Jak obliczyć studentyzowane reszty w pythonie
Reszta studenta to po prostu reszta podzielona przez oszacowane odchylenie standardowe.
W praktyce ogólnie mówimy, że każda obserwacja w zbiorze danych, której reszta Studenta jest większa niż wartość bezwzględna 3, jest wartością odstającą.
Możemy szybko uzyskać studentyzowane reszty modelu regresji w Pythonie, używając funkcji OLSResults.outlier_test() statsmodels, która wykorzystuje następującą składnię:
OLSResults.outlier_test()
gdzie OLSResults to nazwa dopasowania modelu liniowego przy użyciu funkcji statsmodels ols() .
Przykład: obliczenie studentyzowanych reszt w Pythonie
Załóżmy, że budujemy następujący prosty model regresji liniowej w Pythonie:
#import necessary packages and functions import numpy as np import pandas as pd import statsmodels. api as sm from statsmodels. formula . api import ols #create dataset df = pd. DataFrame ({'rating': [90, 85, 82, 88, 94, 90, 76, 75, 87, 86], 'points': [25, 20, 14, 16, 27, 20, 12, 15, 14, 19]}) #fit simple linear regression model model = ols('rating ~ points', data=df). fit ()
Możemy użyć funkcji outlier_test() do utworzenia ramki danych zawierającej studentyzowane reszty dla każdej obserwacji w zbiorze danych:
#calculate studentized residuals stud_res = model. outlier_test () #display studentized residuals print(stud_res) student_resid unadj_p bonf(p) 0 -0.486471 0.641494 1.000000 1 -0.491937 0.637814 1.000000 2 0.172006 0.868300 1.000000 3 1.287711 0.238781 1.000000 4 0.106923 0.917850 1.000000 5 0.748842 0.478355 1.000000 6 -0.968124 0.365234 1.000000 7 -2.409911 0.046780 0.467801 8 1.688046 0.135258 1.000000 9 -0.014163 0.989095 1.000000
Ta ramka danych wyświetla następujące wartości dla każdej obserwacji w zbiorze danych:
- Studencka pozostałość
- Nieskorygowana wartość p studentyzowanej reszty
- Skorygowana przez Bonferroniego wartość p reszty studenta
Widzimy, że studencka reszta dla pierwszej obserwacji w zbiorze danych wynosi -0,486471 , studencka reszta dla drugiej obserwacji wynosi -0,491937 i tak dalej.
Możemy również stworzyć szybki wykres wartości zmiennych predykcyjnych względem odpowiednich studentyzowanych reszt:
import matplotlib. pyplot as plt #define predictor variable values and studentized residuals x = df[' points '] y = stud_res[' student_resid '] #create scatterplot of predictor variable vs. studentized residuals plt. scatter (x,y) plt. axhline (y=0, color=' black ', linestyle=' -- ') plt. xlabel (' Points ') plt. ylabel (' Studentized Residuals ')
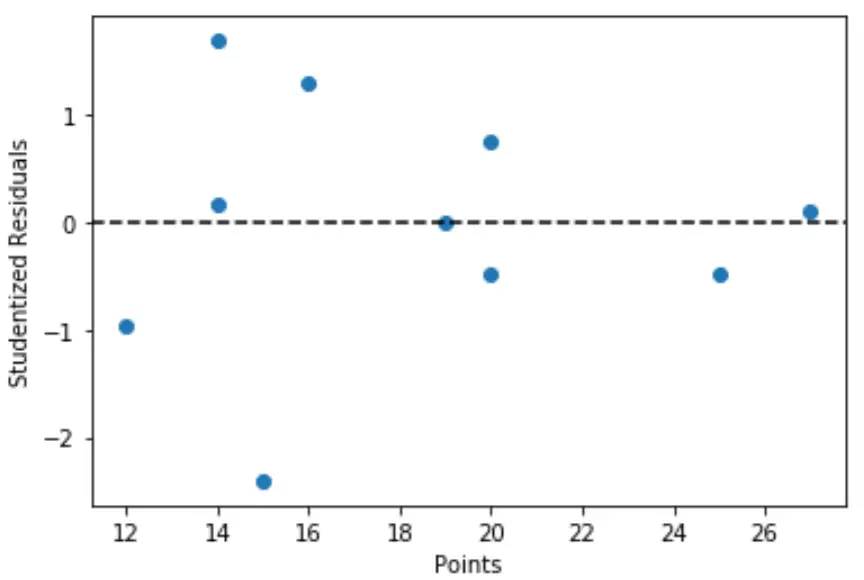
Z wykresu widać, że żadna z obserwacji nie ma reszty Studenta o wartości bezwzględnej większej niż 3, zatem w zbiorze danych nie ma wyraźnych wartości odstających.
Dodatkowe zasoby
Jak wykonać prostą regresję liniową w Pythonie
Jak wykonać wielokrotną regresję liniową w Pythonie
Jak utworzyć wykres resztkowy w Pythonie
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej