Jak używać instrukcji proc glmselect w sas-ie
Możesz użyć instrukcji PROC GLMSELECT w SAS-ie, aby wybrać najlepszy model regresji na podstawie listy potencjalnych zmiennych predykcyjnych.
Poniższy przykład pokazuje, jak używać tego stwierdzenia w praktyce.
Przykład: Jak używać PROC GLMSELECT w SAS-ie do wyboru modelu
Załóżmy, że chcemy dopasować model regresji liniowej, który wykorzystuje (1) liczbę godzin spędzonych na nauce, (2) liczbę zdanych egzaminów przygotowawczych i (3) płeć, aby przewidzieć egzamin końcowy uczniów.
Najpierw użyjemy następującego kodu, aby utworzyć zbiór danych zawierający te informacje dla 20 uczniów:
/*create dataset*/ data exam_data; input hours prep_exams gender $score; datalines ; 1 1 0 76 2 3 1 78 2 3 0 85 4 5 0 88 2 2 0 72 1 2 1 69 5 1 1 94 4 1 0 94 2 0 1 88 4 3 0 92 4 4 1 90 3 3 1 75 6 2 1 96 5 4 0 90 3 4 0 82 4 4 1 85 6 5 1 99 2 1 0 83 1 0 1 62 2 1 0 76 ; run ; /*view dataset*/ proc print data =exam_data;
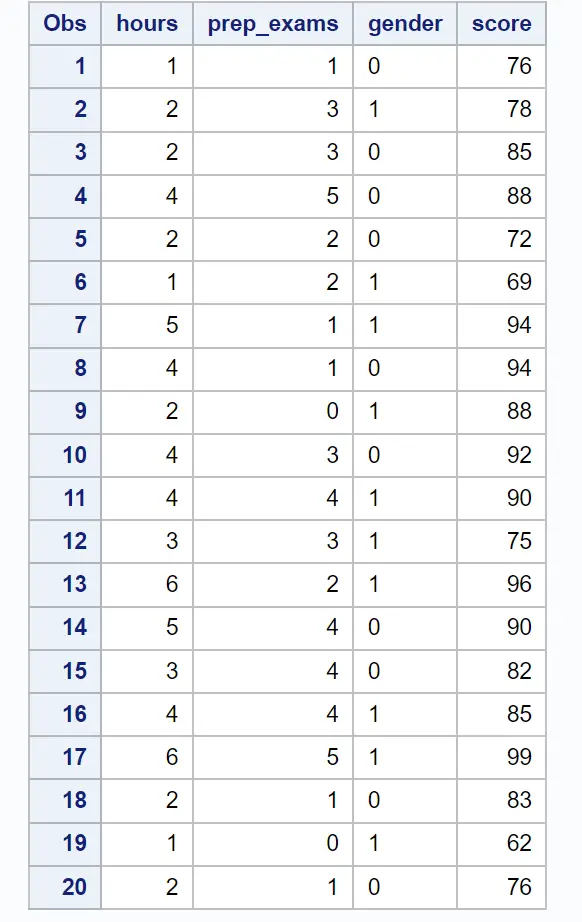
Następnie użyjemy instrukcji PROC GLMSELECT do zidentyfikowania podzbioru zmiennych predykcyjnych, który da najlepszy model regresji:
/*perform model selection*/
proc glmselect data =exam_data;
classgender ;
model score = hours prep_exams gender;
run ;
Uwaga : w stwierdzeniu klasy uwzględniliśmy płeć , ponieważ jest to zmienna kategoryczna.
Pierwsza grupa tabel w wynikach przedstawia przegląd procedury GLMSELECT:
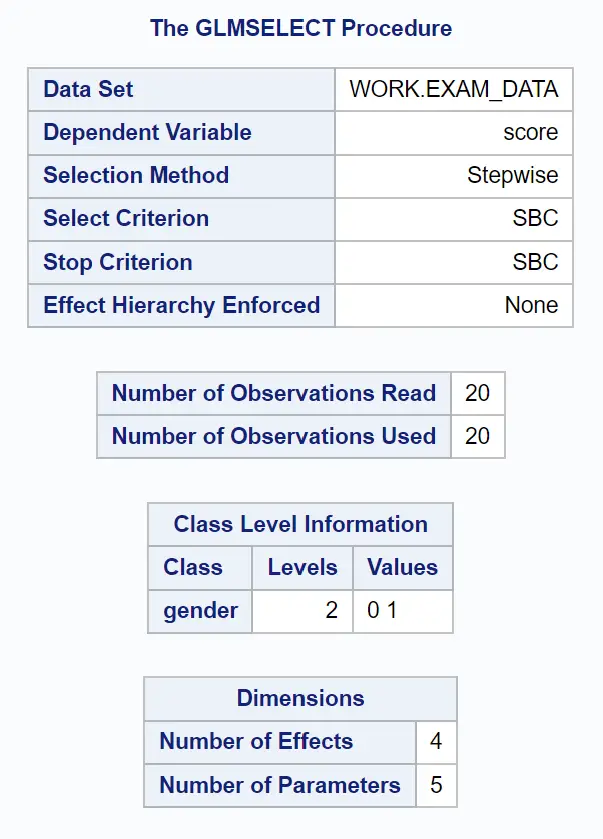
Widzimy, że kryterium stosowanym do zaprzestania dodawania lub usuwania zmiennych z modelu było SBC , czyli kryterium informacyjne Schwarza , czasami nazywane kryterium informacyjnym Bayesa .
Zasadniczo instrukcja PROC GLMSELECT kontynuuje dodawanie lub usuwanie zmiennych z modelu, aż znajdzie model o najniższej wartości SBC, który jest uważany za „najlepszy” model.
Poniższa grupa tabel pokazuje, jak zakończyła się selekcja krok po kroku:
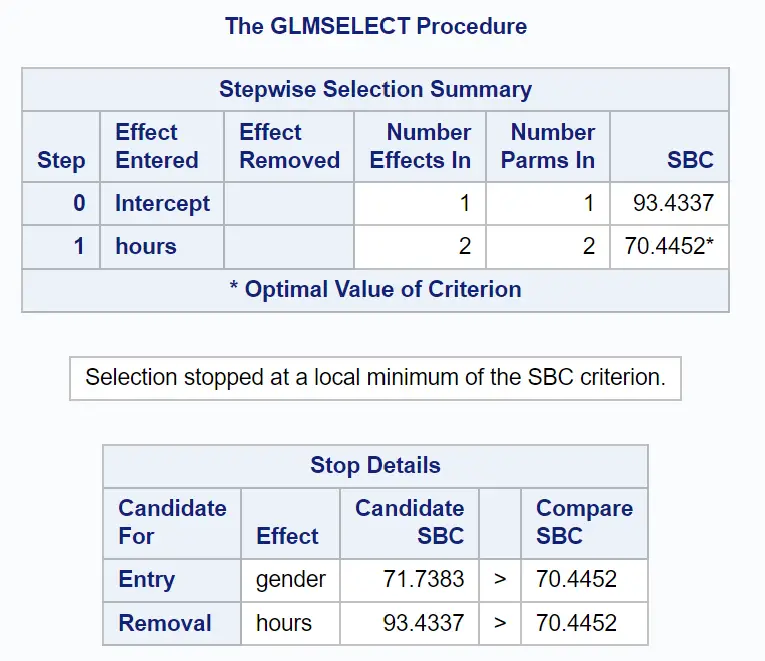
Widzimy, że model zawierający tylko pierwotny człon miał wartość SBC wynoszącą 93,4337 .
Dodając godziny jako zmienną predykcyjną w modelu, wartość SBC spadła do 70,4452 .
Najlepszym sposobem na ulepszenie modelu było dodanie płci jako zmiennej predykcyjnej, ale w rzeczywistości zwiększyło to wartość SBC do 71,7383.
Zatem ostateczny model uwzględnia jedynie człon wyrazu wolnego i badane czasy.
Ostatnia część wyniku przedstawia podsumowanie dopasowanego modelu regresji:
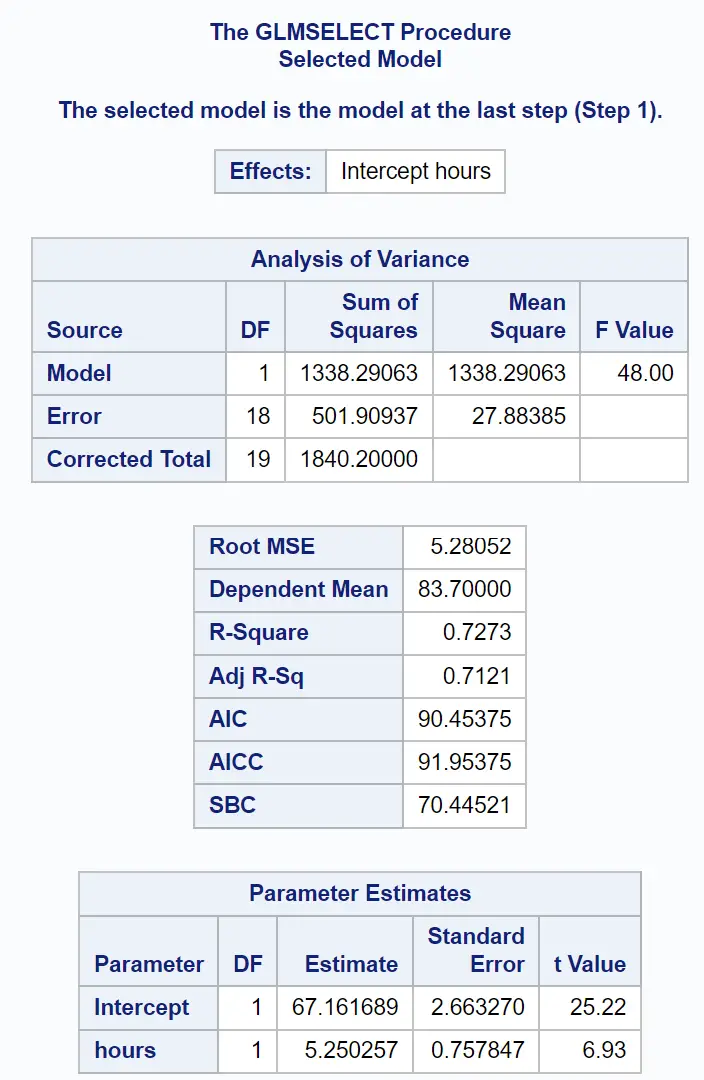
Możemy wykorzystać wartości z tabeli Oszacowania parametrów do napisania dopasowanego modelu regresji:
Wynik egzaminu = 67,161689 + 5,250257 (godziny nauki)
Możemy również zobaczyć różne metryki, które mówią nam, jak dobrze ten model pasuje do danych:
Wartość R-Square informuje nas o procentowym zróżnicowaniu wyników egzaminu, które można wytłumaczyć liczbą godzin nauki i liczbą zdanych egzaminów przygotowawczych.
W tym przypadku 72,73% różnic w wynikach egzaminów można wytłumaczyć liczbą przepracowanych godzin i liczbą zdanych egzaminów przygotowawczych.
Wartość Root MSE jest również przydatna. Stanowi to średnią odległość między obserwowanymi wartościami a linią regresji.
W tym modelu regresji zaobserwowane wartości odbiegają średnio o 5,28052 jednostki od linii regresji.
Uwaga : Pełną listę potencjalnych argumentów, których możesz użyć w PROC GLMSELECT, znajdziesz w dokumentacji SAS-a .
Dodatkowe zasoby
Poniższe samouczki wyjaśniają, jak wykonywać inne typowe zadania w SAS-ie:
Jak wykonać prostą regresję liniową w SAS-ie
Jak wykonać wielokrotną regresję liniową w SAS-ie
Jak wykonać regresję wielomianową w SAS-ie
Jak przeprowadzić regresję logistyczną w SAS-ie
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej