Jak wykreślić rozkład wartości kolumn w pandach
Możesz użyć następujących metod, aby wykreślić rozkład wartości kolumn w pandzie DataFrame:
Metoda 1: Wykreśl rozkład wartości w kolumnie
df[' my_column ']. plot (kind=' kde ')
Metoda 2: Wykreśl rozkład wartości w jednej kolumnie, pogrupowanych według innej kolumny
df. groupby (' group_column ')[' values_column ']. plot (kind=' kde ')
Poniższe przykłady pokazują, jak w praktyce używać każdej metody z następującą ramką DataFrame pand:
import pandas as pd #createDataFrame df = pd. DataFrame ({' team ': ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B'], ' points ': [3, 3, 4, 5, 4, 7, 7, 7, 10, 11, 8, 7, 8, 9, 12, 12, 12, 14, 15, 17]}) #view DataFrame print (df) team points 0 to 3 1 to 3 2 to 4 3 to 5 4 to 4 5 TO 7 6 to 7 7 to 7 8 to 10 9 to 11 10 B 8 11 B 7 12 B 8 13 B 9 14 B 12 15 B 12 16 B 12 17 B 14 18 B 15 19 B 17
Przykład 1: Wykreśl rozkład wartości w kolumnie
Poniższy kod pokazuje jak wykreślić rozkład wartości w kolumnie punktów :
#plot distribution of values in points column df[' points ']. plot (kind=' kde ')
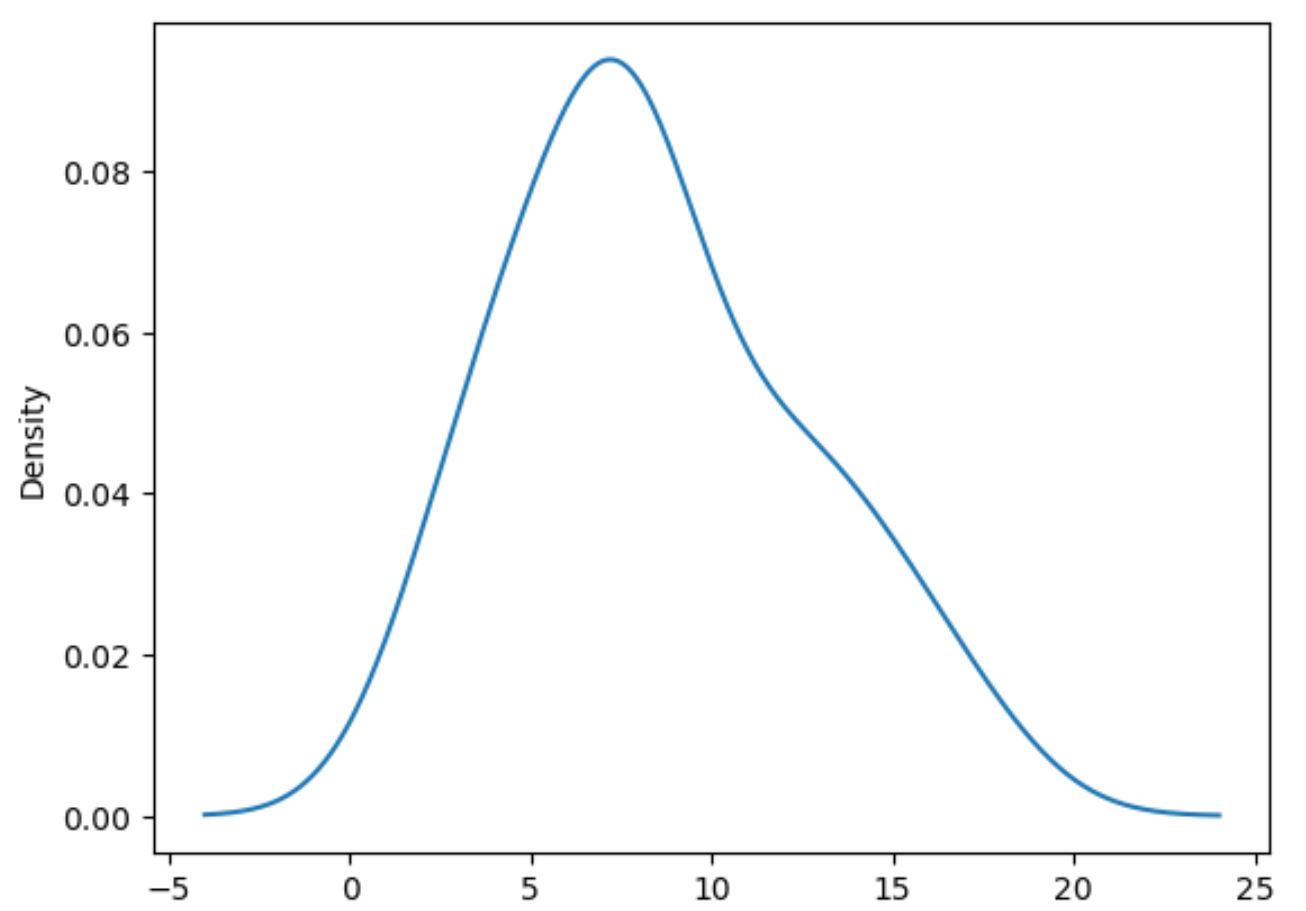
Zauważ, że kind=’kde’ mówi pandom, aby użyły szacowania gęstości jądra , co daje gładką krzywą podsumowującą rozkład wartości zmiennej.
Jeśli zamiast tego chcesz utworzyć histogram, możesz określić kind=’hist’ w następujący sposób:
#plot distribution of values in points column using histogram df[' points ']. plot (kind=' hist ', edgecolor=' black ')
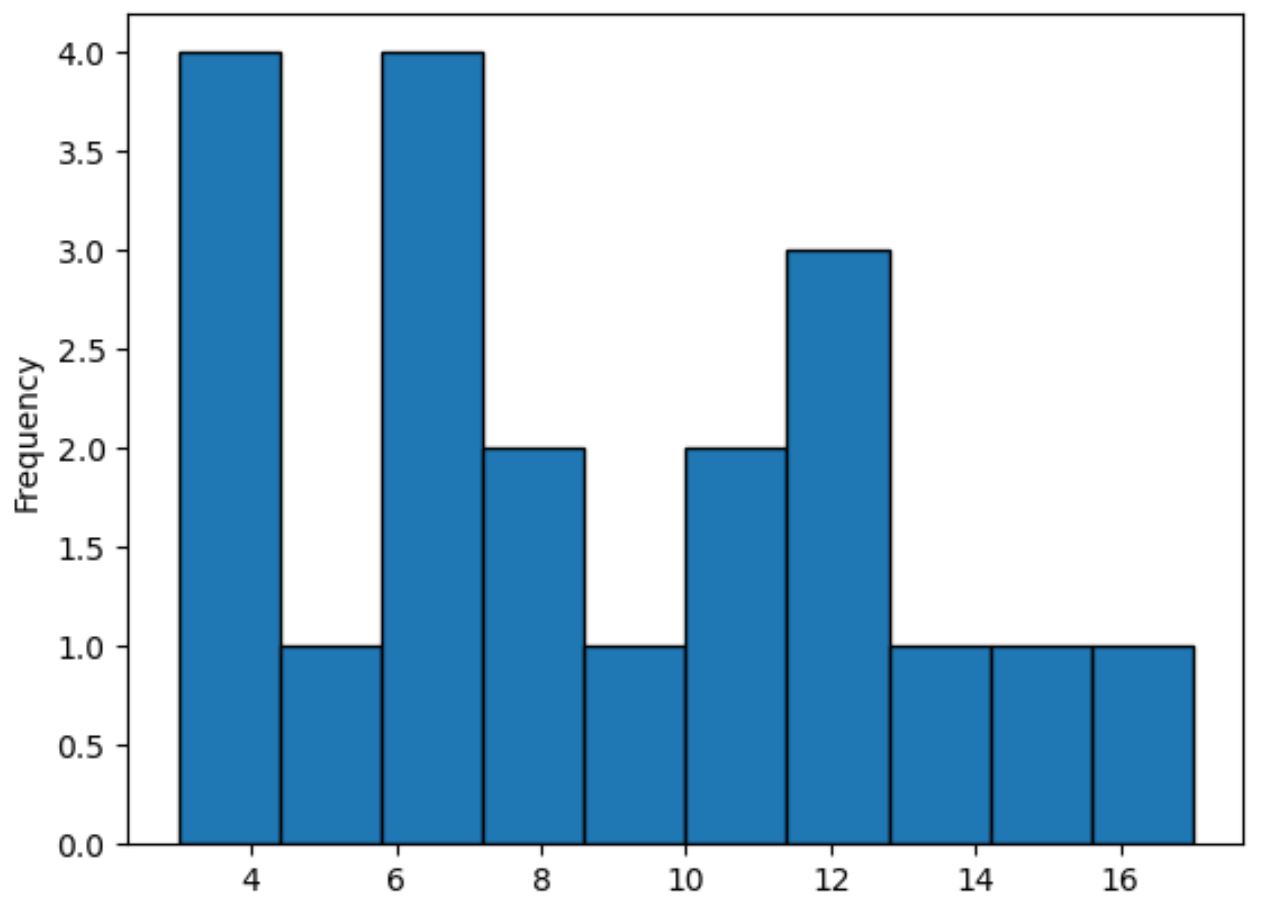
Metoda ta wykorzystuje słupki do przedstawienia częstotliwości wartości w kolumnie punktów , w przeciwieństwie do gładkiej linii, która podsumowuje kształt rozkładu.
Przykład 2: Wykreśl rozkład wartości w jednej kolumnie, pogrupowanych według innej kolumny
Poniższy kod pokazuje jak wykreślić rozkład wartości w kolumnie punktów , pogrupowanych według kolumny zespołu :
import matplotlib.pyplot as plt #plot distribution of points by team df. groupby (' team ')[' points ']. plot (kind=' kde ') #add legend plt. legend ([' A ',' B '], title=' Team ') #add x-axis label plt. xlabel (' Points ')
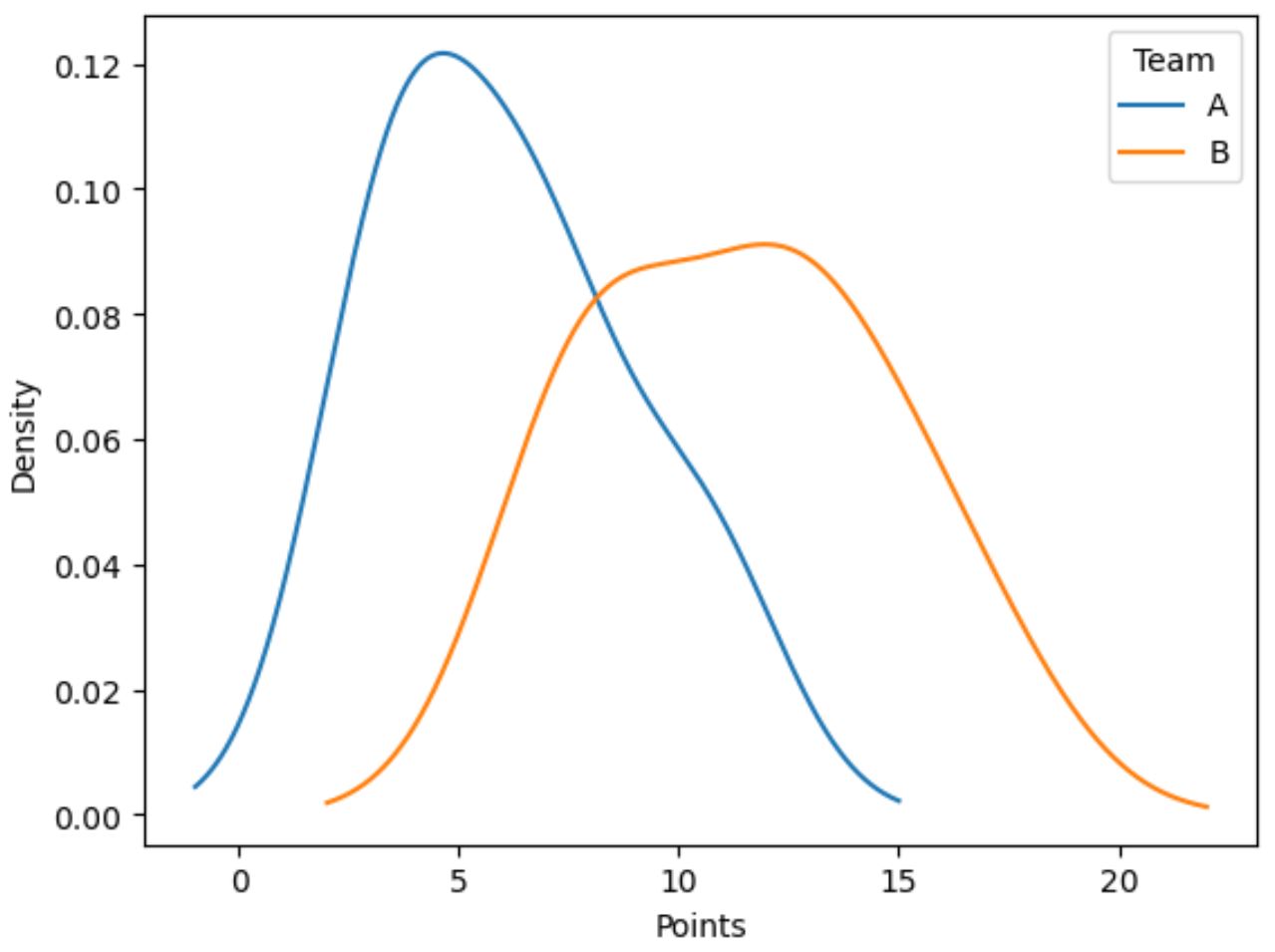
Niebieska linia pokazuje rozkład punktów zawodników drużyny A, natomiast pomarańczowa linia pokazuje rozkład punktów zawodników drużyny B.
Dodatkowe zasoby
Poniższe samouczki wyjaśniają, jak wykonywać inne typowe zadania w pandach:
Jak dodać tytuły do działek w Pandach
Jak dostosować rozmiar figury na wykresie pandy
Jak wykreślić wiele ramek danych Pand w wykresach podrzędnych
Jak tworzyć i dostosowywać legendy fabuły w Pandach
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej