Binning o równej częstotliwości w pythonie
W statystyce grupowanie to proces umieszczania wartości liczbowych w grupach .
Najbardziej popularną formą grupowania jest grupowanie o równej szerokości , w którym dzielimy zbiór danych na k grup o równej szerokości.
Mniej powszechnie stosowaną formą grupowania jest grupowanie o równej częstotliwości , w którym dzielimy zbiór danych na k grup, z których każda ma równą liczbę częstotliwości.
W tym samouczku wyjaśniono, jak wykonać grupowanie o równej częstotliwości w Pythonie.
Binning o równej częstotliwości w Pythonie
Załóżmy, że mamy zbiór danych zawierający 100 wartości:
import numpy as np import matplotlib.pyplot as plt #create data np.random.seed(1) data = np.random.randn(100) #view first 5 values data[:5] array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
Grupowanie o równej szerokości:
Jeśli utworzymy histogram do wyświetlenia tych wartości, Python domyślnie zastosuje grupowanie o równej szerokości:
#create histogram with equal-width bins n, bins, patches = plt.hist(data, edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -1.85282729, -1.40411588, -0.95540447, -0.50669306, -0.05798165, 0.39072977, 0.83944118, 1.28815259, 1.736864, 2.18557541]), array([ 3., 1., 6., 17., 19., 20., 14., 12., 5., 3.]))
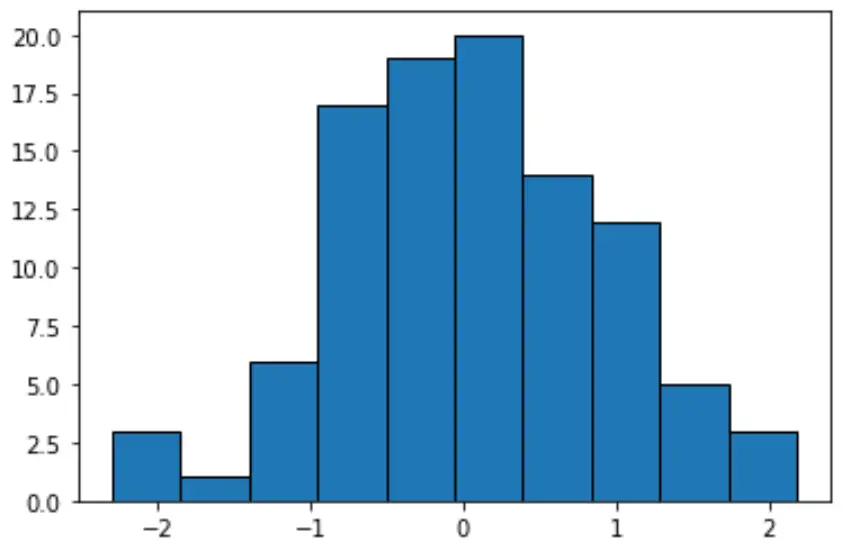
Każda grupa ma równą szerokość wynoszącą około 0,4487, ale każda grupa nie zawiera równej liczby obserwacji. Na przykład:
- Pierwszy przedział rozciąga się od -2,3015387 do -1,8528279 i zawiera 3 obserwacje.
- Drugi przedział rozciąga się od -1,8528279 do -1,40411588 i zawiera 1 obserwację.
- Trzeci przedział rozciąga się od -1,40411588 do -0,95540447 i zawiera 6 obserwacji.
I tak dalej.
Grupowanie o równej częstotliwości:
Aby utworzyć segmenty zawierające taką samą liczbę obserwacji, możemy skorzystać z następującej funkcji:
#define function to calculate equal-frequency bins def equalObs(x, nbin): nlen = len(x) return np.interp(np.linspace(0, nlen, nbin + 1), np.arange(nlen), np.sort(x)) #create histogram with equal-frequency bins n, bins, patches = plt.hist(data, equalObs(data, 10), edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -0.93576943, -0.67124613, -0.37528495, -0.20889423, 0.07734007, 0.2344157, 0.51292982, 0.86540763, 1.19891788, 2.18557541]), array([10., 10., 10., 10., 10., 10., 10., 10., 10., 10.]))
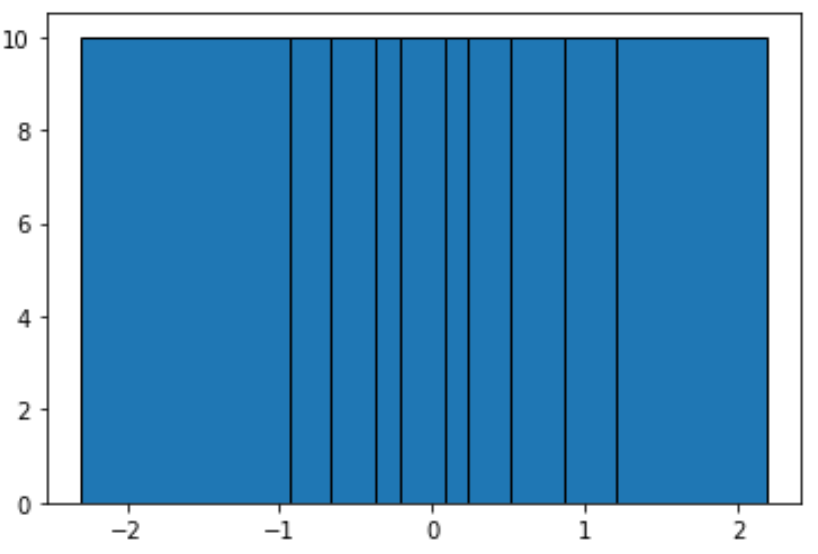
Każda grupa nie ma równej szerokości, ale każda grupa zawiera taką samą liczbę obserwacji. Na przykład:
- Pierwszy przedział rozciąga się od -2,3015387 do -0,93576943 i zawiera 10 obserwacji.
- Drugi przedział rozciąga się od -0,93576943 do -0,67124613 i zawiera 10 obserwacji.
- Trzeci przedział rozciąga się od -0,67124613 do -0,37528495 i zawiera 10 obserwacji.
I tak dalej.
Z histogramu widać, że każdy pojemnik nie ma wyraźnie tej samej szerokości, ale w każdym pojemniku znajduje się taka sama liczba obserwacji, co potwierdza fakt, że wysokość każdego pojemnika jest równa.
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej