Jak korzystać z najmniejszej znaczącej różnicy fishera (lsd) w r
Jednoczynnikową ANOVA stosuje się do określenia, czy istnieje statystycznie istotna różnica pomiędzy średnimi z trzech lub więcej niezależnych grup.
Założenia stosowane w jednokierunkowej ANOVA są następujące:
- H 0 : Średnie są równe dla każdej grupy.
- H A : Przynajmniej jeden ze sposobów różni się od pozostałych.
Jeśli wartość p analizy ANOVA jest poniżej pewnego poziomu istotności (takiego jak α = 0,05), możemy odrzucić hipotezę zerową i stwierdzić, że przynajmniej jedna ze średnich grupowych różni się od pozostałych.
Aby jednak dokładnie wiedzieć, które grupy się od siebie różnią, musimy przeprowadzić test post hoc.
Powszechnie stosowanym testem post hoc jest test najmniejszej znaczącej różnicy Fishera (LSD) .
Aby wykonać ten test w R, możesz użyć funkcji LSD.test() z pakietu agricolae .
Poniższy przykład pokazuje, jak w praktyce wykorzystać tę funkcję.
Przykład: test Fishera na LSD w R
Załóżmy, że profesor chce wiedzieć, czy trzy różne techniki uczenia się prowadzą do różnych wyników testów wśród studentów.
Aby to sprawdzić, losowo przydziela 10 uczniów do stosowania każdej techniki uczenia się i rejestruje wyniki ich egzaminów.
Poniższa tabela przedstawia wyniki egzaminów każdego ucznia w oparciu o zastosowaną technikę nauki:
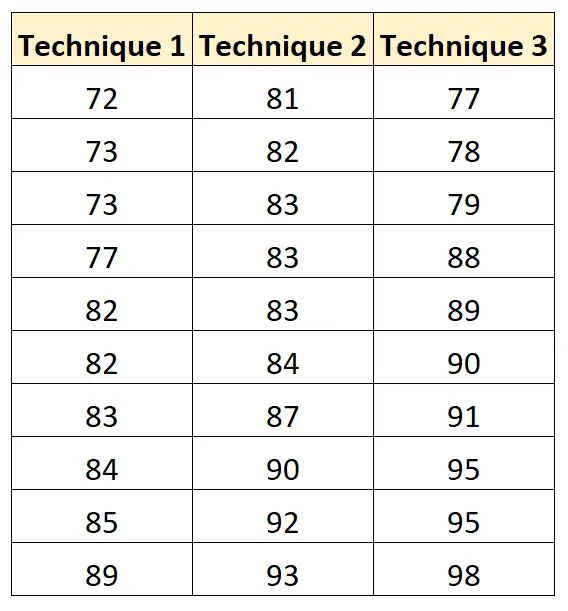
Możemy użyć następującego kodu, aby utworzyć ten zbiór danych i wykonać na nim jednokierunkową analizę ANOVA w R:
#create data frame
df <- data. frame (technique = rep(c("tech1", "tech2", "tech3"), each = 10 ),
score = c(72, 73, 73, 77, 82, 82, 83, 84, 85, 89,
81, 82, 83, 83, 83, 84, 87, 90, 92, 93,
77, 78, 79, 88, 89, 90, 91, 95, 95, 98))
#view first six rows of data frame
head(df)
technical score
1 tech1 72
2 tech1 73
3 tech1 73
4 tech1 77
5 tech1 82
6 tech1 82
#fit one-way ANOVA
model <- aov(score ~ technique, data = df)
#view summary of one-way ANOVA
summary(model)
Df Sum Sq Mean Sq F value Pr(>F)
technical 2 341.6 170.80 4.623 0.0188 *
Residuals 27,997.6 36.95
---
Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Ponieważ wartość p w tabeli ANOVA (0,0188) jest mniejsza niż 0,05, możemy stwierdzić, że wszystkie średnie wyniki egzaminów pomiędzy trzema grupami nie są równe.
W ten sposób możemy przeprowadzić test LSD Fishera, aby określić, które średnie grupowe są różne.
Poniższy kod pokazuje, jak to zrobić:
library (agricolae)
#perform Fisher's LSD
print( LSD.test (model," technic "))
$statistics
MSerror Df Mean CV t.value LSD
36.94815 27 84.6 7.184987 2.051831 5.57767
$parameters
test p.adjusted name.t ntr alpha
Fisher-LSD none technical 3 0.05
$means
std score r LCL UCL Min Max Q25 Q50 Q75
tech1 80.0 5.868939 10 76.05599 83.94401 72 89 74.00 82.0 83.75
tech2 85.8 4.391912 10 81.85599 89.74401 81 93 83.00 83.5 89.25
tech3 88.0 7.557189 10 84.05599 91.94401 77 98 81.25 89.5 94.00
$comparison
NULL
$groups
score groups
tech3 88.0 a
tech2 85.8a
tech1 80.0 b
attr(,"class")
[1] “group”
Częścią wyniku, która nas najbardziej interesuje, jest sekcja o nazwie $groups . Techniki, które mają różne znaki w kolumnie grup , są bardzo różne.
Z wyniku możemy zobaczyć:
- Technika 1 i Technika 3 mają znacząco różne średnie wyniki egzaminu (ponieważ technika 1 ma wartość „b”, a technika 3 ma wartość „a”).
- Technika 1 i Technika 2 mają znacząco różne średnie wyniki egzaminu (ponieważ technika 1 ma wartość „b”, a technika 2 ma wartość „a”).
- Technika 2 i Technika 3 nie mają znacząco różnych średnich wyników egzaminu (ponieważ obie mają wartość „a”)
Dodatkowe zasoby
Poniższe samouczki wyjaśniają, jak wykonywać inne typowe zadania w języku R:
Jak wykonać jednokierunkową ANOVA w R
Jak wykonać test post hoc Bonferroniego u R
Jak wykonać test post-hoc Scheffe’a w R
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej