Jak ustawić kolumnę ramki danych jako indeks w r (z przykładem)
Ramki danych w R nie mają kolumny „indeksowej”, tak jak ramki danych w pandach.
Jednak ramki danych w R mają nazwy wierszy , które działają tak samo jak kolumna indeksu.
Możesz użyć dowolnej z poniższych metod, aby ustawić istniejącą kolumnę ramki danych jako nazwy wierszy ramki danych w R:
Metoda 1: Ustaw nazwy wierszy przy użyciu podstawy R
#set specific column as row names rownames(df) <- df$my_column #remove original column from data frame df$my_column <- NULL
Metoda 2: Ustaw nazwy wierszy za pomocą pakietu Tidyverse
library (tidyverse) #set specific column as row names df <- df %>% column_to_rownames(., var = ' my_column ')
Metoda 3: Ustaw nazwy wierszy podczas importowania danych
#import CSV file and specify column to use as row names df <- read. csv (' my_data.csv ', row.names =' my_column ')
Poniższe przykłady pokazują, jak zastosować każdą metodę w praktyce.
Przykład 1: Zdefiniuj nazwy wierszy za pomocą Base R
Załóżmy, że mamy następującą ramkę danych w R:
#create data frame
df <- data. frame (ID=c(101, 102, 103, 104, 105),
points=c(99, 90, 86, 88, 95),
assists=c(33, 28, 31, 39, 34),
rebounds=c(30, 28, 24, 24, 28))
#view data frame
df
ID points assists rebounds
1 101 99 33 30
2 102 90 28 28
3 103 86 31 24
4 104 88 39 24
5 105 95 34 28
Możemy użyć poniższego kodu, aby ustawić kolumnę ID jako nazwy wierszy:
#set ID column as row names
rownames(df) <- df$ID
#remove original ID column from data frame
df$ID <- NULL
#view updated data frame
df
points assists rebounds
101 99 33 30
102 90 28 28
103 86 31 24
104 88 39 24
105 95 34 28
Wartości w kolumnie ID są teraz nazwami wierszy ramki danych.
Przykład 2: Ustaw nazwy wierszy za pomocą pakietu Tidyverse
Poniższy kod pokazuje, jak używać funkcji kolumny_to_rownames() pakietu spiceverse do ustawiania nazw wierszy równych kolumnie ID w ramce danych:
library (tidyverse)
#create data frame
df <- data. frame (ID=c(101, 102, 103, 104, 105),
points=c(99, 90, 86, 88, 95),
assists=c(33, 28, 31, 39, 34),
rebounds=c(30, 28, 24, 24, 28))
#set ID column as row names
df <- df %>% column_to_rownames(., var = ' ID ')
#view updated data frame
df
points assists rebounds
101 99 33 30
102 90 28 28
103 86 31 24
104 88 39 24
105 95 34 28
Należy zauważyć, że ten wynik jest zgodny z wynikiem z poprzedniego przykładu.
Przykład 3: Ustaw nazwy wierszy podczas importowania danych
Załóżmy, że mamy następujący plik CSV o nazwie my_data.csv :
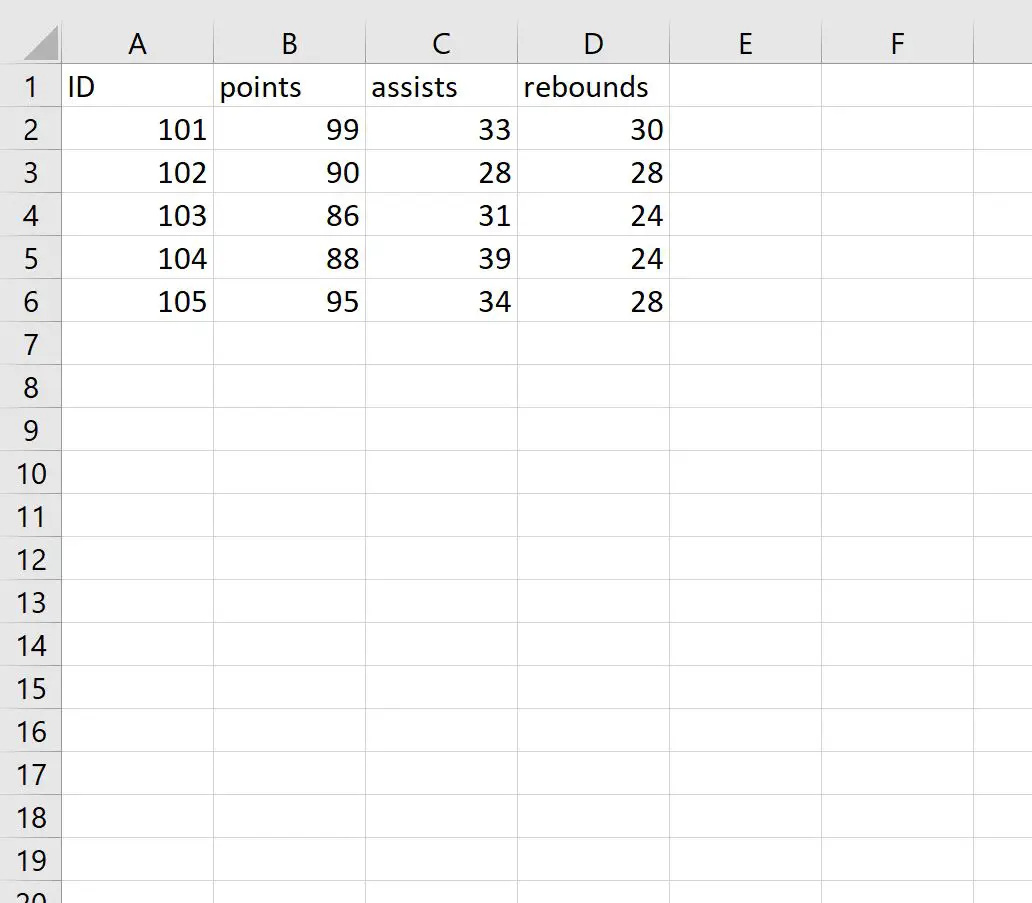
Możemy użyć poniższego kodu, aby zaimportować plik CSV i podczas importu ustawić nazwy wierszy tak, aby były równe kolumnie ID:
#import CSV file and specify ID column to use as row names df <- read. csv (' my_data.csv ', row.names =' ID ') #view data frame df points assists rebounds 101 99 33 30 102 90 28 28 103 86 31 24 104 88 39 24 105 95 34 28
Należy pamiętać, że wartości w kolumnie ID są używane jako nazwy wierszy w ramce danych.
Dodatkowe zasoby
Poniższe samouczki wyjaśniają, jak wykonywać inne typowe zadania w języku R:
Jak usunąć wiersze z ramki danych w R na podstawie warunku
Jak zamienić wartości w ramce danych w R
Jak usunąć kolumny z ramki danych w R
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej