Jak wykonać kodowanie one-hot w pythonie
Kodowanie typu one-hot służy do konwertowania zmiennych kategorycznych do formatu, który może być łatwo wykorzystany przez algorytmy uczenia maszynowego .
Podstawową ideą kodowania one-hot jest utworzenie nowych zmiennych, które przyjmują wartości 0 i 1 w celu reprezentowania oryginalnych wartości kategorycznych.
Na przykład poniższy obraz pokazuje, w jaki sposób kodujemy jednorazowo, aby przekonwertować zmienną kategorialną zawierającą nazwy zespołów na nowe zmienne zawierające tylko wartości 0 i 1:
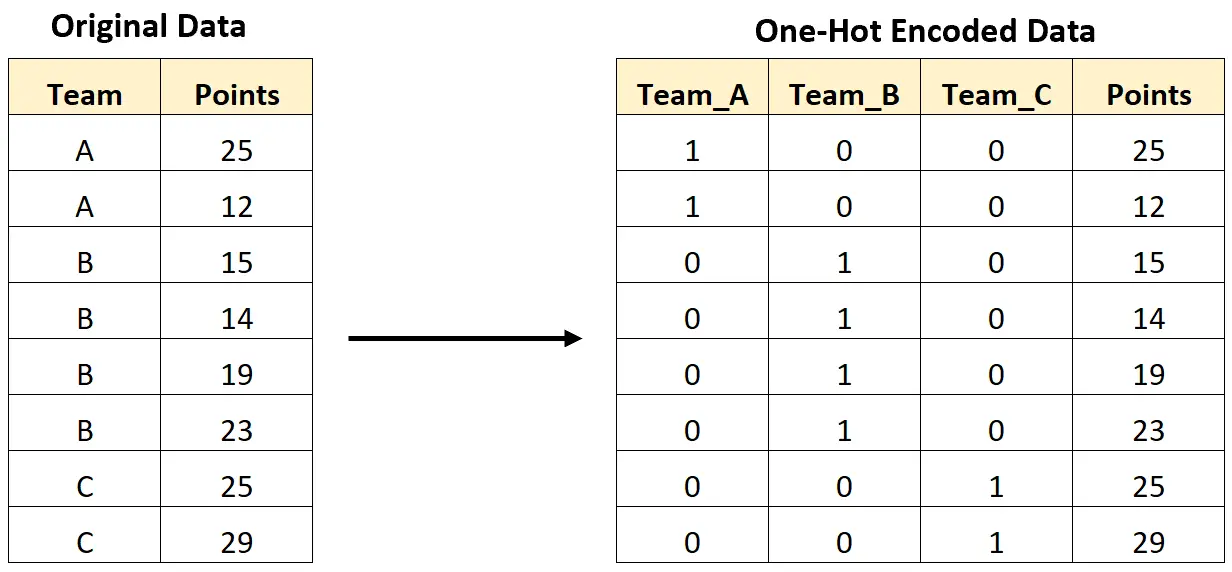
Poniższy przykład krok po kroku pokazuje, jak wykonać jednoetapowe kodowanie dla dokładnie tego zestawu danych w Pythonie.
Krok 1: Utwórz dane
Najpierw utwórzmy następującą ramkę DataFrame pandy:
import pandas as pd #createDataFrame df = pd. DataFrame ({' team ': ['A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'], ' points ': [25, 12, 15, 14, 19, 23, 25, 29]}) #view DataFrame print (df) team points 0 to 25 1 to 12 2 B 15 3 B 14 4 B 19 5 B 23 6 C 25 7 C 29
Krok 2: Wykonaj kodowanie na gorąco
Następnie zaimportujmy funkcję OneHotEncoder() z biblioteki sklearn i użyjmy jej do wykonania kodowania na gorąco w zmiennej „team” w ramce DataFrame pand:
from sklearn. preprocessing import OneHotEncoder #creating instance of one-hot-encoder encoder = OneHotEncoder(handle_unknown=' ignore ') #perform one-hot encoding on 'team' column encoder_df = pd. DataFrame ( encoder.fit_transform (df[[' team ']]). toarray ()) #merge one-hot encoded columns back with original DataFrame final_df = df. join (encoder_df) #view final df print (final_df) team points 0 1 2 0 to 25 1.0 0.0 0.0 1 to 12 1.0 0.0 0.0 2 B 15 0.0 1.0 0.0 3 B 14 0.0 1.0 0.0 4 B 19 0.0 1.0 0.0 5 B 23 0.0 1.0 0.0 6 C 25 0.0 0.0 1.0 7 C 29 0.0 0.0 1.0
Należy zauważyć, że do ramki DataFrame dodano trzy nowe kolumny, ponieważ oryginalna kolumna „zespół” zawierała trzy unikalne wartości.
Uwaga : pełną dokumentację funkcji OneHotEncoder() można znaleźć tutaj .
Krok 3: Usuń oryginalną zmienną kategoryczną
Na koniec możemy usunąć oryginalną zmienną „zespół” z ramki DataFrame, ponieważ już jej nie potrzebujemy:
#drop 'team' column final_df. drop (' team ', axis= 1 , inplace= True ) #view final df print (final_df) points 0 1 2 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
Powiązane: Jak usunąć kolumny w Pandach (4 metody)
Moglibyśmy również zmienić nazwy kolumn końcowej ramki danych, aby były łatwiejsze do odczytania:
#rename columns final_df. columns = ['points', 'teamA', 'teamB', 'teamC'] #view final df print (final_df) points teamA teamB teamC 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
Kodowanie „one-hot” zostało ukończone i możemy teraz wstawić tę ramkę DataFrame pandy do dowolnego algorytmu uczenia maszynowego.
Dodatkowe zasoby
Jak obliczyć średnią obciętą w Pythonie
Jak wykonać regresję liniową w Pythonie
Jak przeprowadzić regresję logistyczną w Pythonie
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej