Kompletny przewodnik po zestawie danych diamentowych w r
Zestaw danych diamentu to zestaw danych wbudowany w pakiet ggplot2 w języku R.
Zawiera pomiary 10 różnych zmiennych (takich jak cena, kolor, klarowność itp.) dla 53 940 różnych diamentów.
W tym samouczku wyjaśniono, jak eksplorować, podsumowywać i wizualizować zestaw danych diamentowych w języku R.
Załaduj zestaw danych diamentu
Ponieważ zestaw danych Diamond jest wbudowanym zestawem danych w ggplot2, musimy najpierw zainstalować (jeśli jeszcze nie) i załadować pakiet ggplot2:
#install ggplot2 if not already installed
install. packages (' ggplot2 ')
#load ggplot2
library (ggplot2)
Po załadowaniu ggplot2 możemy użyć funkcji data() , aby załadować zestaw danych rombu :
data(diamonds)
Możemy przyjrzeć się pierwszym sześciu wierszom zbioru danych za pomocą funkcji head() :
#view first six rows of diamonds dataset
head(diamonds)
carat cut color clarity depth table price xyz
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
Podsumuj zbiór danych diamentów
Możemy użyć funkcji podsumowania() , aby szybko podsumować każdą zmienną w zbiorze danych:
#summarize diamonds dataset
summary(diamonds)
carat cut color clarity depth
Min. :0.2000 Fair: 1610 D: 6775 SI1:13065 Min. :43.00
1st Qu.:0.4000 Good: 4906 E: 9797 VS2:12258 1st Qu.:61.00
Median: 0.7000 Very Good: 12082 F: 9542 SI2: 9194 Median: 61.80
Mean: 0.7979 Premium: 13791 G: 11292 VS1: 8171 Mean: 61.75
3rd Qu.:1.0400 Ideal:21551 H:8304 VVS2:5066 3rd Qu.:62.50
Max. :5.0100 I: 5422 VVS1: 3655 Max. :79.00
D: 2808 (Other): 2531
table price xyz Min. :43.00 Min. : 326 Min. : 0.000 Min. : 0.000 Min. : 0.000
1st Qu.: 56.00 1st Qu.: 950 1st Qu.: 4.710 1st Qu.: 4.720 1st Qu.: 2.910
Median: 57.00 Median: 2401 Median: 5.700 Median: 5.710 Median: 3.530
Mean: 57.46 Mean: 3933 Mean: 5.731 Mean: 5.735 Mean: 3.539
3rd Qu.: 59.00 3rd Qu.: 5324 3rd Qu.: 6.540 3rd Qu.: 6.540 3rd Qu.: 4.040
Max. :95.00 Max. :18823 Max. :10,740 Max. :58,900 Max. :31,800
Dla każdej ze zmiennych numerycznych możemy zobaczyć następujące informacje:
- Min .: Wartość minimalna.
- 1. Qu : Wartość pierwszego kwartyla (25. percentyl).
- Mediana : Wartość mediana.
- Średnia : Wartość średnia.
- 3rd Qu : Wartość trzeciego kwartyla (75. percentyl).
- Maks .: Wartość maksymalna.
W przypadku zmiennych kategorycznych w zbiorze danych (krój, kolor i przejrzystość) widzimy częstotliwość każdej wartości.
Na przykład dla zmiennej wycinającej :
- Dostateczna : ta wartość pojawia się 1610 razy.
- Dobrze : ta wartość pojawia się 4906 razy.
- Bardzo dobrze : ta wartość pojawia się 12 082 razy.
- Premium : ta wartość pojawia się 13 791 razy.
- Idealnie : ta wartość pojawia się 21 551 razy.
Możemy użyć funkcji dim() , aby uzyskać wymiary zbioru danych pod względem liczby wierszy i kolumn:
#display rows and columns
dim(diamonds)
[1] 53940 10
Widzimy, że zbiór danych ma 53 940 wierszy i 10 kolumn.
Możemy również użyć funkcji Names() do wyświetlenia nazw kolumn ramki danych:
#display column names
names(diamonds)
[1] "carat" "cut" "color" "clarity" "depth" "table" "price" "x"
[9] “y” “z”
Wizualizuj zbiór danych diamentów
Możemy także tworzyć wykresy w celu wizualizacji wartości zbioru danych.
Na przykład możemy użyć funkcji geom_histogram() do stworzenia histogramu wartości określonej zmiennej:
#create histogram of values for price
ggplot(data=diamonds, aes (x=price)) +
geom_histogram(fill=" steelblue ", color=" black ") +
ggtitle(" Histogram of Price Values ")
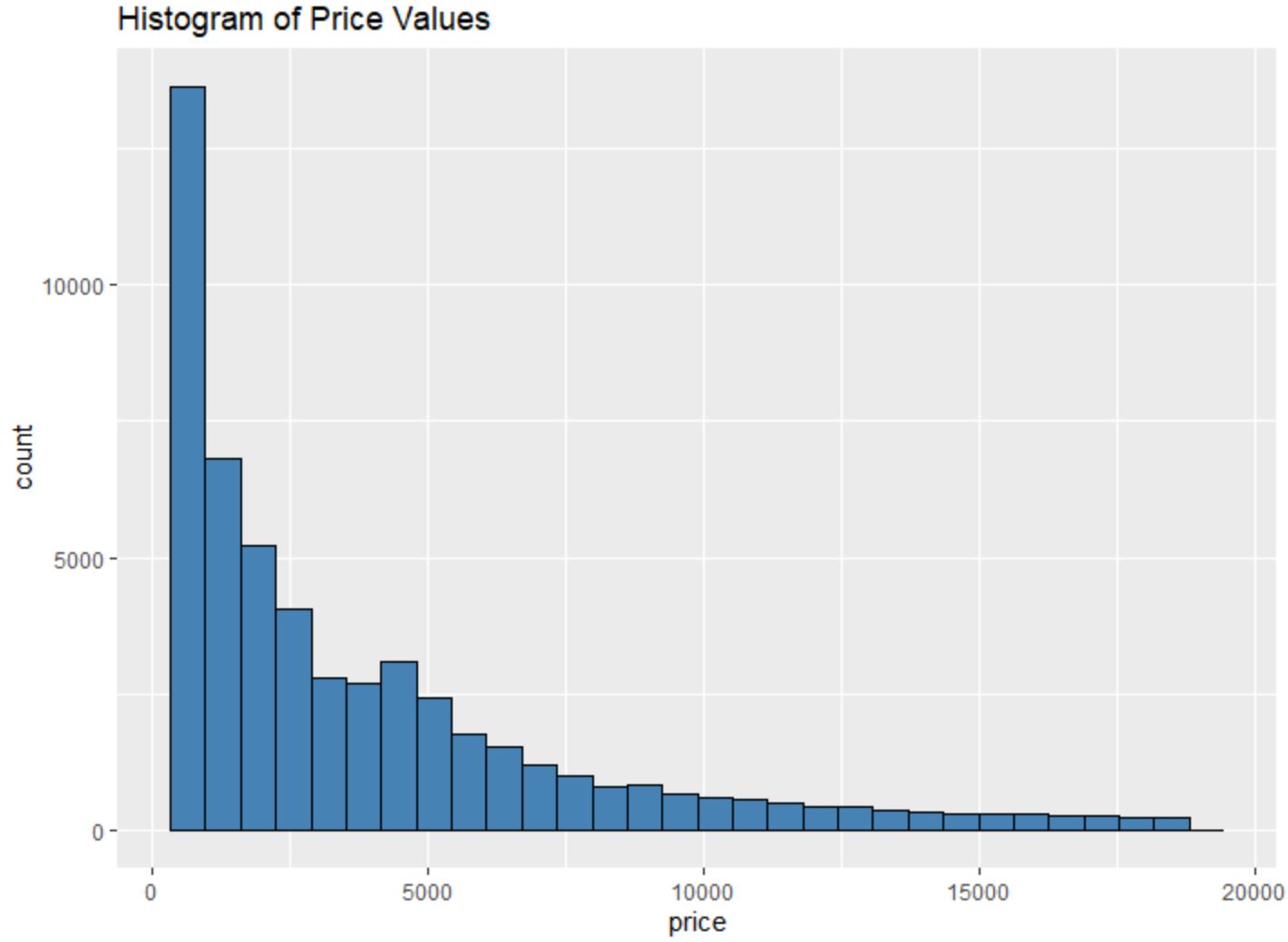
Możemy również użyć funkcji geom_point() do stworzenia chmury punktów dowolnej kombinacji parami zmiennych:
#create scatterplot of carat vs. price, using cut as color variable
ggplot(data=diamonds, aes (x=carat, y=price, color=cut)) +
geom_point()
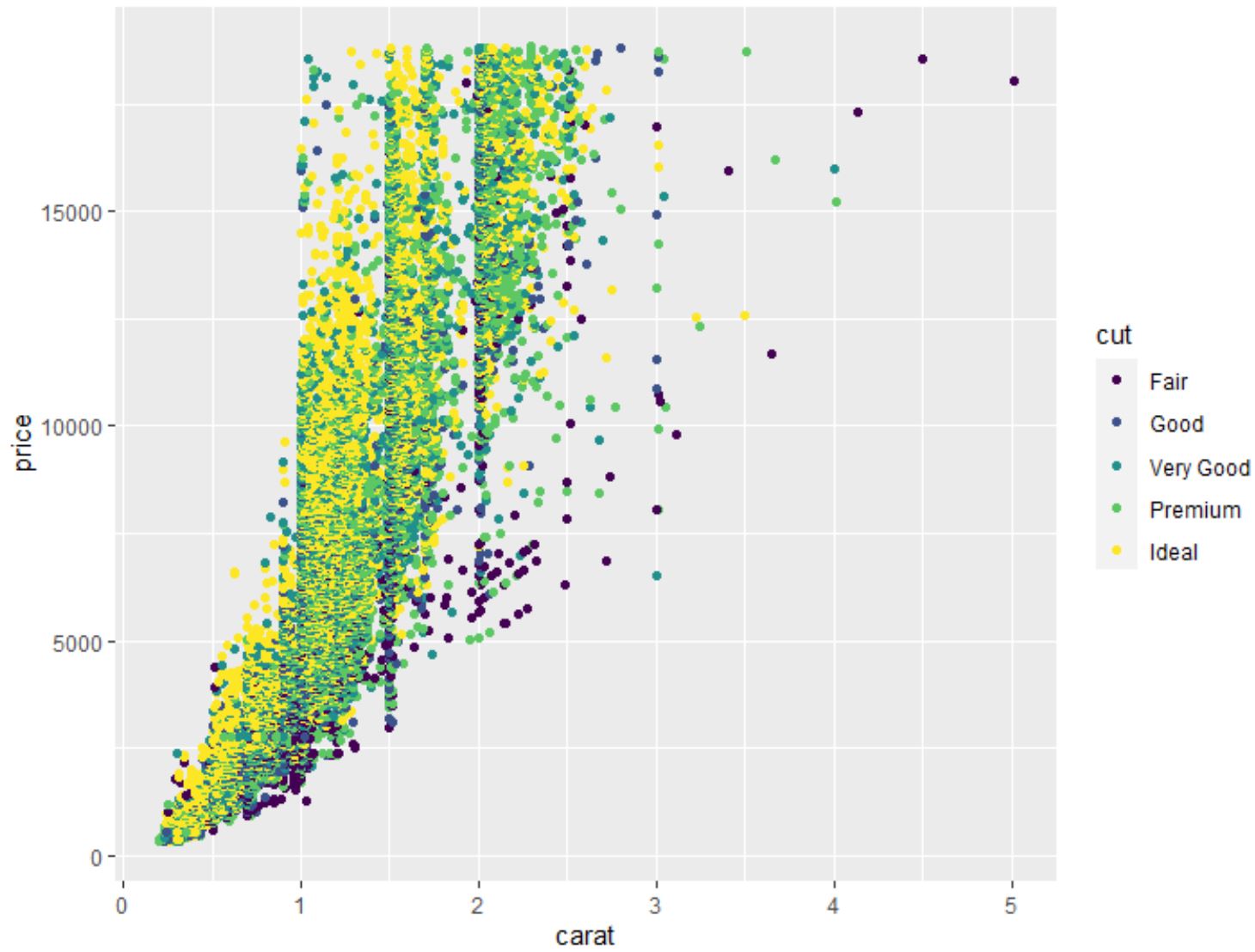
Możemy także użyć funkcji geom_boxplot() , aby utworzyć wykres pudełkowy zmiennej pogrupowanej według innej zmiennej:
#create scatterplot of price, grouped by cut
ggplot(data=diamonds, aes (x=cut, y=price)) +
geom_boxplot(fill=" steelblue ")
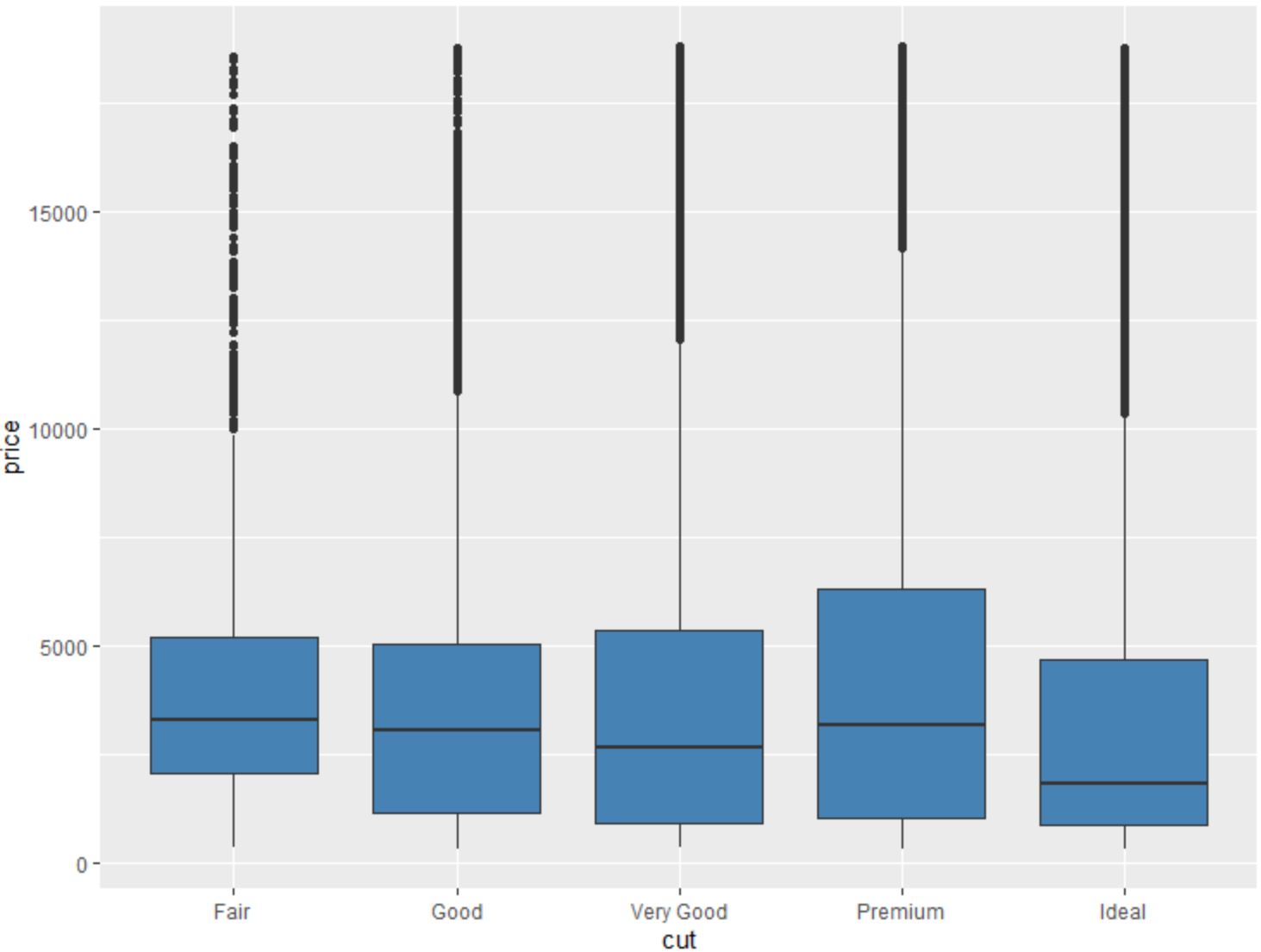
Korzystając z tych funkcji ggplot2, możemy dowiedzieć się wiele o zmiennych w zbiorze danych rombu .
Dodatkowe zasoby
Poniższe samouczki wyjaśniają, jak eksplorować inne zbiory danych w R:
Kompletny przewodnik po zbiorze danych Iris w R
Kompletny przewodnik po zbiorze danych mtcars w R
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej