Jak korzystać z pand get dummies – pd.get_dummies
Często w statystykach zbiory danych, z którymi pracujemy, obejmują zmienne kategoryczne .
Są to zmienne, które przyjmują nazwy lub etykiety. Przykłady obejmują:
- Stan cywilny („żonaty”, „panny”, „rozwiedziony”)
- Status palenia („palacz”, „niepalący”)
- Kolor oczu („niebieski”, „zielony”, „piwne”)
- Poziom wykształcenia (np. „liceum”, „licencjat”, „magister”)
Dostrajając algorytmy uczenia maszynowego (takie jak regresja liniowa , regresja logistyczna , lasy losowe itp.) często konwertujemy zmienne kategoryczne na zmienne fikcyjne , które są zmiennymi numerycznymi używanymi do reprezentowania danych kategorycznych.
Załóżmy na przykład, że mamy zbiór danych zawierający zmienną kategorialną Płeć . Aby użyć tej zmiennej jako predyktora w modelu regresji, konieczne byłoby najpierw przekształcenie jej w zmienną fikcyjną.
Aby utworzyć tę fikcyjną zmienną, możemy wybrać jedną z wartości („Mężczyzna”), która będzie reprezentować 0, a drugą wartość („Kobieta”), która będzie reprezentować 1:
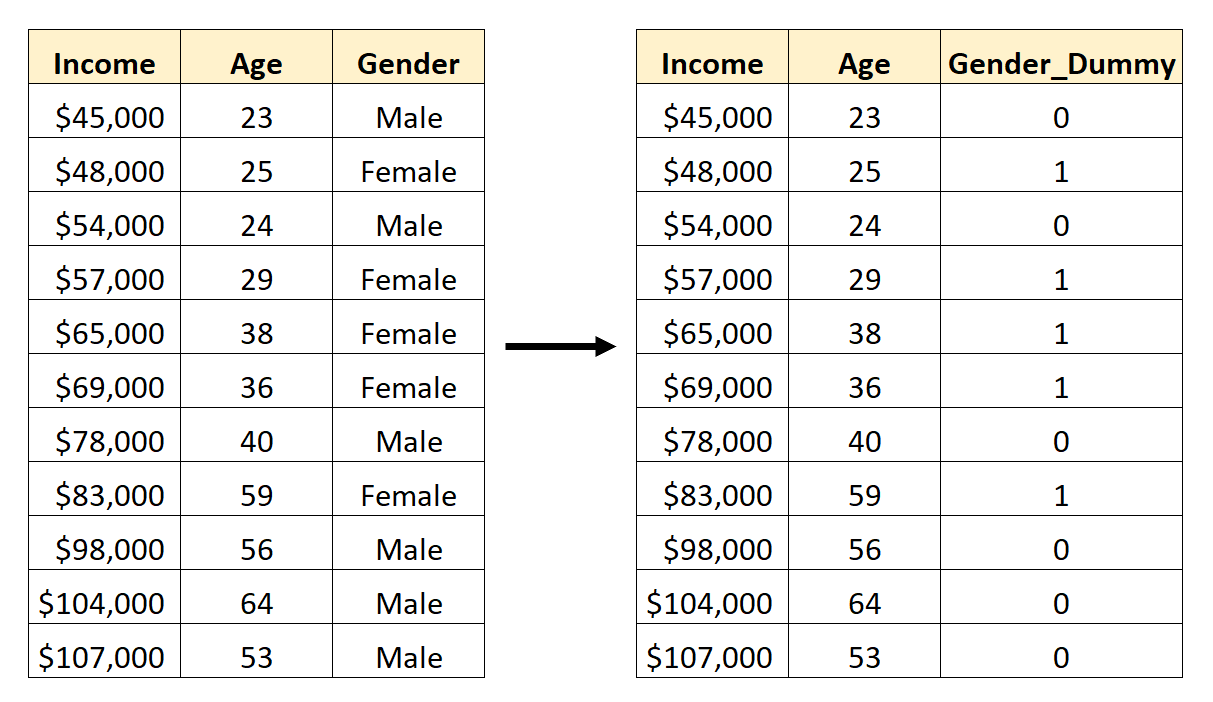
Jak utworzyć fikcyjne zmienne w Pandach
Aby utworzyć manekiny dla zmiennej w ramce DataFrame pandy, możemy użyć funkcji pandas.get_dummies() , która wykorzystuje następującą podstawową składnię:
pandas.get_dummies(data, prefix=Brak, kolumny=Brak, drop_first=False)
Złoto:
- data : Nazwa ramki DataFrame pandy
- prefix : ciąg znaków do dodania na początku nowej kolumny zmiennej fikcyjnej
- kolumny : nazwa kolumn do przekształcenia w zmienną fikcyjną
- drop_first : czy usunąć pierwszą fikcyjną kolumnę zmiennej
Poniższe przykłady pokazują, jak w praktyce wykorzystać tę funkcję.
Przykład 1: Utwórz pojedynczą zmienną fikcyjną
Załóżmy, że mamy następującą ramkę danych pandy:
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M']}) #view DataFrame df income age gender 0 45 23 M 1 48 25 F 2 54 24 M 3 57 29 F 4 65 38 F 5 69 36 F 6 78 40 M
Możemy użyć funkcji pd.get_dummies() , aby zamienić płeć w zmienną fikcyjną:
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender '], drop_first= True ) income age gender_M 0 45 23 1 1 48 25 0 2 54 24 1 3 57 29 0 4 65 38 0 5 69 36 0 6 78 40 1
Kolumna płeć jest teraz zmienną fikcyjną, gdzie:
- Wartość 0 oznacza „Kobieta”
- Wartość 1 oznacza „mężczyznę”
Przykład 2: Utwórz wiele zmiennych fikcyjnych
Załóżmy, że mamy następującą ramkę danych pandy:
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M'], ' college ': ['Y', 'N', 'N', 'N', 'Y', 'Y', 'Y']}) #view DataFrame df income age gender college 0 45 23 M Y 1 48 25 F N 2 54 24 M N 3 57 29 F N 4 65 38 F Y 5 69 36 F Y 6 78 40 M Y
Możemy użyć funkcji pd.get_dummies() do przekształcenia płci i uczelni w zmienne fikcyjne:
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender ', ' college '], drop_first= True ) income age gender_M college_Y 0 45 23 1 1 1 48 25 0 0 2 54 24 1 0 3 57 29 0 0 4 65 38 0 1 5 69 36 0 1 6 78 40 1 1
Kolumna płeć jest teraz zmienną fikcyjną, gdzie:
- Wartość 0 oznacza „Kobieta”
- Wartość 1 oznacza „mężczyznę”
Kolumna uczelni jest teraz zmienną fikcyjną, gdzie:
- Wartość 0 oznacza uniwersytet „Nie”.
- Wartość 1 oznacza „Tak” dla uczelni
Dodatkowe zasoby
Jak używać zmiennych fikcyjnych w analizie regresji
Co to jest fikcyjna pułapka zmienna?
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej