Tabela anova
W tym artykule znajdziesz wyjaśnienie tabeli ANOVA. Wyjaśnimy więc, czym jest tabela ANOVA, jak zrobić tabelę ANOVA, jakie są wzory tabeli ANOVA, a dodatkowo będziesz mógł zobaczyć krok po kroku rozwiązane ćwiczenie.
Co to jest tabela ANOVA?
Tabela ANOVA jest tabelą stosowaną w statystyce w analizie wariancji. Mówiąc dokładniej, tabela ANOVA zawiera wszystkie informacje niezbędne do analizy wariancji.
Dlatego tabela ANOVA służy do podsumowania analizy wariancji. Wykreślając obliczenia analizy wariancji w tabeli, można łatwo wyciągnąć wnioski, a także pozwolić na szybkie obliczenie wartości statystyki testu ANOVA.
Wzory tabelaryczne ANOVA
W jednoczynnikowej tabeli ANOVA znajdują się trzy wiersze: współczynnik, błąd i suma. Zatem w tabeli ANOVA obliczane są sumy kwadratów każdego wiersza i ich stopnie swobody. Dodatkowo obliczany jest błąd średniokwadratowy współczynnika i błąd, a na koniec wyznaczana jest statystyka testu ANOVA, która jest równa stosunkowi kwadratów błędów.
Wzory tabeli ANOVA są zatem następujące:
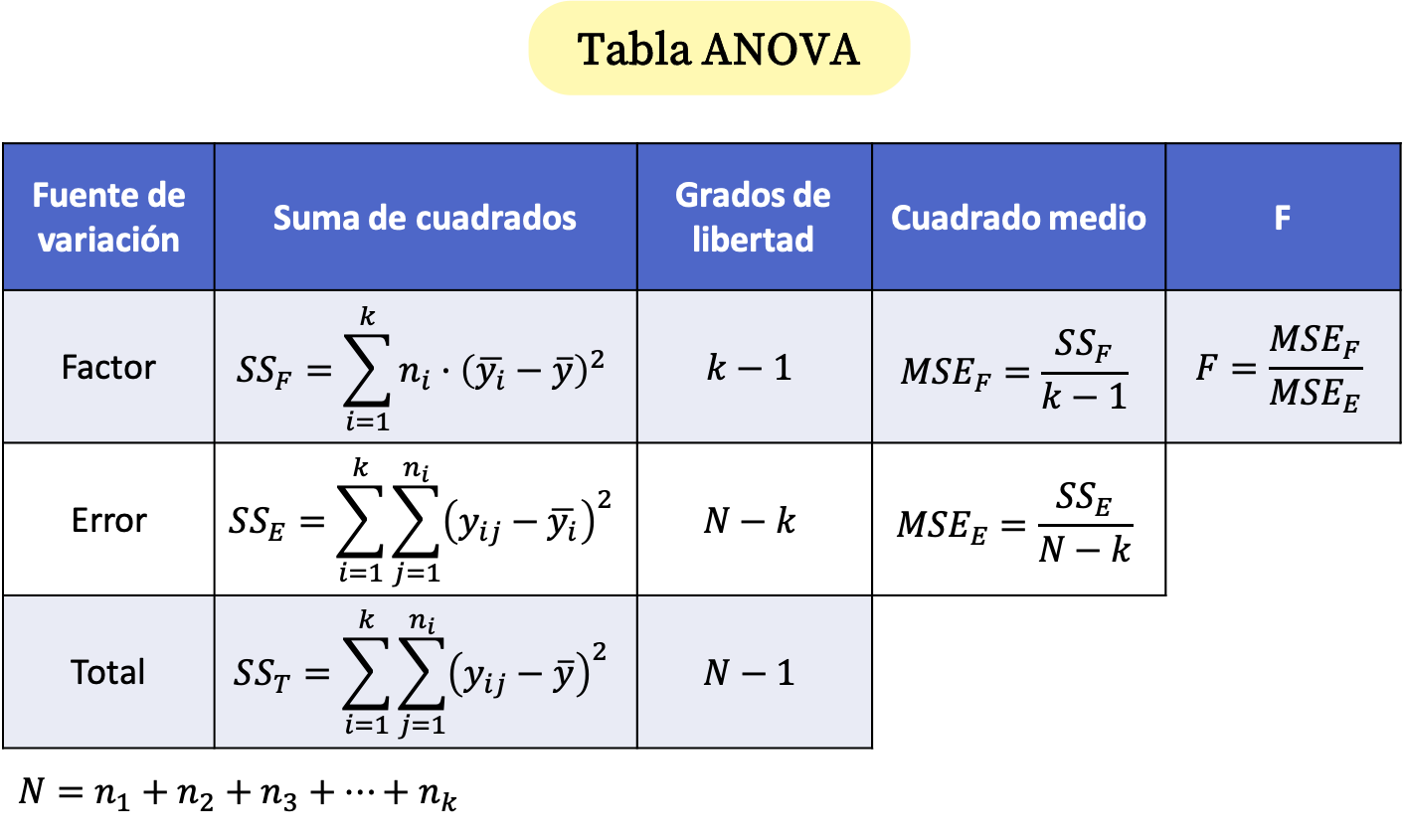
Złoto:
-

to wielkość próbki, tj.
-

to całkowita liczba obserwacji.
-

jest liczbą różnych grup w analizie wariancji.
-

jest wartością j grupy i.
-

jest średnią grupy i.
-

Jest to średnia wszystkich analizowanych danych.
Przykład tabeli ANOVA
Aby dobrze zrozumieć tę koncepcję, zobaczmy, jak utworzyć tabelę ANOVA, rozwiązując przykład krok po kroku.
- Przeprowadza się badanie statystyczne w celu porównania wyników uzyskanych przez czterech uczniów z trzech różnych przedmiotów (A, B i C). Poniższa tabela szczegółowo opisuje wyniki uzyskane przez każdego ucznia w teście, którego maksymalny wynik wynosi 20. Skonstruuj tabelę ANOVA, aby porównać wyniki uzyskane przez każdego ucznia z każdego przedmiotu.
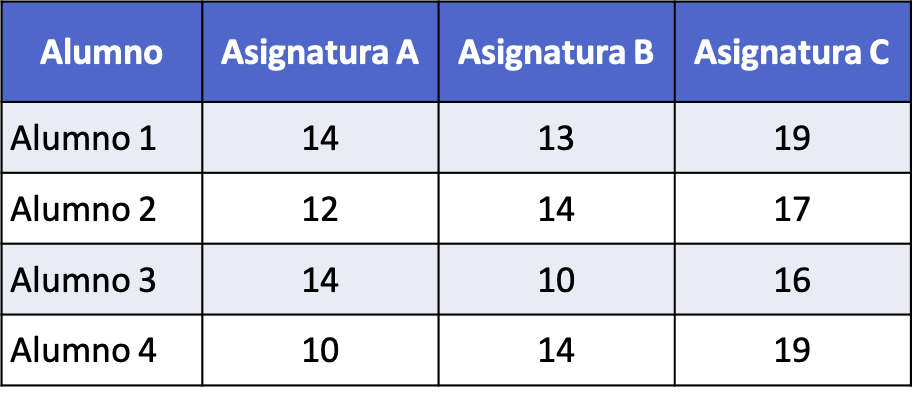
Pierwszą rzeczą, którą musimy zrobić, to obliczyć średnią dla każdego przedmiotu i całkowitą średnią danych:




Gdy znamy wartość średnich, obliczamy sumy kwadratów, korzystając ze wzorów z tabeli ANOVA (patrz wyżej):
![\begin{aligned}\displaystyle SS_F&=\sum_{i=1}^k n_i(\overline{y}_i-\overline{y})^2\\[2ex] SS_F&= 4\cdot (12,5-14,33)^2+4\cdot (12,75-14,33)^2+4\cdot (17,75-14,33)^2\\[2ex] SS_F&=70,17\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-77b3fecdc3b577841da684cd80297288_l3.png "Rendered by QuickLaTeX.com")
![\begin{aligned}\displaystyle SS_E=&\sum_{i=1}^k\sum_{j=1}^{n_i} (y_{ij}-\overline{y}_i)^2\\[2ex] \displaystyle SS_E=\ &(14-12,5)^2+(12-12,5)^2+(14-12,5)^2+(10-12,5)^2+\\&+(13-12,75)^2+(14-12,75)^2+(10-12,75)^2+(14-12,75)^2+\\&+(19-17,75)^2+(17-17,75)^2+(16-17,75)^2+(19-17,75)^2\\[2ex] SS_E=\ &28,50\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-aa02f1b826df45c26ead3537ecc4c7e5_l3.png "Rendered by QuickLaTeX.com")
![\begin{aligned}\displaystyle SS_T=&\sum_{i=1}^k\sum_{j=1}^{n_i} (y_{ij}-\overline{y})^2\\[2ex] \displaystyle SS_T= \ &(14-14,33)^2+(12-14,33)^2+(14-14,33)^2+(10-14,33)^2+\\&+(13-14,33)^2+(14-14,33)^2+(10-14,33)^2+(14-14,33)^2+\\&+(19-14,33)^2+(17-14,33)^2+(16-14,33)^2+(19-14,33)^2\\[2ex] SS_T= \ &98,67\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-2eb66d1d37653749f38916c905108a3b_l3.png "Rendered by QuickLaTeX.com")
Następnie wyznaczamy stopnie swobody czynnika, błąd i sumę:



Teraz obliczamy błędy średniokwadratowe, dzieląc sumy kwadratów współczynnika i błędu przez ich odpowiednie stopnie swobody:


Na koniec obliczamy wartość statystyki F, dzieląc dwa błędy obliczone w poprzednim kroku:

W skrócie, tabela ANOVA dla przykładowych danych wyglądałaby następująco:

Po obliczeniu wszystkich wartości w tabeli ANOVA pozostaje tylko je zinterpretować. Aby to zrobić, musimy porównać prawdopodobieństwo odpowiadające wartości statystyki F, zwanej wartością p. Możesz zobaczyć, jak to się robi, klikając poniższy link:
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej