Jak odczytać określone linie z pliku csv w r
Aby odczytać określone wiersze z pliku CSV w R, możesz użyć następujących metod:
Metoda 1: Zaimportuj plik CSV z określonego wiersza
df <- read. csv (" my_data.csv ", skip= 2 )
W tym konkretnym przykładzie pominięte zostaną pierwsze dwie linie pliku CSV i zaimportowane zostaną wszystkie pozostałe linie pliku, zaczynając od trzeciej linii.
Metoda 2: Zaimportuj plik CSV, w którym wiersze spełniają warunek
library (sqldf) df <- read. csv . sql (" my_data.csv ", sql = " select * from file where `points` > 90 ", eol = " \n ")
W tym konkretnym przykładzie zaimportowane zostaną tylko wiersze z pliku CSV, których wartość w kolumnie „punkty” jest większa niż 90.
Poniższe przykłady pokazują, jak w praktyce wykorzystać każdą z tych metod z następującym plikiem CSV o nazwie my_data.csv :
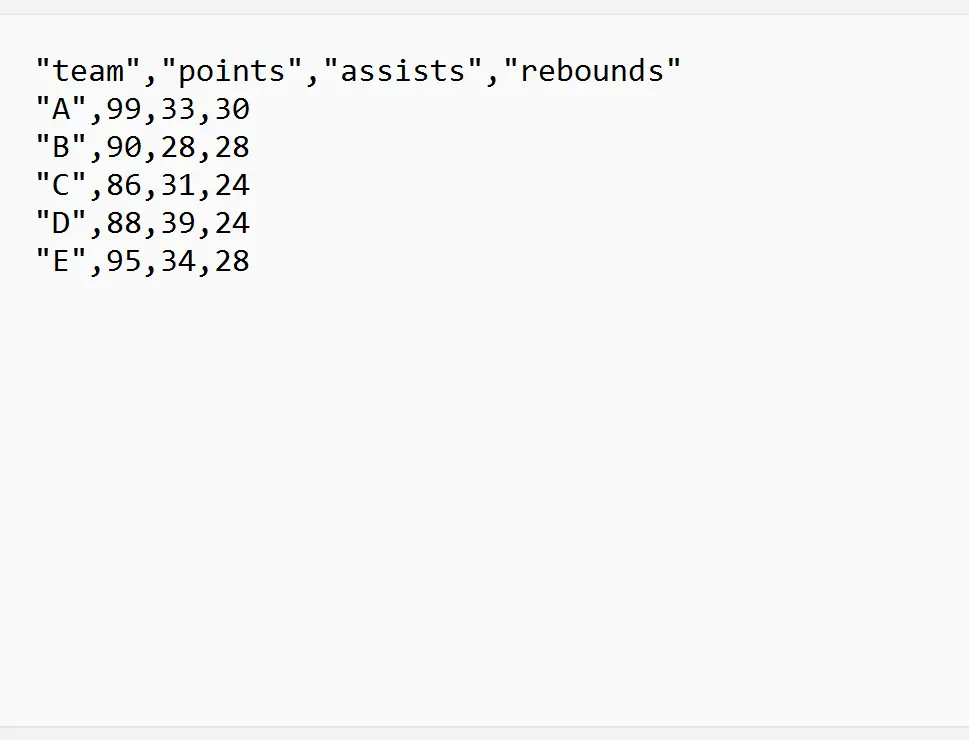
Przykład 1: Importuj plik CSV z określonego wiersza
Poniższy kod pokazuje, jak zaimportować plik CSV i zignorować pierwsze dwie linie pliku:
#import data frame and skip first two rows
df <- read. csv (' my_data.csv ', skip= 2 )
#view data frame
df
B X90 X28 X28.1
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
Należy pamiętać, że pierwsze dwie linijki (z drużynami A i B) zostały zignorowane podczas importowania pliku CSV.
Domyślnie R próbuje użyć wartości następnego dostępnego wiersza jako nazw kolumn.
Aby zmienić nazwę kolumn, możesz użyć funkcji Names() w następujący sposób:
#rename columns
names(df) <- c(' team ', ' points ', ' assists ', ' rebounds ')
#view updated data frame
df
team points assists rebounds
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
Przykład 2: Zaimportuj plik CSV, w którym wiersze spełniają warunek
Załóżmy, że chcemy zaimportować z pliku CSV tylko te wiersze, których wartość w kolumnie punktów jest większa niż 90.
Możemy w tym celu użyć funkcji read.csv.sql z pakietu sqldf :
library (sqldf)
#only import rows where points > 90
df <- read. csv . sql (" my_data.csv ",
sql = " select * from file where `points` > 90 ", eol = " \n ")
#view data frame
df
team points assists rebounds
1 “A” 99 33 30
2 “E” 95 34 28
Należy pamiętać, że zaimportowane zostały tylko dwie linie pliku CSV, których wartość w kolumnie „punkty” jest większa niż 90.
Uwaga nr 1 : W tym przykładzie użyliśmy argumentu eol , aby określić, że „koniec linii” w pliku jest oznaczony przez \n , który reprezentuje nową linię.
Uwaga nr 2: W tym przykładzie użyliśmy prostego zapytania SQL, ale możesz napisać bardziej złożone zapytania, aby filtrować wiersze według jeszcze większej liczby warunków.
Dodatkowe zasoby
Poniższe samouczki wyjaśniają, jak wykonywać inne typowe zadania w języku R:
Jak odczytać plik CSV z adresu URL w R
Jak połączyć wiele plików CSV w R
Jak wyeksportować ramkę danych do pliku CSV w R
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej