Grupowanie k-średnich w r: przykład krok po kroku
Grupowanie to technika uczenia maszynowego, która próbuje znaleźć grupy obserwacji w zbiorze danych.
Celem jest znalezienie takich skupień, w których obserwacje w każdym klastrze będą do siebie dość podobne, podczas gdy obserwacje w różnych skupieniach znacznie się od siebie różnią.
Klastrowanie jest formą uczenia się bez nadzoru , ponieważ po prostu staramy się znaleźć strukturę w zbiorze danych, zamiast przewidywać wartość zmiennej odpowiedzi .
Klastrowanie jest często stosowane w marketingu, gdy firmy mają dostęp do informacji takich jak:
- Przychód domowy
- Wielkość gospodarstwa domowego
- Zawód głowy gospodarstwa domowego
- Odległość do najbliższego obszaru miejskiego
Jeżeli takie informacje są dostępne, można zastosować grupowanie w celu zidentyfikowania gospodarstw domowych, które są podobne i które mogą z większym prawdopodobieństwem zakupić określone produkty lub lepiej reagować na określony rodzaj reklamy.
Jedną z najpowszechniejszych form grupowania jest grupowanie k-średnich .
Co to jest grupowanie K-średnich?
Grupowanie K-średnich to technika, w której każdą obserwację ze zbioru danych umieszczamy w jednym z K klastrów.
Ostatecznym celem jest utworzenie K klastrów, w których obserwacje w każdym klastrze są do siebie dość podobne, podczas gdy obserwacje w różnych klastrach znacznie się od siebie różnią.
W praktyce do przeprowadzenia grupowania K-średnich stosujemy następujące kroki:
1. Wybierz wartość K.
- Najpierw musimy zdecydować, ile skupień chcemy zidentyfikować w danych. Często wystarczy po prostu przetestować kilka różnych wartości K i przeanalizować wyniki, aby zobaczyć, która liczba skupień wydaje się mieć największy sens dla danego problemu.
2. Losowo przypisz każdą obserwację do skupienia początkowego, od 1 do K.
3. Wykonuj poniższą procedurę, aż przypisania klastrów przestaną się zmieniać.
- Dla każdej z gromad K oblicz środek ciężkości gromady. Jest to po prostu wektor p- średnich cech obserwacji k-tego klastra.
- Przypisz każdą obserwację do klastra o najbliższym centroidzie. Tutaj najbliżej definiuje się odległość euklidesową .
Grupowanie K-średnich w R
Poniższy samouczek zawiera przykład krok po kroku wykonywania grupowania k-średnich w języku R.
Krok 1: Załaduj niezbędne pakiety
Najpierw załadujemy dwa pakiety zawierające kilka przydatnych funkcji do grupowania k-średnich w R.
library (factoextra) library (cluster)
Krok 2: Załaduj i przygotuj dane
W tym przykładzie użyjemy zbioru danych USArrests wbudowanego w R, który zawiera liczbę aresztowań na 100 000 mieszkańców w każdym stanie USA w 1973 r. za morderstwo , napaść i gwałt , a także procent populacji każdego stanu mieszkającej w obszarach miejskich obszary. , UrbanPop .
Poniższy kod pokazuje, jak wykonać następujące czynności:
- Załaduj zbiór danych USArrests
- Usuń wszystkie wiersze z brakującymi wartościami
- Skaluj każdą zmienną w zbiorze danych tak, aby miała średnią 0 i odchylenie standardowe 1
#load data df <-USArrests #remove rows with missing values df <- na. omitted (df) #scale each variable to have a mean of 0 and sd of 1 df <- scale(df) #view first six rows of dataset head(df) Murder Assault UrbanPop Rape Alabama 1.24256408 0.7828393 -0.5209066 -0.003416473 Alaska 0.50786248 1.1068225 -1.2117642 2.484202941 Arizona 0.07163341 1.4788032 0.9989801 1.042878388 Arkansas 0.23234938 0.2308680 -1.0735927 -0.184916602 California 0.27826823 1.2628144 1.7589234 2.067820292 Colorado 0.02571456 0.3988593 0.8608085 1.864967207
Krok 3: Znajdź optymalną liczbę klastrów
Aby wykonać grupowanie k-średnich w R, możemy skorzystać z wbudowanej funkcji kmeans() , która wykorzystuje następującą składnię:
kmeans (dane, centra, nstart)
Złoto:
- dane: nazwa zbioru danych.
- centra: liczba skupień, oznaczona k .
- nstart: liczba konfiguracji początkowych. Ponieważ możliwe jest, że różne początkowe klastry początkowe będą prowadzić do różnych wyników, zaleca się stosowanie kilku różnych konfiguracji początkowych. Algorytm k-średnich znajdzie początkowe konfiguracje, które prowadzą do najmniejszej zmienności w klastrze.
Ponieważ nie wiemy z góry, ile skupień jest optymalnych, utworzymy dwa różne wykresy, które pomogą nam podjąć decyzję:
1. Liczba skupień w stosunku do sumy kwadratów
Najpierw użyjemy funkcji fviz_nbclust() , aby utworzyć wykres liczby skupień w funkcji sumy kwadratów:
fviz_nbclust(df, kmeans, method = “ wss ”)

Zazwyczaj, tworząc tego typu wykres, szukamy „kolana”, w którym suma kwadratów zaczyna się „zaginać” lub wyrównywać. Jest to na ogół optymalna liczba klastrów.
W przypadku tego wykresu wydaje się, że przy k = 4 skupiskach występuje niewielkie załamanie lub „zagięcie”.
2. Liczba klastrów a statystyki luk
Innym sposobem określenia optymalnej liczby skupień jest użycie metryki zwanej statystyką odchyleń , która porównuje całkowitą zmienność wewnątrz skupień dla różnych wartości k z ich wartościami oczekiwanymi dla rozkładu bez grupowania.
Możemy obliczyć statystykę luk dla każdej liczby klastrów za pomocą funkcji clusGap() z pakietu klastrów , a także wykreślić klastry względem statystyk luk za pomocą funkcji fviz_gap_stat() :
#calculate gap statistic based on number of clusters gap_stat <- clusGap(df, FUN = kmeans, nstart = 25, K.max = 10, B = 50) #plot number of clusters vs. gap statistic fviz_gap_stat(gap_stat)
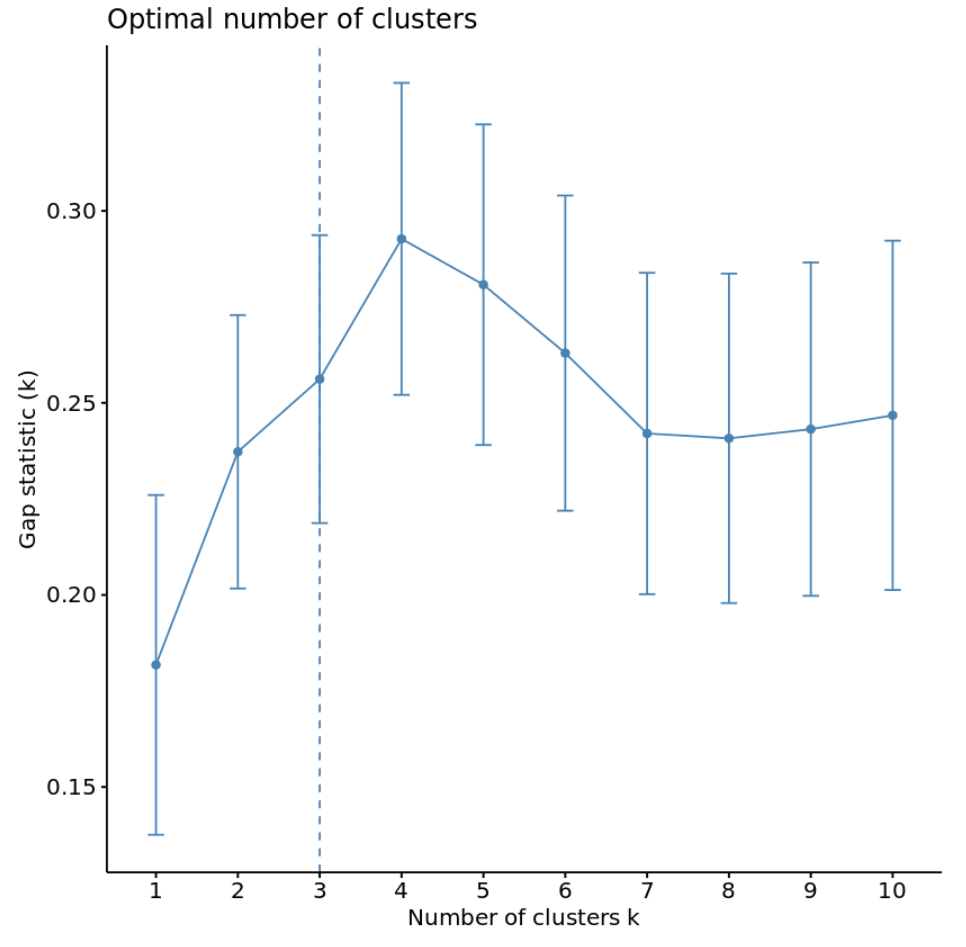
Z wykresu widać, że statystyka luki jest najwyższa przy k = 4 skupień, co odpowiada zastosowanej wcześniej metodzie łokcia.
Krok 4: Wykonaj grupowanie K-średnich z optymalnym K
Na koniec możemy przeprowadzić grupowanie k-średnich na zbiorze danych, używając optymalnej wartości k z 4:
#make this example reproducible set.seed(1) #perform k-means clustering with k = 4 clusters km <- kmeans(df, centers = 4, nstart = 25) #view results km K-means clustering with 4 clusters of sizes 16, 13, 13, 8 Cluster means: Murder Assault UrbanPop Rape 1 -0.4894375 -0.3826001 0.5758298 -0.26165379 2 -0.9615407 -1.1066010 -0.9301069 -0.96676331 3 0.6950701 1.0394414 0.7226370 1.27693964 4 1.4118898 0.8743346 -0.8145211 0.01927104 Vector clustering: Alabama Alaska Arizona Arkansas California Colorado 4 3 3 4 3 3 Connecticut Delaware Florida Georgia Hawaii Idaho 1 1 3 4 1 2 Illinois Indiana Iowa Kansas Kentucky Louisiana 3 1 2 1 2 4 Maine Maryland Massachusetts Michigan Minnesota Mississippi 2 3 1 3 2 4 Missouri Montana Nebraska Nevada New Hampshire New Jersey 3 2 2 3 2 1 New Mexico New York North Carolina North Dakota Ohio Oklahoma 3 3 4 2 1 1 Oregon Pennsylvania Rhode Island South Carolina South Dakota Tennessee 1 1 1 4 2 4 Texas Utah Vermont Virginia Washington West Virginia 3 1 2 1 1 2 Wisconsin Wyoming 2 1 Within cluster sum of squares by cluster: [1] 16.212213 11.952463 19.922437 8.316061 (between_SS / total_SS = 71.2%) Available components: [1] "cluster" "centers" "totss" "withinss" "tot.withinss" "betweenss" [7] "size" "iter" "ifault"
Z wyników możemy zobaczyć, że:
- Do pierwszego skupienia przypisano 16 stanów
- Do drugiego skupienia przypisano 13 stanów
- Do trzeciego skupienia przypisano 13 stanów
- Do czwartego skupienia przypisano 8 stanów
Możemy wizualizować skupienia na wykresie punktowym, który wyświetla pierwsze dwie główne składowe na osiach, używając funkcji fivz_cluster() :
#plot results of final k-means model
fviz_cluster(km, data = df)
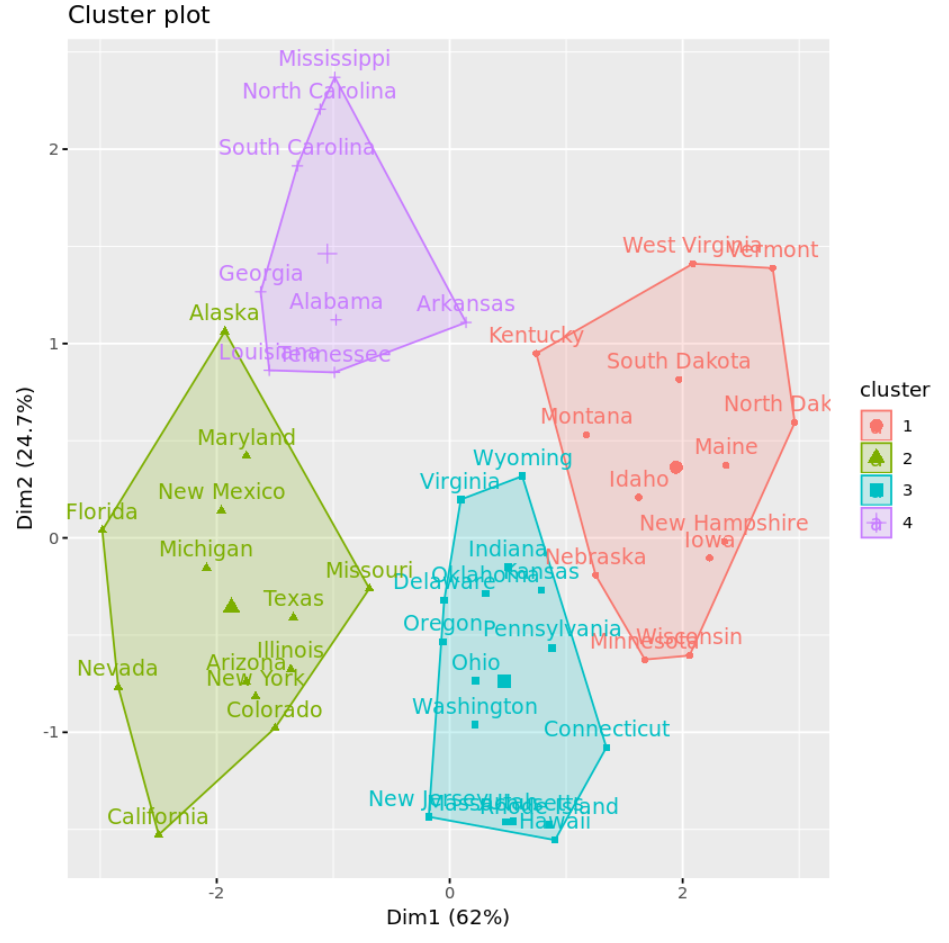
Możemy również użyć funkcji Aggregate() , aby znaleźć średnią zmiennych w każdym klastrze:
#find means of each cluster
aggregate(USArrests, by= list (cluster=km$cluster), mean)
cluster Murder Assault UrbanPop Rape
1 3.60000 78.53846 52.07692 12.17692
2 10.81538 257.38462 76.00000 33.19231
3 5.65625 138.87500 73.87500 18.78125
4 13.93750 243.62500 53.75000 21.41250
Interpretujemy ten wynik w następujący sposób:
- Średnia liczba morderstw na 100 000 obywateli w państwach Grupy 1 wynosi 3,6 .
- Średnia liczba napaści na 100 000 obywateli w państwach Grupy 1 wynosi 78,5 .
- Średni odsetek mieszkańców zamieszkujących obszary miejskie wśród państw Grupy 1 wynosi 52,1% .
- Średnia liczba gwałtów na 100 000 obywateli w państwach Grupy 1 wynosi 12,2 .
I tak dalej.
Możemy również dodać przypisania klastrów każdego stanu do oryginalnego zbioru danych:
#add cluster assignment to original data
final_data <- cbind(USArrests, cluster = km$cluster)
#view final data
head(final_data)
Murder Assault UrbanPop Rape cluster
Alabama 13.2 236 58 21.2 4
Alaska 10.0 263 48 44.5 2
Arizona 8.1 294 80 31.0 2
Arkansas 8.8 190 50 19.5 4
California 9.0 276 91 40.6 2
Colorado 7.9 204 78 38.7 2
Zalety i wady grupowania K-średnich
Klastrowanie K-średnich ma następujące zalety:
- To szybki algorytm.
- Dobrze radzi sobie z dużymi zbiorami danych.
Ma jednak następujące potencjalne wady:
- Wymaga to od nas określenia liczby klastrów przed uruchomieniem algorytmu.
- Jest wrażliwy na wartości odstające.
Dwie alternatywy dla grupowania k-średnich to grupowanie k-średnich i grupowanie hierarchiczne.
Pełny kod R użyty w tym przykładzie znajdziesz tutaj .
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej