Jak wykonać skalowanie wielowymiarowe w pythonie
W statystyce skalowanie wielowymiarowe jest sposobem na wizualizację podobieństwa obserwacji w zbiorze danych w abstrakcyjnej przestrzeni kartezjańskiej (zwykle przestrzeni 2D).
Najłatwiejszym sposobem wykonania skalowania wielowymiarowego w Pythonie jest użycie funkcji MDS() podmodułu sklearn.manifold .
Poniższy przykład pokazuje, jak w praktyce wykorzystać tę funkcję.
Przykład: Skalowanie wielowymiarowe w Pythonie
Załóżmy, że mamy następującą ramkę danych pand, która zawiera informacje o różnych koszykarzach:
import pandas as pd #create DataFrane df = pd. DataFrame ({' player ': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K '], ' points ': [4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28], ' assists ': [3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11], ' blocks ': [7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1], ' rebounds ': [4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2]}) #set player column as index column df = df. set_index (' player ') #view Dataframe print (df) points assists blocks rebounds player A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
Możemy użyć poniższego kodu, aby wykonać skalowanie wielowymiarowe za pomocą funkcji MDS() modułu sklearn.manifold :
from sklearn. manifold import MDS
#perform multi-dimensional scaling
mds = MDS(random_state= 0 )
scaled_df = mds. fit_transform (df)
#view results of multi-dimensional scaling
print (scaled_df)
[[ 7.43654469 8.10247222]
[4.13193821 10.27360901]
[5.20534681 7.46919526]
[6.22323046 4.45148627]
[3.74110999 5.25591459]
[3.69073384 -2.88017811]
[3.89092087 -5.19100988]
[ -3.68593169 -3.0821144 ]
[ -9.13631889 -6.81016012]
[ -8.97898385 -8.50414387]
[-12.51859044 -9.08507097]]
Każdy wiersz oryginalnej ramki DataFrame został zredukowany do współrzędnej (x, y).
Możemy użyć poniższego kodu do wizualizacji tych współrzędnych w przestrzeni 2D:
import matplotlib.pyplot as plt #create scatterplot plt. scatter (scaled_df[:,0], scaled_df[:,1]) #add axis labels plt. xlabel (' Coordinate 1 ') plt. ylabel (' Coordinate 2 ') #add lables to each point for i, txt in enumerate( df.index ): plt. annotate (txt, (scaled_df[:,0][i]+.3, scaled_df[:,1][i])) #display scatterplot plt. show ()
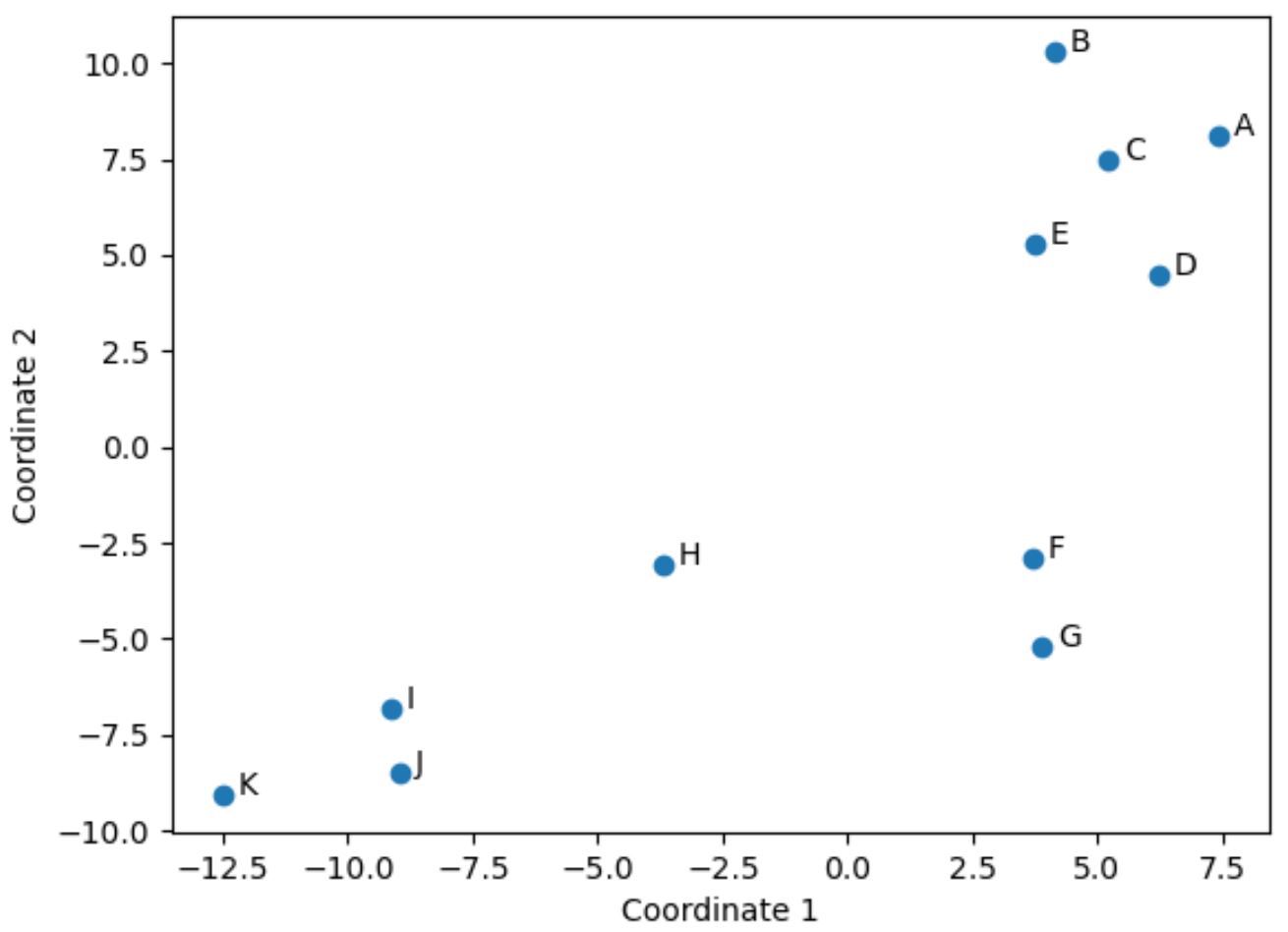
Gracze w oryginalnej DataFrame, którzy mają podobne wartości w oryginalnych czterech kolumnach (punkty, asysty, bloki i zbiórki), są blisko siebie w fabule.
Na przykład gracze F i G są ze sobą zamknięci. Oto ich wartości z oryginalnej DataFrame:
#select rows with index labels 'F' and 'G'
df. loc [[' F ',' G ']]
points assists blocks rebounds
player
F 14 8 8 8
G 16 7 8 10
Ich wartości punktów, asyst, bloków i zbiórek są dość podobne, co wyjaśnia, dlaczego są tak blisko siebie na wykresie 2D.
Dla kontrastu, rozważ graczy B i K , którzy są daleko od siebie w fabule.
Jeśli odniesiemy się do ich wartości w oryginalnej DataFrame, zobaczymy, że są one zupełnie inne:
#select rows with index labels 'B' and 'K'
df. loc [[' B ',' K ']]
points assists blocks rebounds
player
B 4 2 3 5
K 28 11 1 2
Zatem wykres 2D to dobry sposób na wizualizację podobieństwa każdego gracza we wszystkich zmiennych w DataFframe.
Gracze o podobnych statystykach są zgrupowani blisko siebie, podczas gdy gracze o bardzo różnych statystykach są dalej od siebie w fabule.
Dodatkowe zasoby
Poniższe samouczki wyjaśniają, jak wykonywać inne typowe zadania w Pythonie:
Jak normalizować dane w Pythonie
Jak usunąć wartości odstające w Pythonie
Jak przetestować normalność w Pythonie
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej