Jak obliczyć statystyki opisowe dla zmiennych w spss
Najlepszym sposobem zrozumienia zbioru danych jest obliczeniestatystyk opisowych dla zmiennych w zbiorze danych. Istnieją trzy popularne formy statystyki opisowej:
1. Statystyki podsumowujące – Liczby podsumowujące zmienną za pomocą pojedynczej liczby. Przykłady obejmują średnią, medianę, odchylenie standardowe i zakres.
2. Tabele – tabele mogą pomóc nam zrozumieć, w jaki sposób dane są dystrybuowane. Przykładem jest tabela częstości, która mówi nam, ile wartości danych mieści się w określonych zakresach.
3. Wykresy – pomagają nam wizualizować dane. Przykładem może być histogram .
W tym samouczku wyjaśniono, jak obliczać statystyki opisowe dla zmiennych w SPSS.
Przykład: statystyki opisowe w SPSS
Załóżmy, że mamy następujący zbiór danych zawierający cztery zmienne dla 20 uczniów w określonej klasie:
- Wynik egazminu
- Godziny spędzone na nauce
- Egzaminy przygotowawcze zaliczone
- Aktualna ocena w klasie
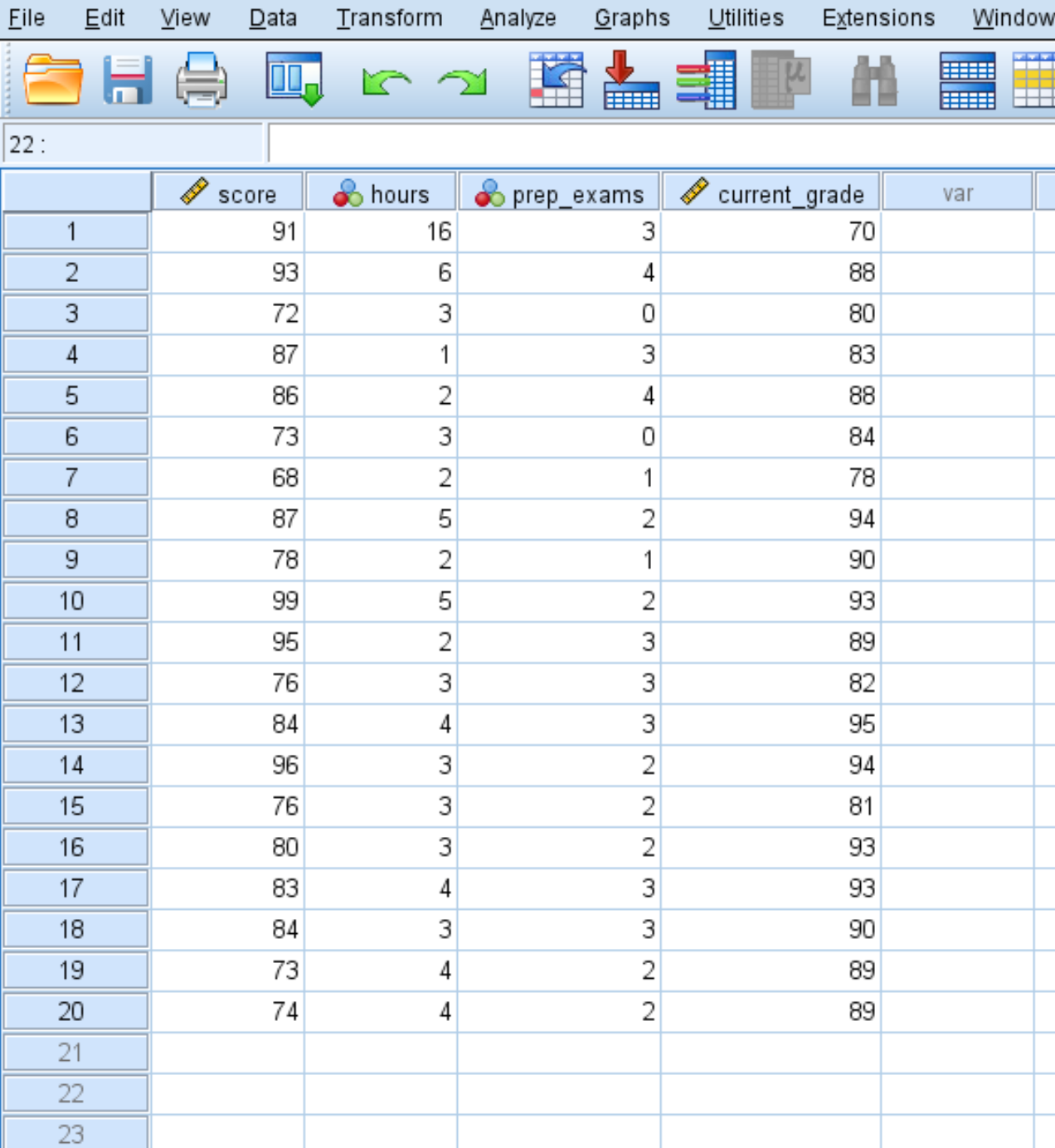
Oto jak obliczyć statystyki opisowe dla każdej z tych czterech zmiennych:
Statystyki podsumowujące
Aby obliczyć statystyki podsumowujące dla każdej zmiennej, kliknij kartę Analiza , następnie Statystyka opisowa , a następnie Opisowe :
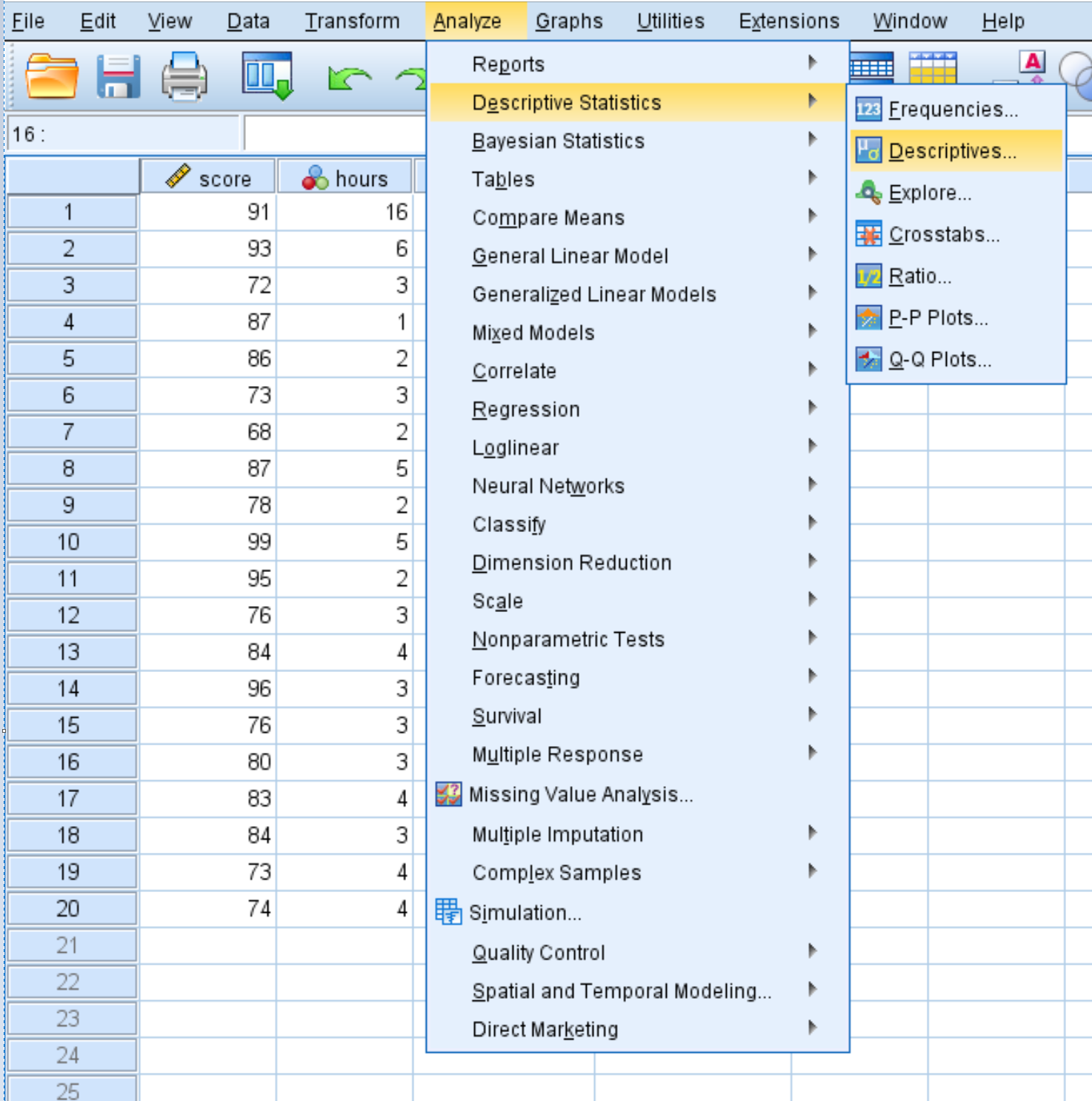
W nowym oknie, które się pojawi, przeciągnij każdą z czterech zmiennych do obszaru oznaczonego Zmienne. Jeśli chcesz, możesz kliknąć przycisk Opcje i wybrać konkretne statystyki opisowe, które SPSS ma obliczyć. Następnie kliknij Kontynuuj . Następnie kliknij OK .
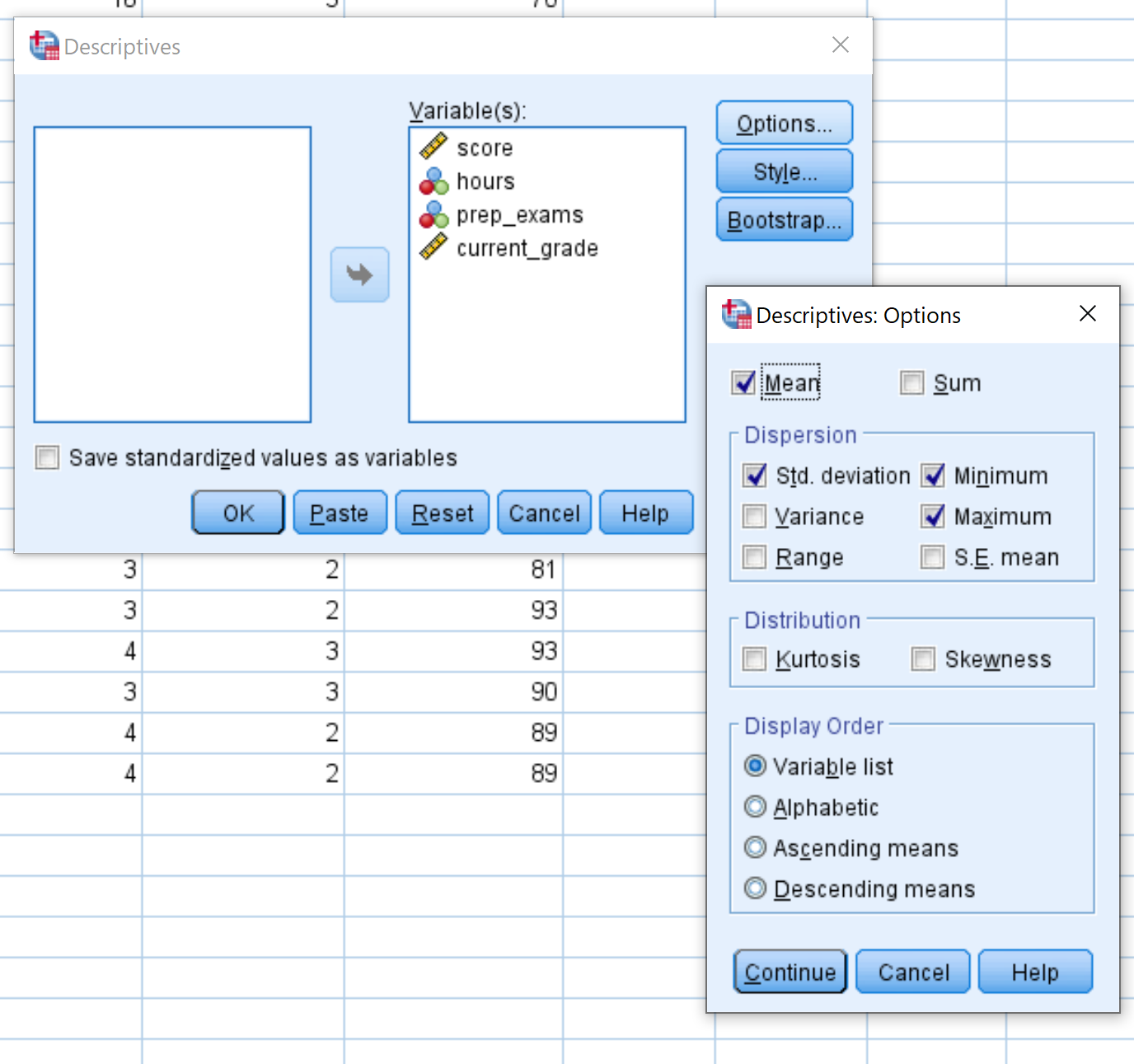
Po kliknięciu OK pojawi się tabela zawierająca następujące statystyki opisowe dla każdej zmiennej:
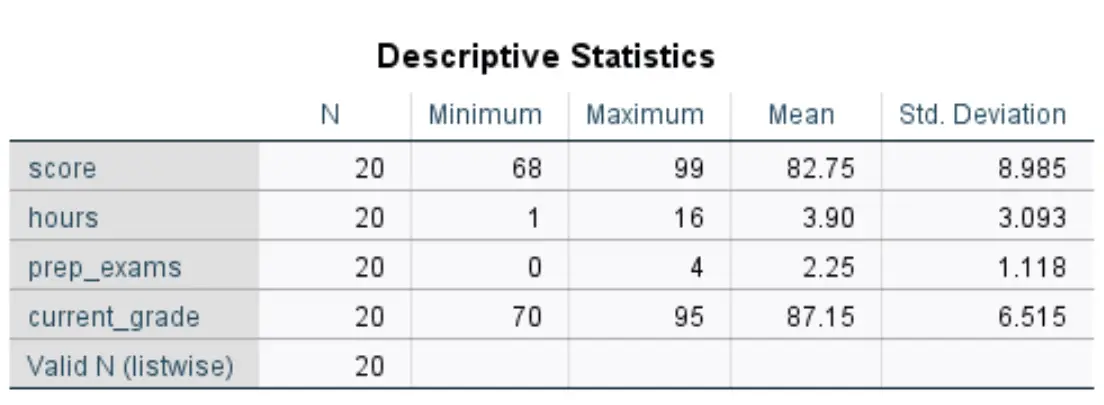
Oto jak interpretować liczby w tej tabeli dla zmiennej wynikowej :
- N: Całkowita liczba obserwacji. W tym przypadku jest ich 20.
- Minimum: Minimalna wartość wyniku egzaminu. W tym przypadku jest to 68.
- Maksimum: maksymalna wartość wyniku egzaminu. W tym przypadku jest to 99.
- Średnia: średni wynik na egzaminie. W tym przypadku jest to 82,75.
- Standard. Odchylenie: odchylenie standardowe wyników egzaminu. W tym przypadku jest to 8985.
Ta tabela pozwala nam szybko zrozumieć zakres każdej zmiennej (przy użyciu minimum i maksimum), centralną lokalizację każdej zmiennej (przy użyciu średniej) oraz rozkład wartości dla każdej zmiennej (przy użyciu odchylenia standardowego).
stoły
Aby utworzyć tabelę częstości dla każdej zmiennej, kliknij kartę Analiza , następnie Statystyka opisowa i Częstotliwości .
W nowym oknie, które się pojawi, przeciągnij każdą zmienną do pola o nazwie Zmienne. Następnie kliknij OK .
Pojawi się tabela częstości dla każdej zmiennej. Na przykład tutaj jest ten dla zmiennych godzin :
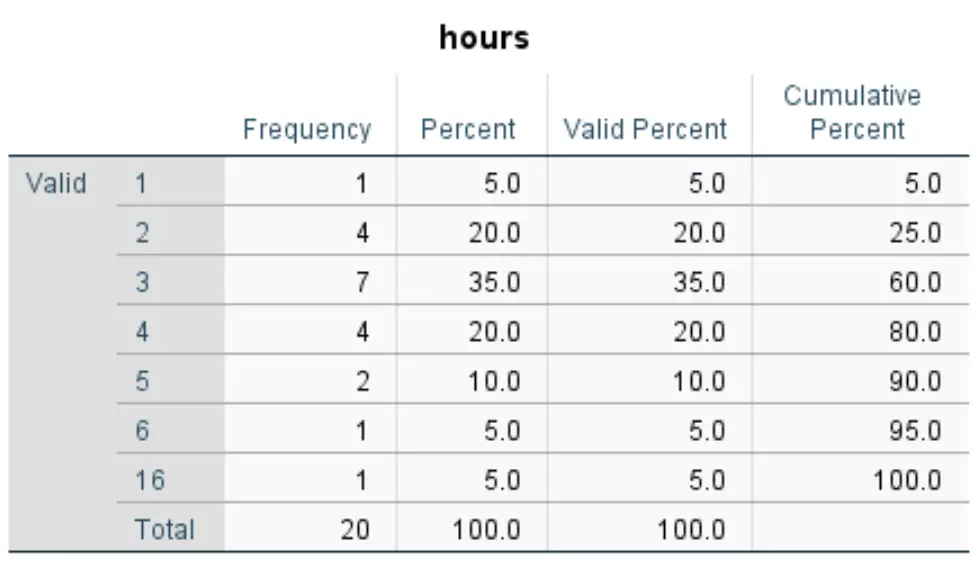
Sposób interpretacji tabeli jest następujący:
- Pierwsza kolumna wyświetla każdą unikalną wartość zmiennej godzin . W tym przypadku unikalne wartości to 1, 2, 3, 4, 5, 6 i 16.
- Druga kolumna wyświetla częstotliwość każdej wartości. Na przykład wartość 1 pojawia się 1 raz, wartość 2 pojawia się 4 razy i tak dalej.
- Trzecia kolumna wyświetla procent dla każdej wartości. Na przykład wartość 1 reprezentuje 5% wszystkich wartości w zbiorze danych. Wartość 2 reprezentuje 20% wszystkich wartości w zbiorze danych i tak dalej.
- Ostatnia kolumna wyświetla skumulowany procent. Na przykład wartości 1 i 2 razem reprezentują 25% całkowitego zbioru danych. Wartości 1, 2 i 3 reprezentują łącznie 60% zbioru danych i tak dalej.
Ta tabela daje nam dobry pogląd na rozkład wartości danych dla każdej zmiennej.
Grafika
Wykresy pomagają nam również zrozumieć rozkład wartości danych dla każdej zmiennej w zbiorze danych. Jednym z najpopularniejszych wykresów służących do tego celu jest histogram.
Aby utworzyć histogram dla danej zmiennej w zbiorze danych, kliknij kartę Wykresy , a następnie kliknij opcję Kreator wykresów .
W nowym oknie, które się pojawi, wybierz Histogram z panelu „Wybierz z”. Następnie przeciągnij pierwszą opcję histogramu do głównego okna edycji. Następnie przeciągnij interesującą Cię zmienną na oś x. W tym przykładzie użyjemy score . Następnie kliknij OK .
Po kliknięciu OK pojawi się histogram przedstawiający rozkład wartości wyniku zmiennej:
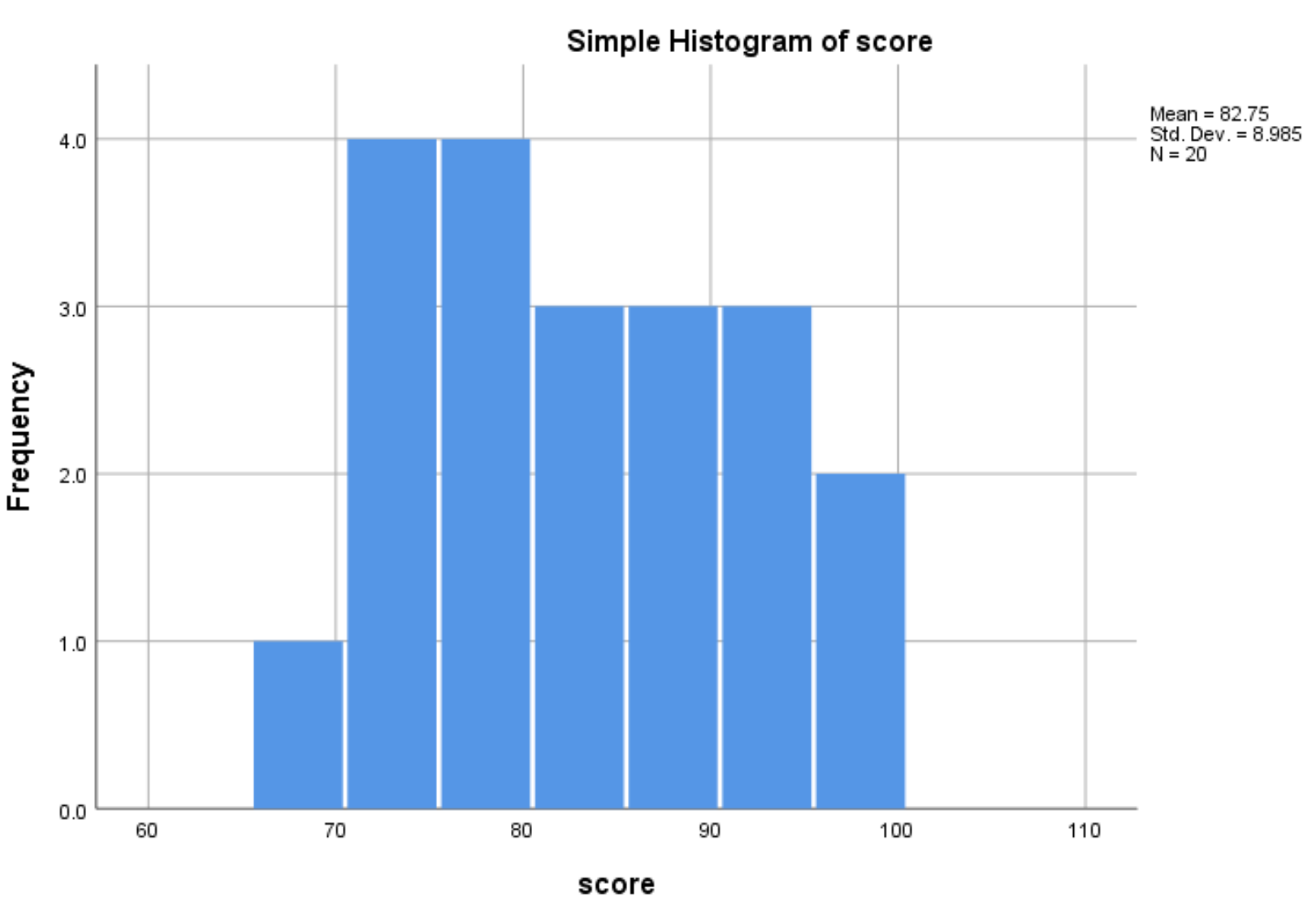
Histogram pokazuje, że zakres wyników egzaminu waha się od 65 do 100, a większość wyników mieści się w przedziale od 70 do 90.
Możemy również powtórzyć ten proces, aby utworzyć histogram dla każdej z pozostałych zmiennych w zbiorze danych.
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej