Jak używać proc cluster w sas-ie (z przykładem)
Grupowanie to technika uczenia maszynowego, która próbuje znaleźć grupy obserwacji w zbiorze danych.
Celem jest znalezienie takich skupień, w których obserwacje w obrębie każdego skupienia będą do siebie dość podobne, podczas gdy obserwacje w różnych skupieniach znacznie się od siebie różnią.
Najłatwiejszym sposobem klastrowania w SAS-ie jest użycie PROC CLUSTER .
Poniższy przykład pokazuje, jak w praktyce wykorzystać PROC CLUSTER .
Przykład: Jak używać PROC CLUSTER w SAS-ie
Załóżmy, że mamy następujący zbiór danych zawierający informacje o punktach, asystach i zbiórkach 20 różnych koszykarzy:
/*create dataset*/
data my_data;
input points assists rebounds;
datalines ;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run ;
/*view dataset*/
proc print data =my_data;
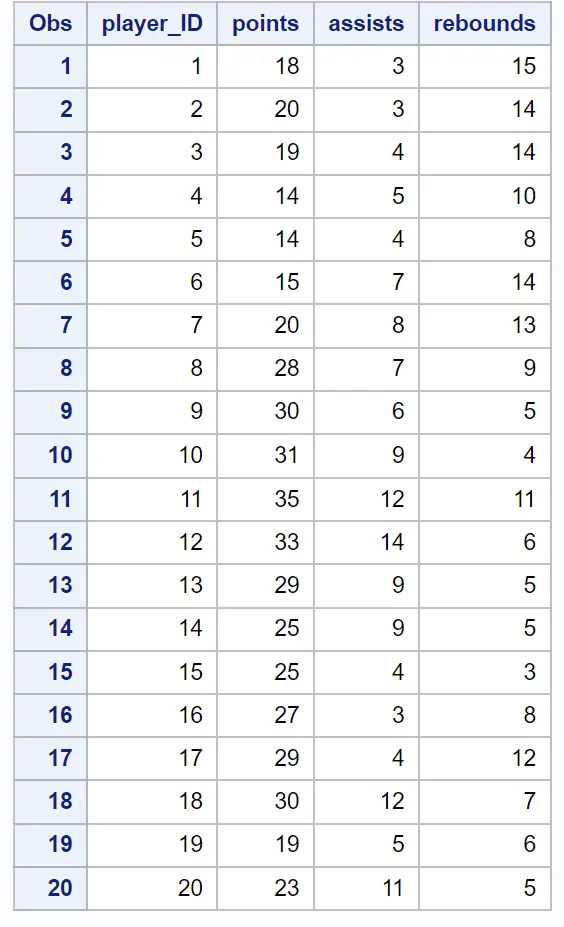
Powiedzmy, że chcemy dokonać grupowania, aby spróbować zidentyfikować „grupy” graczy o podobnych statystykach.
Poniższy kod pokazuje, jak używać PROC CLUSTER w SAS-ie do wykonywania klastrów:
/*perform clustering using points, assists and rebounds variables*/
proc cluster data =my_data method =average;
var points assists rebounds;
run ;
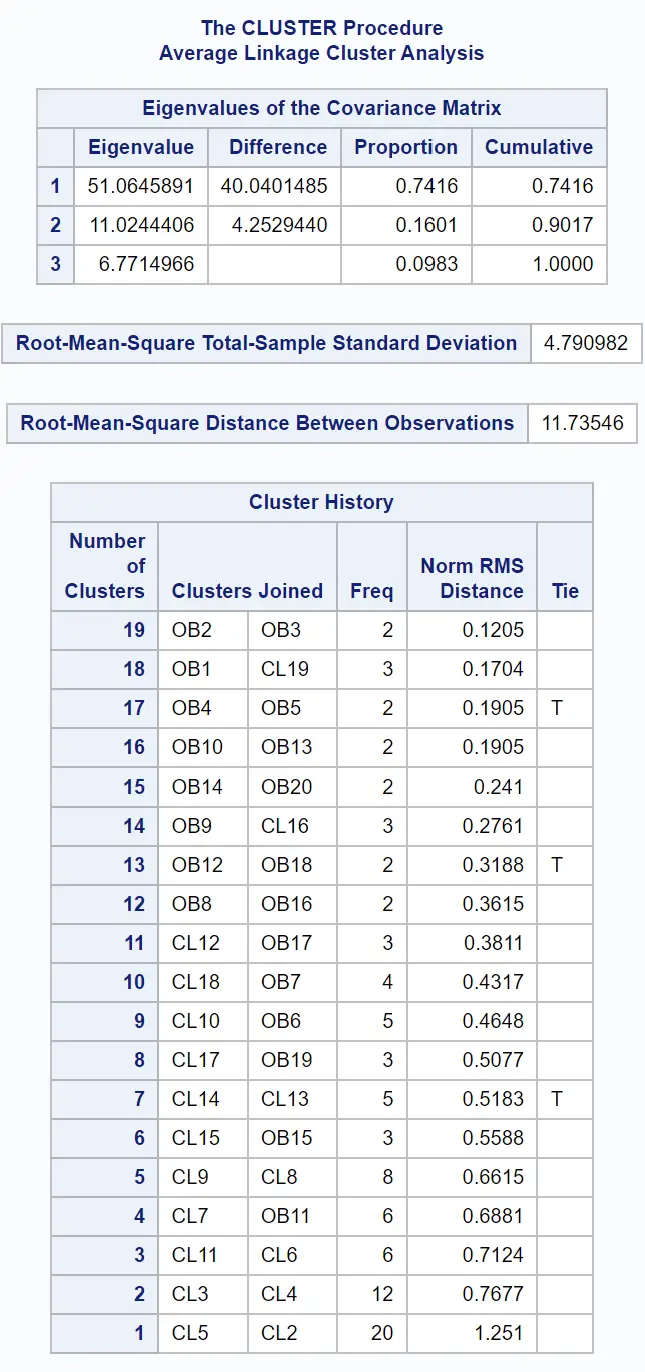
Pierwsze tabele wyników dostarczają informacji o sposobie przeprowadzenia grupowania:
Generowany jest również dendrogram, dzięki któremu możemy wizualnie sprawdzić podobieństwo obserwacji w zbiorze danych:
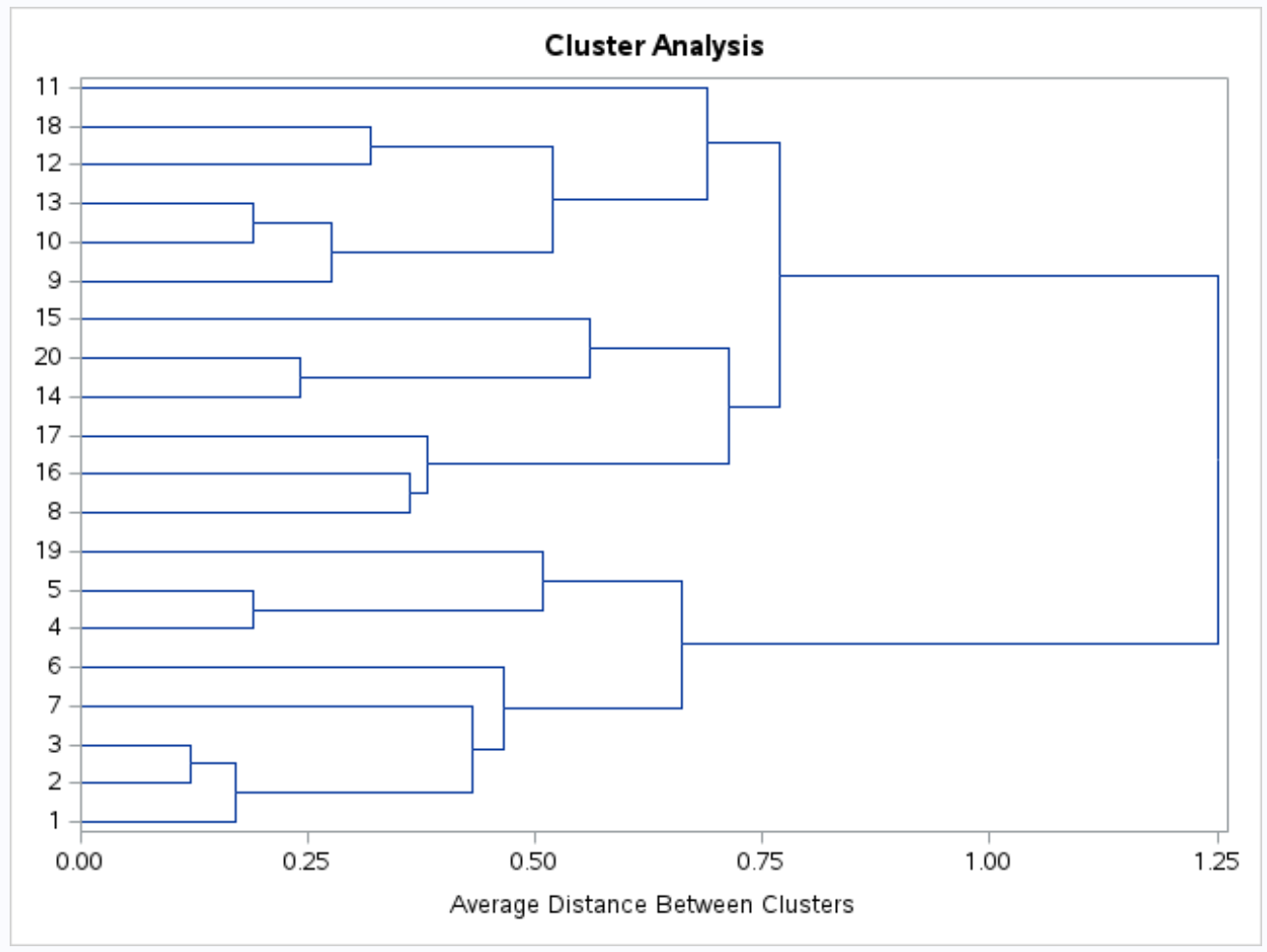
Oś y przedstawia pojedyncze obserwacje, a oś x przedstawia średnią odległość pomiędzy klastrami.
Patrząc na ten dendrogram, wydaje się, że obserwacje można w naturalny sposób podzielić na trzy grupy:
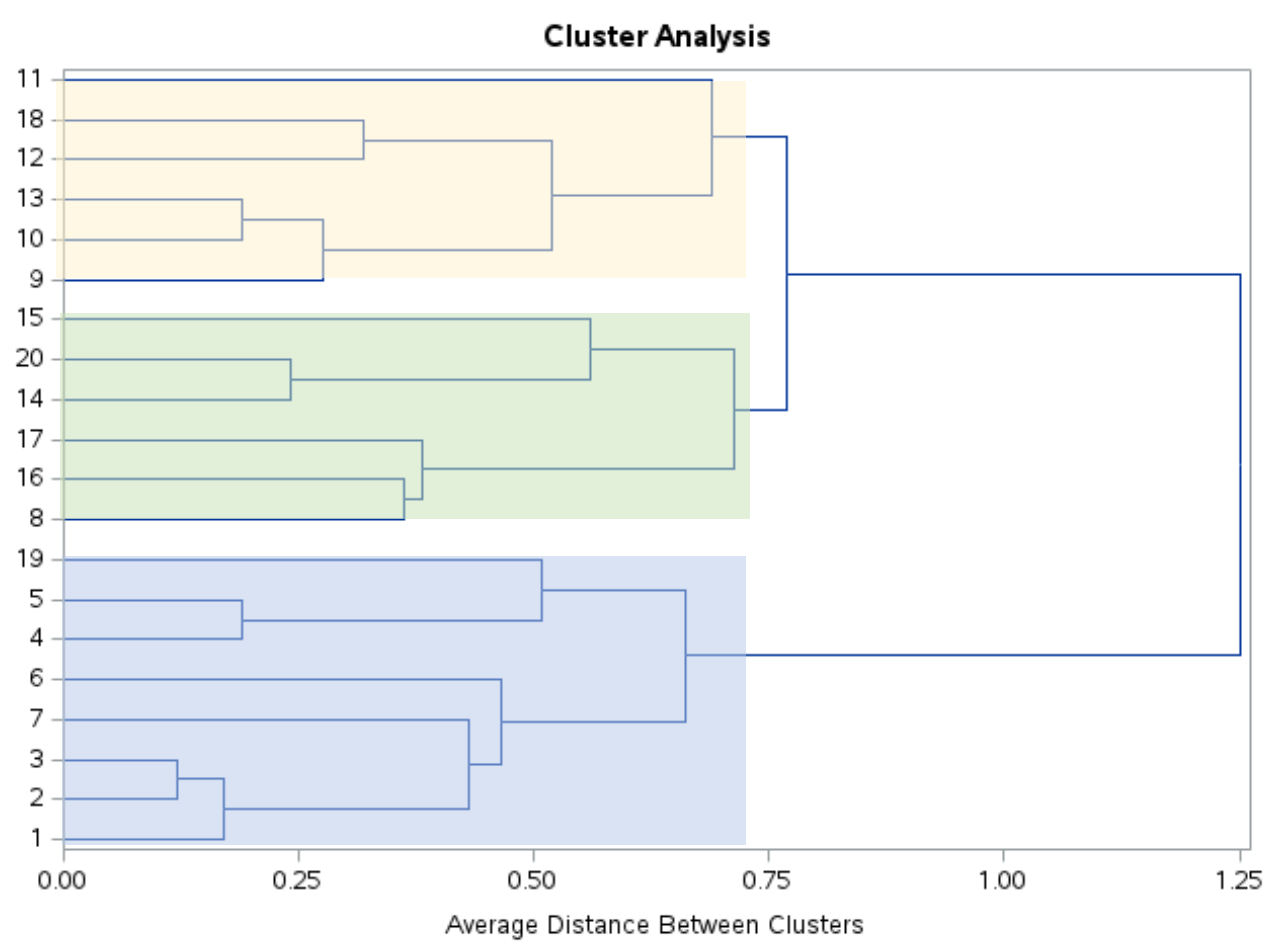
Możemy następnie użyć instrukcji PROC TREE z ncl=3 , aby poinformować SAS, aby przypisał każdą obserwację w oryginalnym zbiorze danych do jednego z trzech klastrów:
/*assign each observation to one of three clusters*/
proc tree data =clustd noprint ncl =3 out =clusts;
copy points assists rebounds;
id player_ID;
run ;
proc sort ;
by cluster;
run ;
/*view cluster assignments*/
proc print data = clusters;
id player_ID;
run ;
Powstały zbiór danych przedstawia każdą z oryginalnych obserwacji wraz z klastrem, do którego należą:
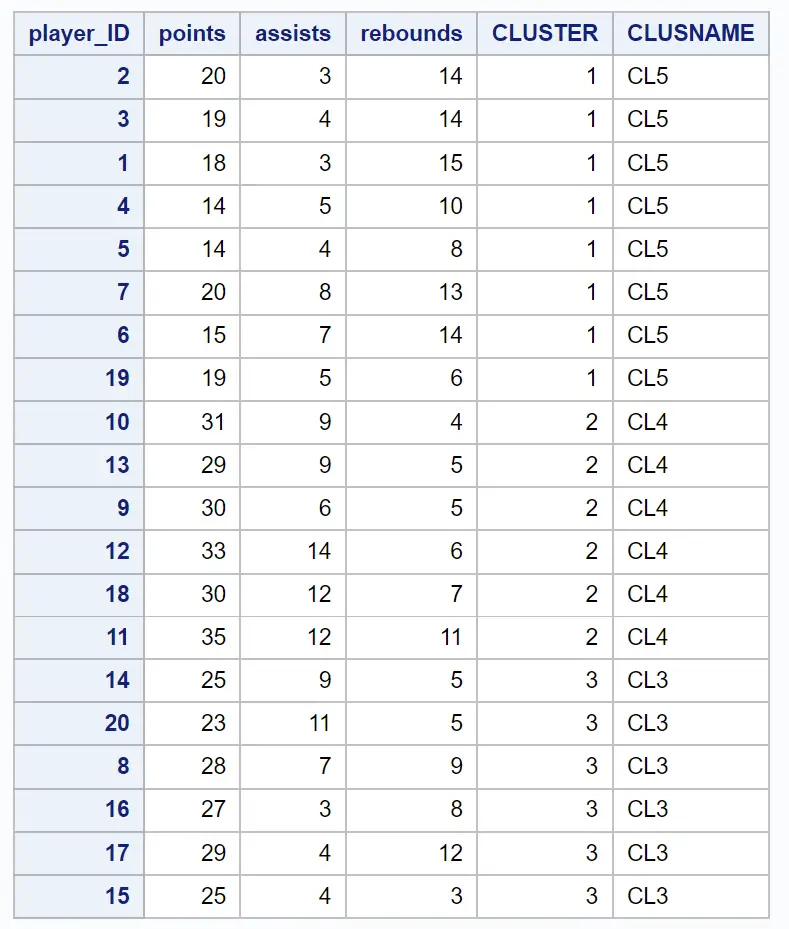
Na przykład widzimy: że wszyscy gracze o identyfikatorach 2, 3, 1, 4, 5, 7, 6 i 19 należą do klastra 1 .
To mówi nam, że tych ośmiu graczy jest „podobnych” pod względem punktów, asyst i zbiórek.
Uwaga : w tym przykładzie wybraliśmy uśrednianie jako metodę łączenia w klastrach. Pełną listę innych metod wiązania, których możesz użyć, znajdziesz w dokumentacji SAS-a .
Dodatkowe zasoby
Poniższe samouczki wyjaśniają, jak wykonywać inne typowe zadania w SAS-ie:
Jak przeprowadzić analizę głównych komponentów w SAS-ie
Jak wykonać wielokrotną regresję liniową w SAS-ie
Jak przeprowadzić regresję logistyczną w SAS-ie
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej