Jak wykonać test shapiro-wilka w r (z przykładami)
Test Shapiro-Wilka jest testem normalności. Służy do określenia, czy próbka pochodzi z rozkładu normalnego .
Ten typ testu jest przydatny do ustalenia, czy dany zbiór danych pochodzi z rozkładu normalnego, co jest powszechnie stosowanym założeniem w wielu testach statystycznych, w tym w regresji , ANOVA , testach t i wielu innych. 'inni.
Możemy łatwo wykonać test Shapiro-Wilka na danym zbiorze danych, korzystając z następującej funkcji wbudowanej w R:
shapiro.test(x)
Złoto:
- x: wektor numeryczny wartości danych.
Ta funkcja generuje statystykę testową W wraz z odpowiednią wartością p. Jeśli wartość p jest mniejsza niż α = 0,05, istnieją wystarczające dowody, aby stwierdzić, że próbka nie pochodzi z populacji o rozkładzie normalnym.
Uwaga: aby można było skorzystać z funkcji shapiro.test(), wielkość próbki musi mieścić się w przedziale od 3 do 5000.
W tym samouczku przedstawiono kilka przykładów praktycznego wykorzystania tej funkcji.
Przykład 1: Test Shapiro-Wilka na normalnych danych
Poniższy kod pokazuje, jak przeprowadzić test Shapiro-Wilka na zbiorze danych o wielkości próby n=100:
#make this example reproducible set.seed(0) #create dataset of 100 random values generated from a normal distribution data <- rnorm(100) #perform Shapiro-Wilk test for normality shapiro.test(data) Shapiro-Wilk normality test data:data W = 0.98957, p-value = 0.6303
Wartość p testu wynosi 0,6303 . Ponieważ wartość ta jest nie mniejsza niż 0,05, możemy założyć, że przykładowe dane pochodzą z populacji o rozkładzie normalnym.
Wynik ten nie powinien dziwić, gdyż przykładowe dane wygenerowaliśmy za pomocą funkcji rnorm(), która generuje wartości losowe z rozkładu normalnego o średniej = 0 i odchyleniu standardowym = 1.
Powiązane: Przewodnik po dnorm, pnorm, qnorm i rnorm w R
Możemy również utworzyć histogram, aby wizualnie sprawdzić, czy przykładowe dane mają rozkład normalny:
hist(data, col=' steelblue ')
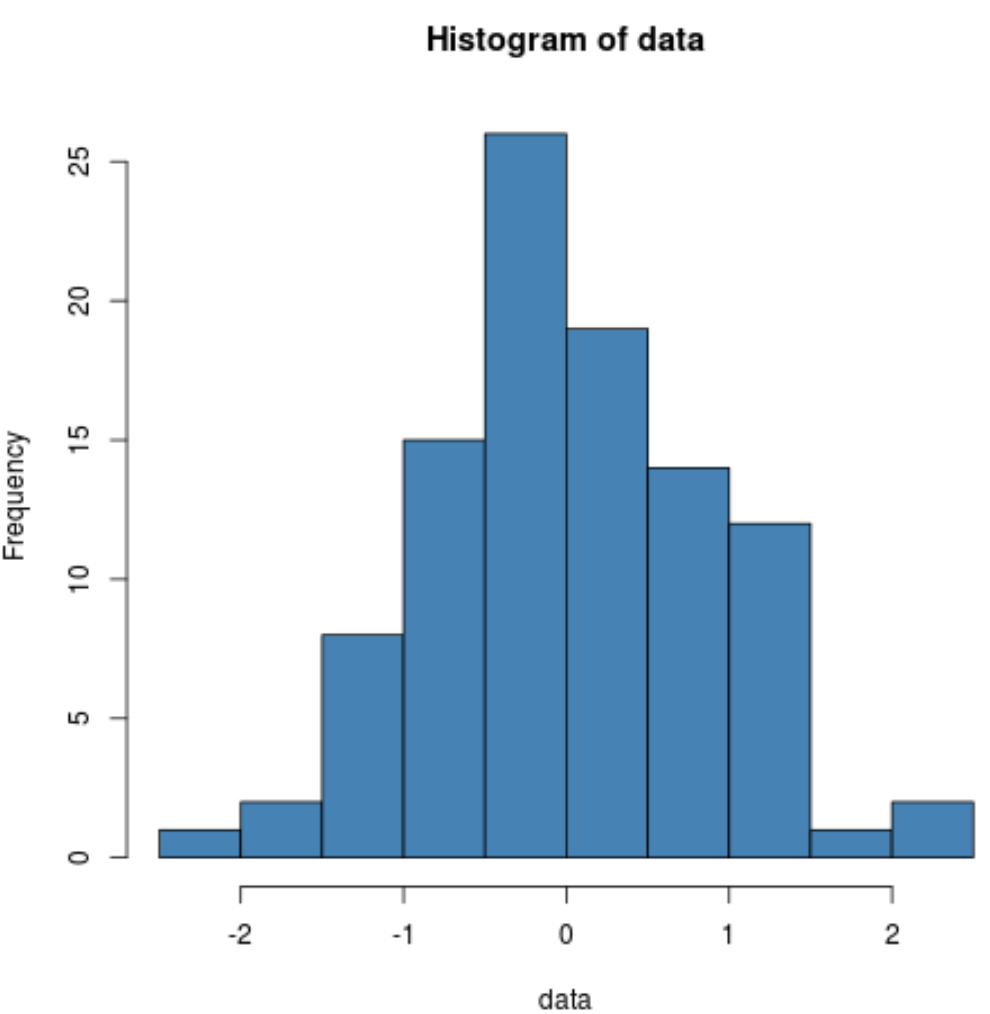
Widzimy, że rozkład ma kształt dzwonu z pikiem w środku rozkładu, co jest typowe dla danych o rozkładzie normalnym.
Przykład 2: Test Shapiro-Wilka na danych nietypowych
Poniższy kod pokazuje jak wykonać test Shapiro-Wilka na zbiorze danych o wielkości próby n=100, w którym wartości są generowane losowo z rozkładu Poissona :
#make this example reproducible set.seed(0) #create dataset of 100 random values generated from a Poisson distribution data <- rpois(n=100, lambda=3) #perform Shapiro-Wilk test for normality shapiro.test(data) Shapiro-Wilk normality test data:data W = 0.94397, p-value = 0.0003393
Wartość p testu wynosi 0,0003393 . Ponieważ wartość ta jest mniejsza niż 0,05, mamy wystarczające dowody, aby stwierdzić, że dane próbki nie pochodzą z populacji o rozkładzie normalnym.
Wynik ten nie powinien dziwić, gdyż przykładowe dane wygenerowaliśmy za pomocą funkcji rpois(), która generuje wartości losowe z rozkładu Poissona.
Powiązane: Przewodnik po dpois, ppois, qpois i rpois w R
Możemy również utworzyć histogram, aby wizualnie zobaczyć, że przykładowe dane nie mają rozkładu normalnego:
hist(data, col=' coral2 ')
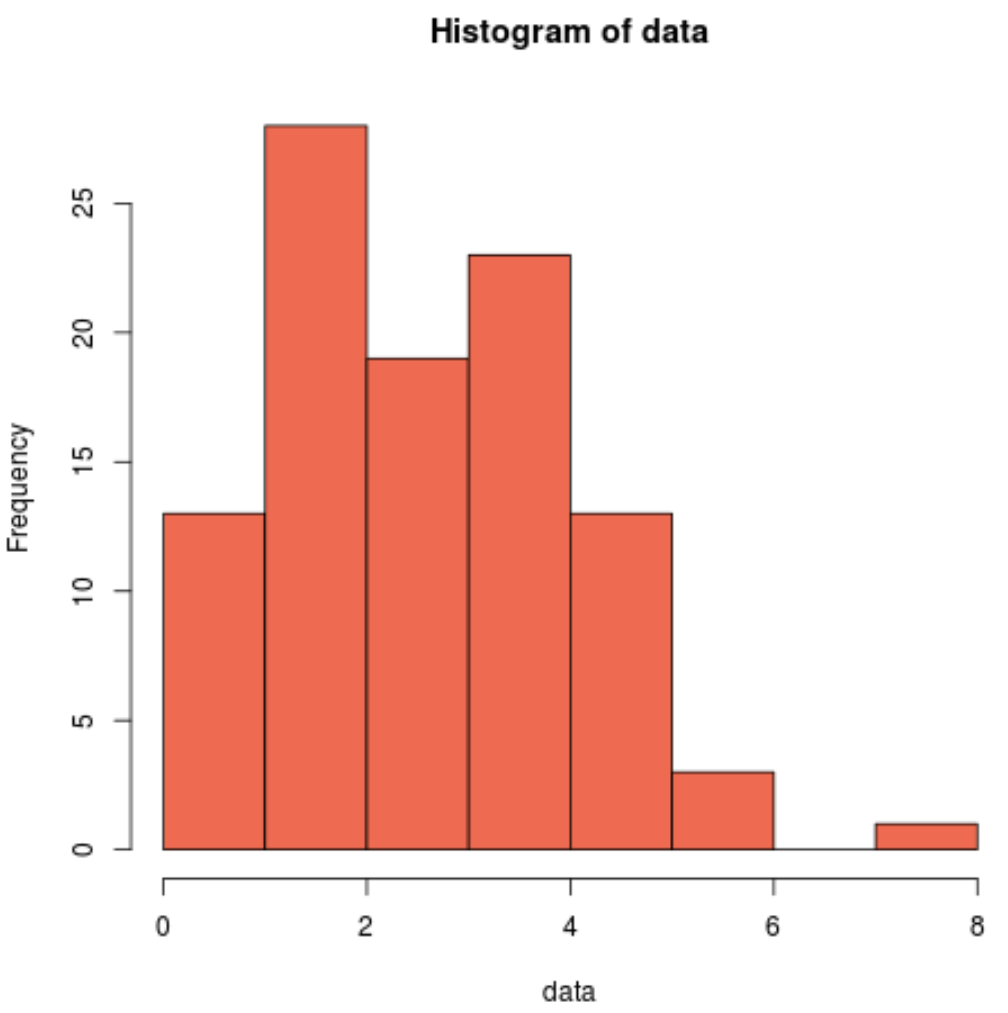
Widzimy, że rozkład jest prawoskośny i nie ma typowego „kształtu dzwonu” kojarzonego z rozkładem normalnym. Zatem nasz histogram pasuje do wyników testu Shapiro-Wilka i potwierdza, że nasze przykładowe dane nie pochodzą z rozkładu normalnego.
Co zrobić z nietypowymi danymi
Jeśli dany zbiór danych nie ma rozkładu normalnego, często możemy wykonać jedną z następujących transformacji, aby uczynić go bardziej normalnym:
1. Transformacja logu: przekształć zmienną odpowiedzi z y na log(y) .
2. Transformacja pierwiastka kwadratowego: Przekształć zmienną odpowiedzi z y na √y .
3. Transformacja pierwiastka sześciennego: przekształć zmienną odpowiedzi z y na y 1/3 .
Wykonując te przekształcenia, zmienna odpowiedzi ogólnie zbliża się do rozkładu normalnego.
Sprawdź ten samouczek , aby zobaczyć, jak wykonać te transformacje w praktyce.
Dodatkowe zasoby
Jak wykonać test Andersona-Darlinga w R
Jak wykonać test Kołmogorowa-Smirnowa w R
Jak wykonać test Shapiro-Wilka w Pythonie
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej