Co uważa się za surowe dane? (definicja i przykłady)
W statystyce dane surowe oznaczają dane, które zostały zebrane bezpośrednio ze źródła pierwotnego i nie zostały w żaden sposób przetworzone.
W każdym projekcie analizy danych pierwszym krokiem jest zebranie surowych danych. Po zebraniu tych danych można je następnie oczyścić, przekształcić, podsumować i zwizualizować.
Zaletą gromadzenia surowych danych jest to, że docelowo można je wykorzystać do lepszego zrozumienia pewnych zjawisk lub wykorzystać je do zbudowania pewnego rodzaju modelu predykcyjnego.
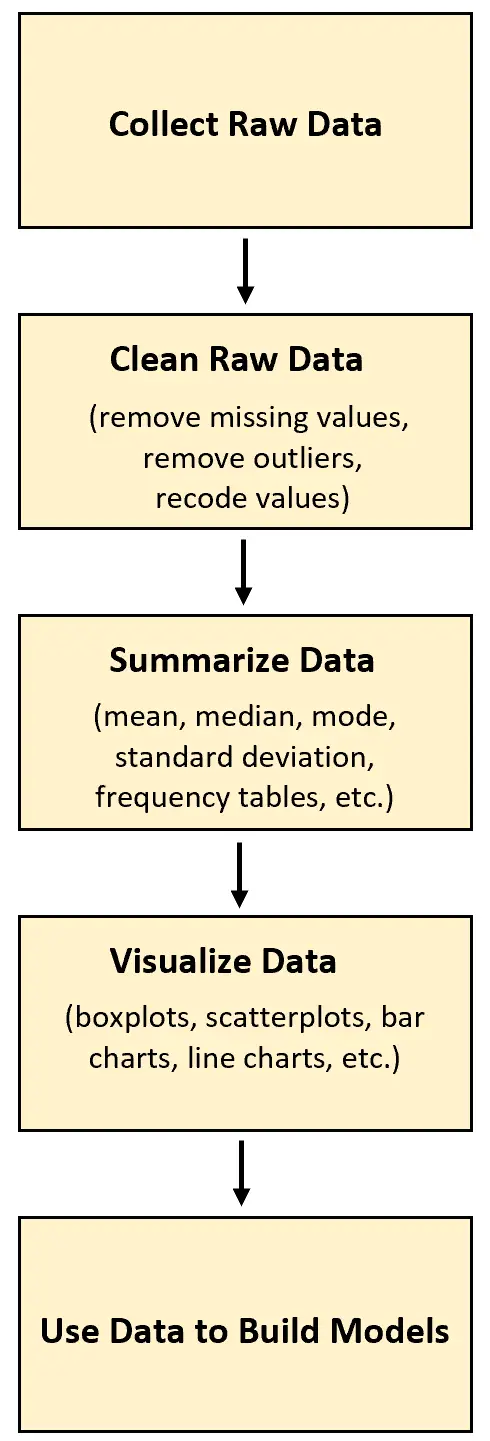
Poniższy przykład ilustruje, w jaki sposób można gromadzić surowe dane i wykorzystywać je w prawdziwym życiu.
Przykład: gromadzenie i wykorzystywanie surowych danych
Sport to obszar, w którym często gromadzone są surowe dane. Na przykład surowe dane można gromadzić na potrzeby różnych statystyk dotyczących zawodowych koszykarzy.
Krok 1: Zbierz surowe dane
Wyobraź sobie, że skaut koszykówki zbiera następujące surowe dane dotyczące 10 zawodników profesjonalnej drużyny koszykówki: 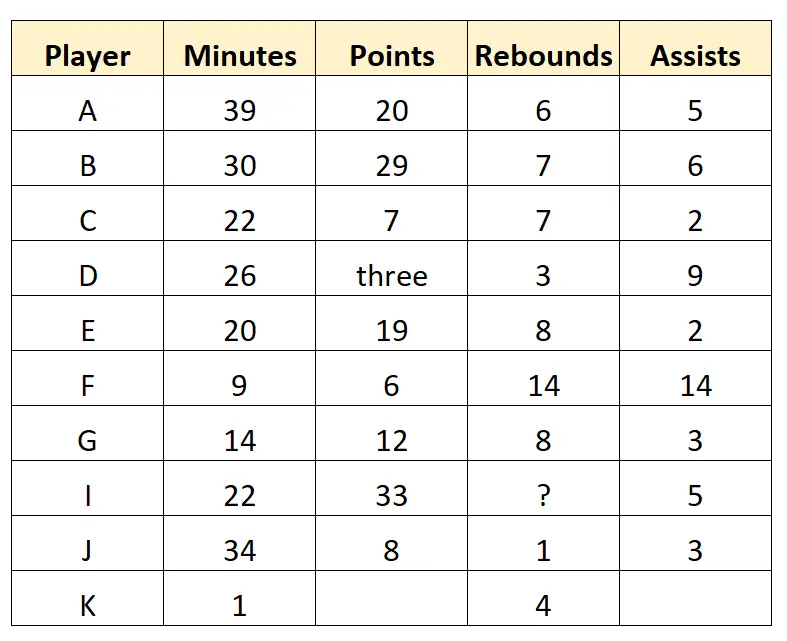
Ten zbiór danych reprezentuje surowe dane , ponieważ zostały zebrane bezpośrednio przez scouta i nie zostały oczyszczone ani przetworzone w żaden sposób.
Krok 2: Wyczyść surowe dane
Przed użyciem tych danych do utworzenia tabel podsumowujących, wykresów lub czegokolwiek innego, scout musi najpierw usunąć wszelkie brakujące wartości i oczyścić wszelkie „brudne” wartości danych.
Na przykład możemy zauważyć w zbiorze danych kilka wartości, które wymagają przekształcenia lub usunięcia:
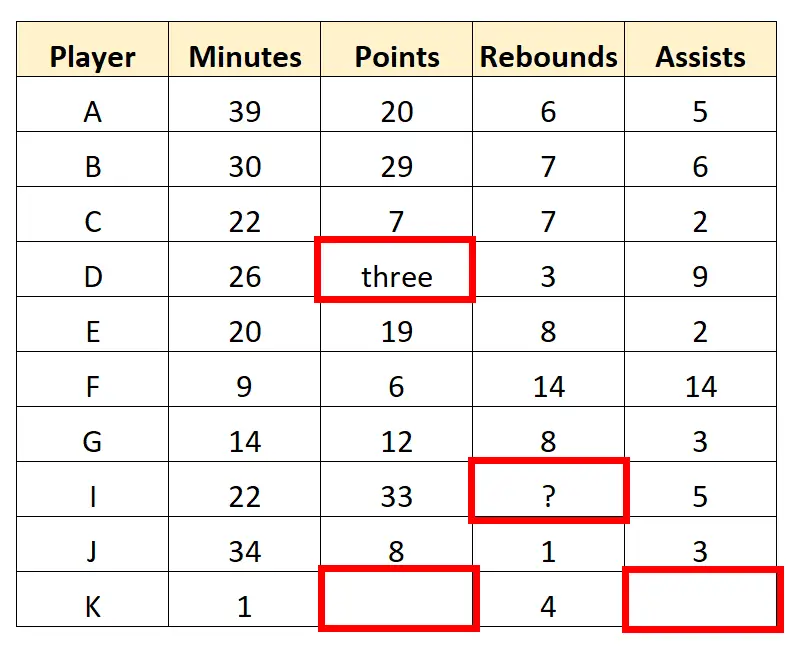
Zwiadowca może podjąć decyzję o całkowitym usunięciu ostatniego wiersza, ponieważ zawiera on kilka brakujących wartości. Może następnie wyczyścić wartości znaków w zbiorze danych, aby uzyskać następujące „czyste” dane:
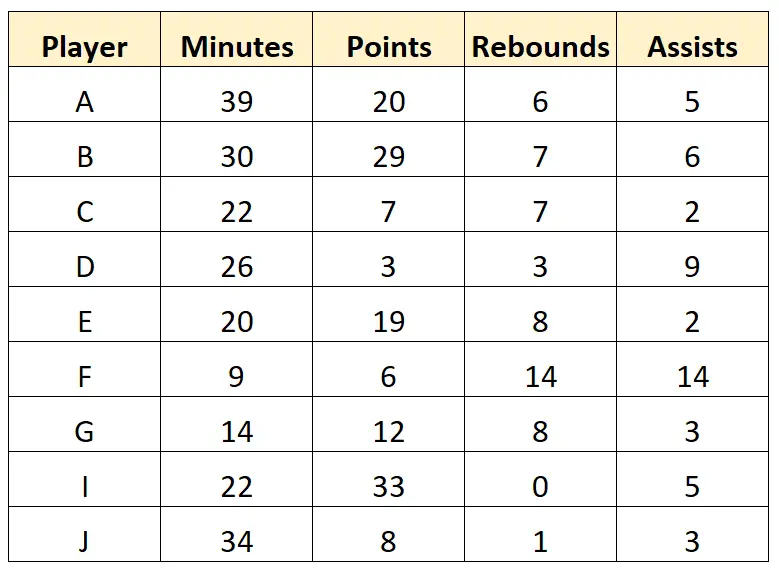
Krok 3: Podsumuj dane
Po oczyszczeniu danych badacz może podsumować każdą zmienną w zbiorze danych. Na przykład może obliczyć następujące statystyki podsumowujące dla zmiennej „Minuty”:
- Średnia : 24 minuty
- Mediana : 22 minuty
- Odchylenie standardowe : 9,45 minuty
Krok 4: Wizualizuj dane
Osoba badająca może następnie wizualizować zmienne w zbiorze danych, aby lepiej zrozumieć wartości danych.
Na przykład może utworzyć następujący wykres słupkowy, aby zwizualizować całkowitą liczbę minut rozegranych przez każdego gracza:
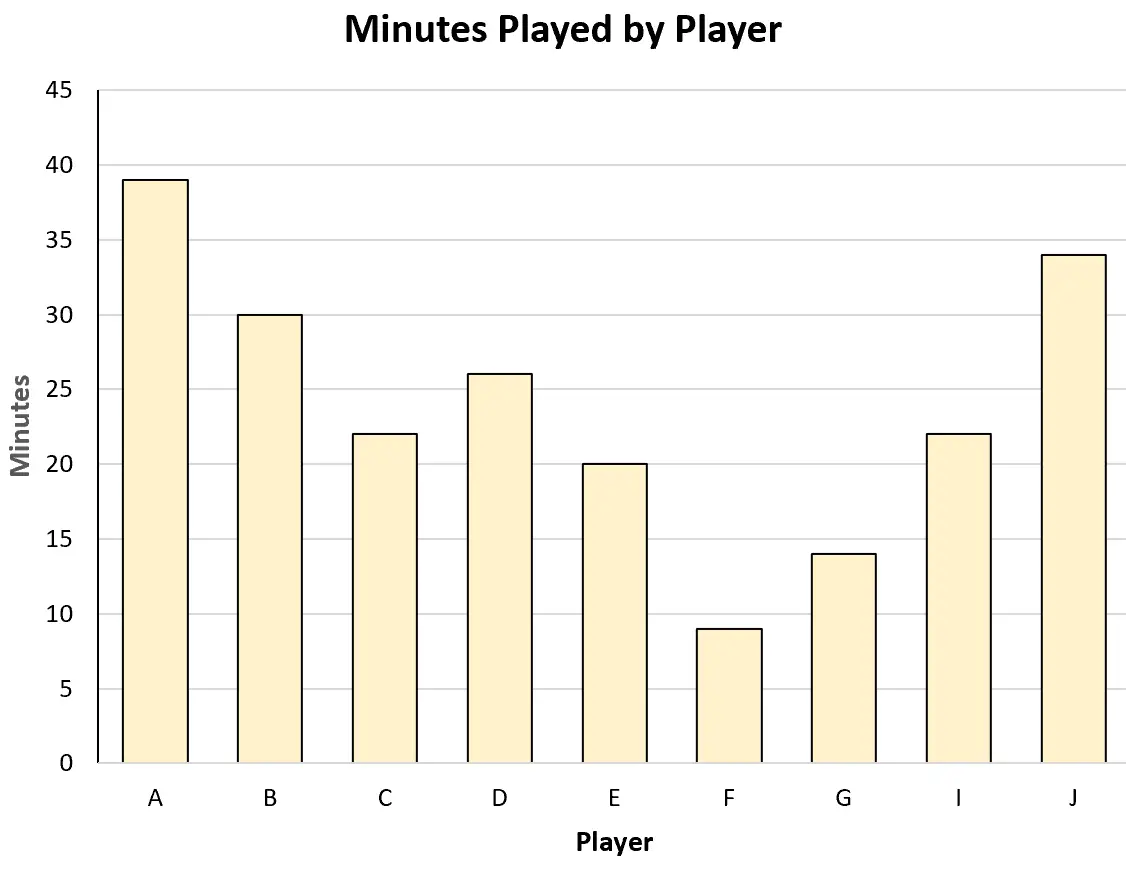
Można też utworzyć następujący wykres rozrzutu, aby zwizualizować związek pomiędzy rozegranymi minutami a zdobytymi punktami:
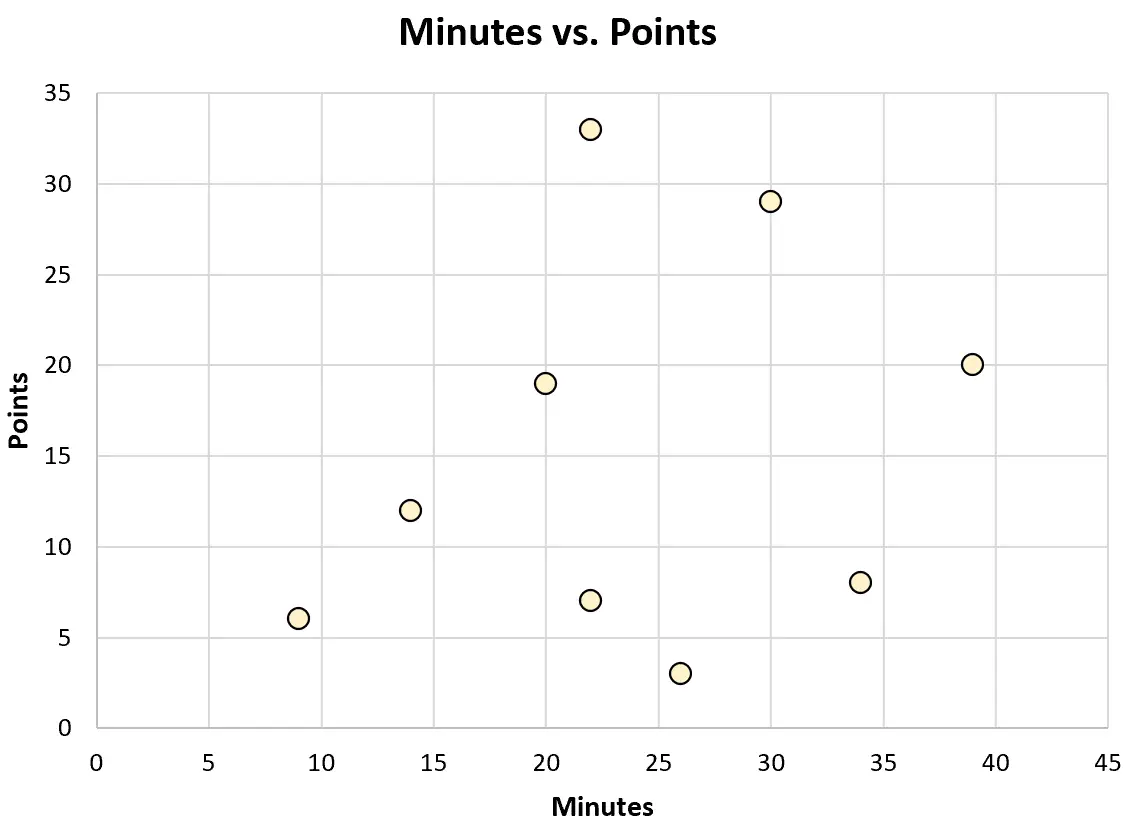
Każdy z tych typów wykresów może pomóc mu lepiej zrozumieć dane.
Krok 5: Wykorzystaj dane do zbudowania modelu
Wreszcie, po oczyszczeniu danych, badacz może podjąć decyzję o dostosowaniu pewnego rodzaju modelu predykcyjnego.
Można na przykład dopasować prosty model regresji liniowej i wykorzystać minuty rozegrane do przewidzenia łącznej liczby punktów zdobytych przez każdego gracza.
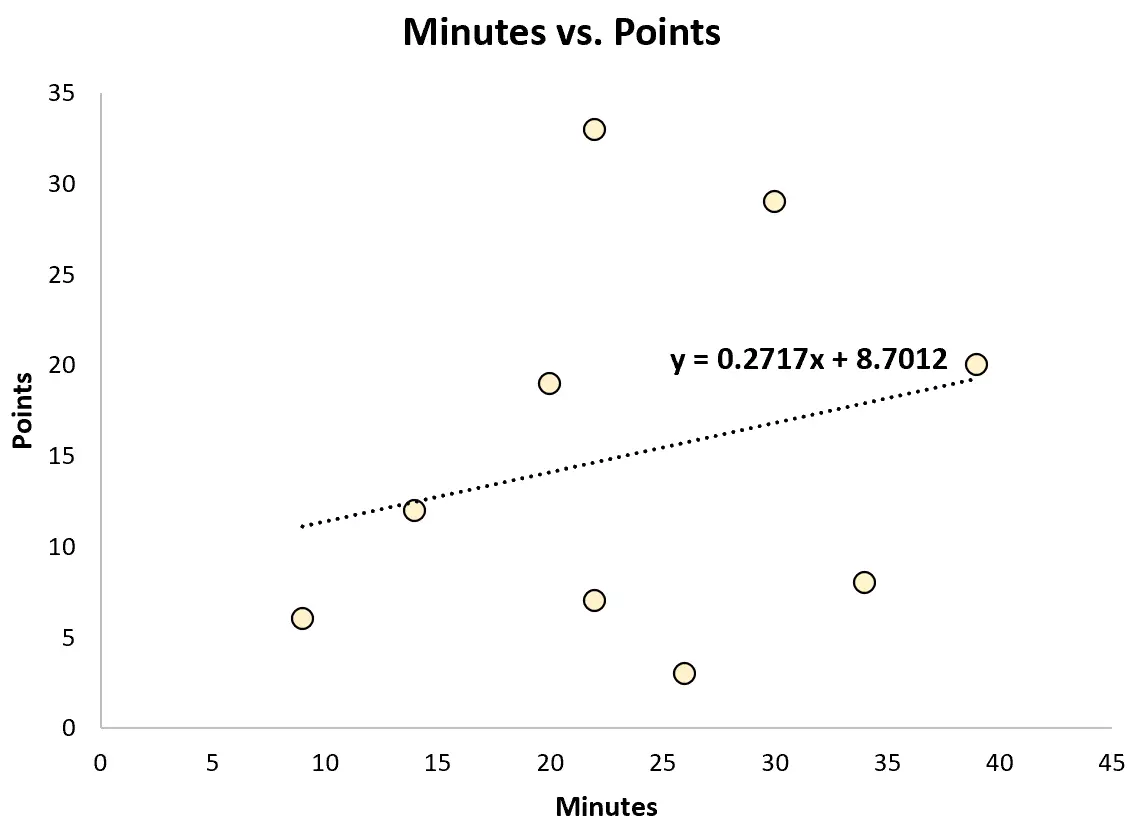
Dopasowane równanie regresji to:
Punkty = 8,7012 + 0,2717*(minuty)
Skaut może następnie użyć tego równania, aby przewidzieć liczbę punktów, które gracz zdobędzie na podstawie liczby rozegranych minut. Na przykład zawodnik grający 30 minut powinien uzyskać 16,85 punktu:
Punkty = 8,7012 + 0,2717*(30) = 16,85
Dodatkowe zasoby
Dlaczego statystyki są ważne?
Dlaczego wielkość próby jest ważna w statystyce?
Co to jest obserwacja w statystyce?
Czym są dane tabelaryczne w statystyce?
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej