Jakie jest założenie normalności w statystyce?
Wiele testów statystycznych opiera się na tak zwanym założeniu normalności .
Hipoteza ta głosi, że jeśli zbierzemy wiele niezależnych próbek losowych z populacji i obliczymy interesującą nas wartość (np. średnią z próbki ), a następnie utworzymy histogram w celu wizualizacji rozkładu średnich z próbki, powinniśmy zaobserwować idealną krzywą dzwonową .
Wiele technik statystycznych przyjmuje takie założenia dotyczące danych, w tym:
1. Test t jednej próbki : zakłada się, że dane z próby mają rozkład normalny.
2. Test t dla dwóch próbek : zakłada się, że obie próbki mają rozkład normalny.
3. ANOVA : Zakłada się, że reszty modelu mają rozkład normalny.
4. Regresja liniowa : Zakłada się, że reszty modelu mają rozkład normalny.
Jeżeli to założenie nie zostanie spełnione, wyniki tych testów staną się niewiarygodne i nie będziemy w stanie z całą pewnością uogólnić naszych wniosków wyciągniętych z próbek danych na całą populację . Dlatego ważne jest sprawdzenie, czy hipoteza ta jest spełniona.
Istnieją dwa typowe sposoby sprawdzania, czy spełnione jest to założenie o normalności:
1. Wizualizuj normalność
2. Wykonaj formalny test statystyczny
W poniższych sekcjach opisano konkretne wykresy, które można utworzyć, oraz konkretne testy statystyczne, które można wykonać w celu sprawdzenia normalności.
Wizualizuj normalność
Szybkim i nieformalnym sposobem sprawdzenia, czy zbiór danych ma rozkład normalny, jest utworzenie histogramu lub wykresu QQ.
1. Histogram
Jeśli histogram zbioru danych ma z grubsza kształt dzwonu, prawdopodobne jest, że dane mają rozkład normalny.
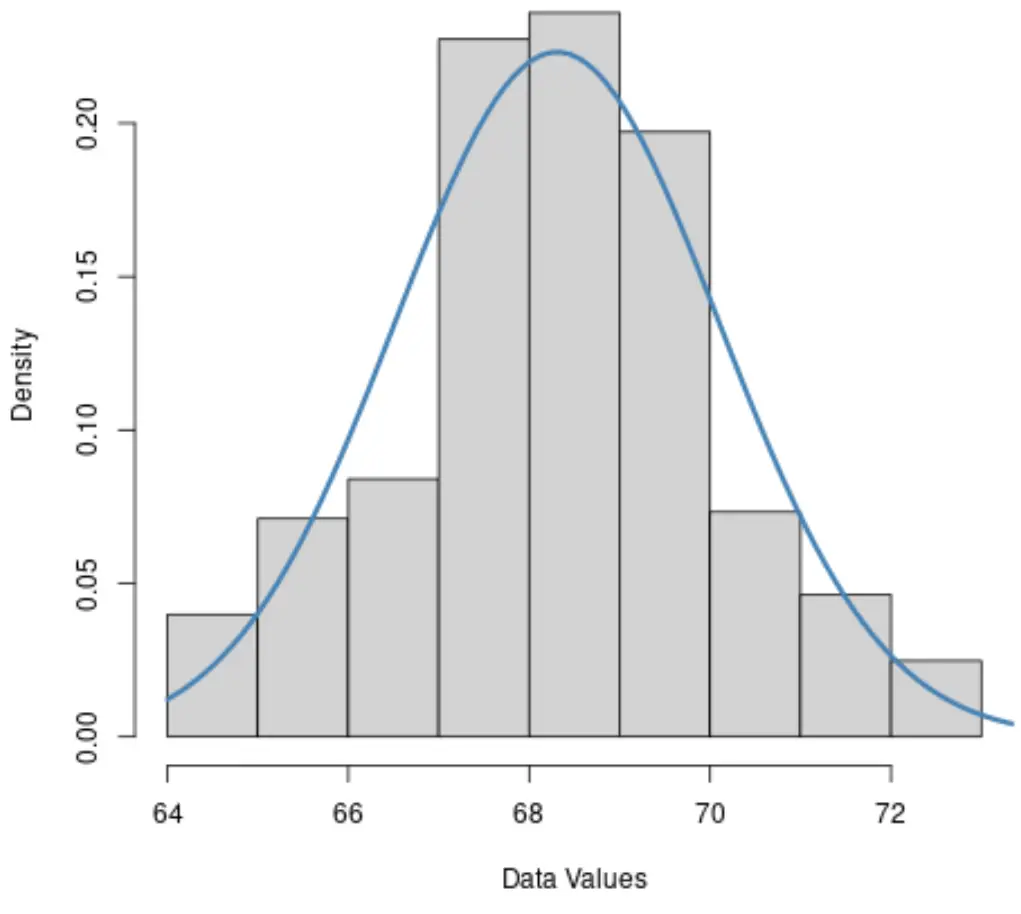
2. QQLand
Wykres QQ, skrót od „kwantyl-kwantyl”, to rodzaj wykresu przedstawiający teoretyczne kwantyle wzdłuż osi x (tzn. miejsce, w którym znajdowałyby się dane, gdyby miały rozkład normalny) oraz kwantyle próbek wzdłuż osi y. (tj. gdzie faktycznie znajdują się Twoje dane).
Jeżeli wartości danych przebiegają mniej więcej po linii prostej tworzącej kąt 45 stopni, wówczas zakłada się, że dane mają rozkład normalny.
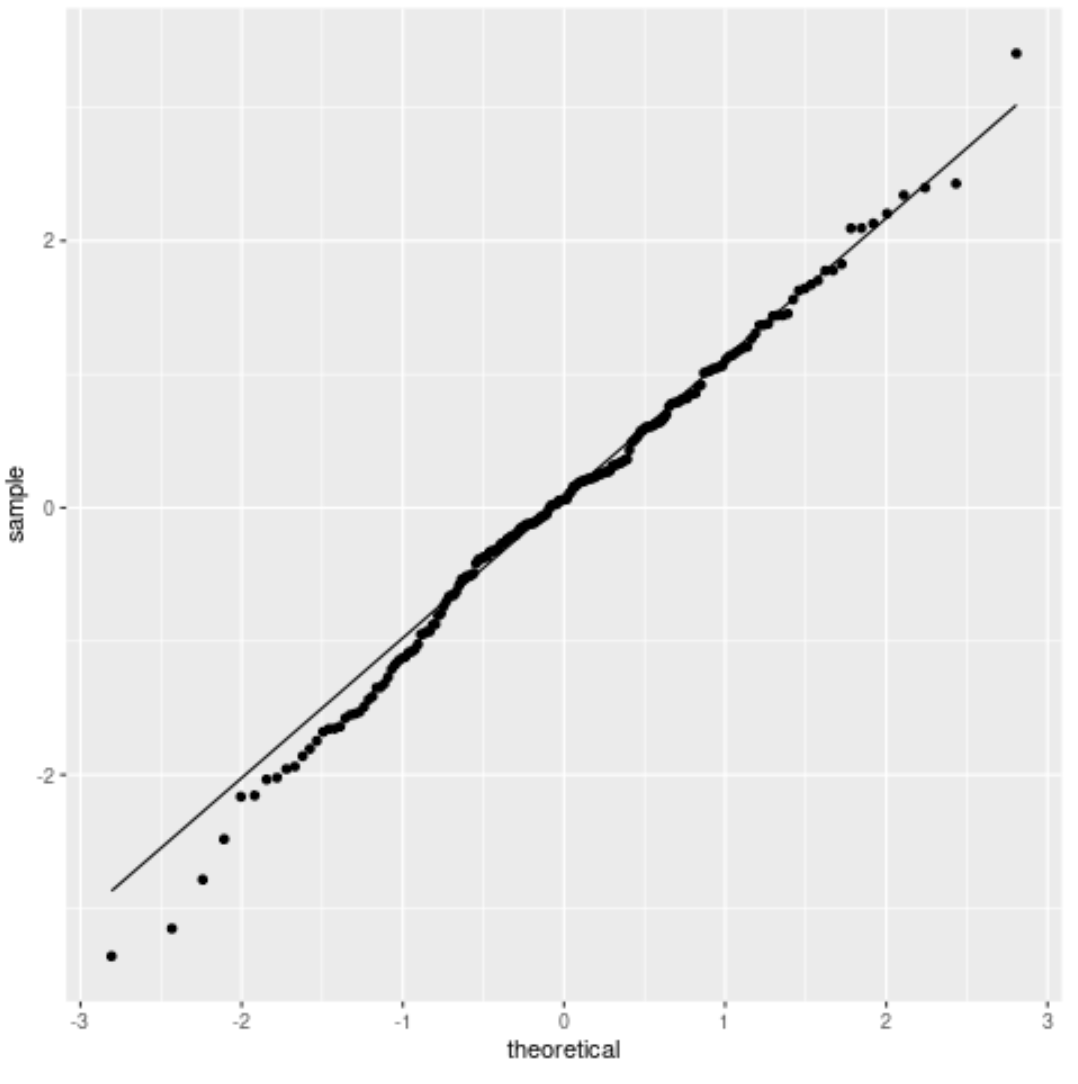
Wykonaj formalny test statystyczny
Można także przeprowadzić formalny test statystyczny, aby określić, czy zbiór danych ma rozkład normalny.
Jeśli wartość p testu jest poniżej pewnego poziomu istotności (takiego jak α = 0,05), wówczas masz wystarczające dowody, aby stwierdzić, że dane nie mają rozkładu normalnego.
Istnieją trzy testy statystyczne powszechnie stosowane do testowania normalności:
1. Test Jarque’a-Bery
- Jak wykonać test Jarque-Bera w programie Excel
- Jak wykonać test Jarque-Bera w R
- Jak wykonać test Jarque-Bera w Pythonie
2. Test Shapiro-Wilka
3. Test Kołmogorowa-Smirnowa
- Jak wykonać test Kołmogorowa-Smirnowa w programie Excel
- Jak wykonać test Kołmogorowa-Smirnowa w R
- Jak wykonać test Kołmogorowa-Smirnowa w Pythonie
Co zrobić w przypadku naruszenia założenia normalności
Jeśli okaże się, że Twoje dane nie są normalnie dystrybuowane, masz dwie możliwości:
1. Przekształć dane.
Jedną z opcji jest po prostu przekształcenie danych w celu uzyskania bardziej normalnego rozkładu. Typowe transformacje obejmują:
- Transformacja dziennika: Przekształć dane z y na log(y) .
- Transformacja pierwiastkowa: przekształć dane z y na √y
- Transformacja pierwiastka sześciennego: Przekształć dane z y na y 1/3
- Transformacja Boxa-Coxa: Przekształć dane za pomocą procedury Box-Coxa
Wykonując te przekształcenia, rozkład wartości danych na ogół staje się bardziej normalny.
2. Wykonaj test nieparametryczny
Testy statystyczne, które zakładają normalność, nazywane są testami parametrycznymi . Istnieje jednak również rodzina tak zwanych testów nieparametrycznych , które nie przyjmują takiego założenia o normalności.
Jeśli okaże się, że Twoje dane nie mają rozkładu normalnego, możesz po prostu wykonać test nieparametryczny. Oto kilka nieparametrycznych wersji popularnych testów statystycznych:
| Testowanie parametryczne | Odpowiednik nieparametryczny |
|---|---|
| Próbny test t | Przykładowy test rang podpisany przez Wilcoxona |
| Test t dla dwóch próbek | Test U Manna – Whitneya |
| Test t dla sparowanych próbek | Dwie próbki testu rang ze znakiem Wilcoxona |
| Jednokierunkowa ANOVA | Test Kruskala-Wallisa |
Każdy z tych testów nieparametrycznych umożliwia przeprowadzenie testu statystycznego bez spełnienia założenia normalności.
Dodatkowe zasoby
Cztery hipotezy sformułowane w teście T
Cztery założenia regresji liniowej
Cztery hipotezy ANOVA
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej