosi 15,51925 .
- Stopnie swobody wynoszą 9 .
- Suma kwadratów regresji wynosi 639,9797 .
- Pozostała suma kwadratów wynosi 123,7126 .
Ogólnie rzecz biorąc, miarą cieszącą się największym zainteresowaniem w tych dodatkowych statystykach jest wartość R2 , która reprezentuje proporcję wariancji zmiennej odpowiedzi, którą można wyjaśnić zmienną predykcyjną.
Wartość R2 może zmieniać się od 0 do 1.
Ponieważ R 2 tego konkretnego modelu wynosi 0,838 , mówi nam to, że zmienne predykcyjne dobrze radzą sobie z przewidywaniem wartości zmiennej odpowiedzi y.
Powiązane: Jaka jest dobra wartość R-kwadrat?
Dodatkowe zasoby
Poniższe samouczki wyjaśniają, jak wykonywać inne typowe operacje w programie Excel:
Jak korzystać z funkcji LOGEST w programie Excel
Jak wykonać regresję nieliniową w programie Excel
Jak wykonać regresję sześcienną w programie Excel
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej