Jak wykonać test shapiro-wilka w sas-ie
Test Shapiro-Wilka służy do określenia, czy zbiór danych ma rozkład normalny .
Poniższy przykład pokazuje krok po kroku, jak wykonać test Shapiro-Wilka dla zbioru danych w SAS-ie.
Krok 1: Utwórz dane
Najpierw utworzymy zbiór danych zawierający 15 obserwacji:
/*create dataset*/ data my_data; input x; datalines ; 3 3 4 6 7 8 8 9 12 14 15 15 17 20 21 ; run ; /*view dataset*/ proc print data =my_data;
Krok 2: Wykonaj test Shapiro-Wilka
Następnie użyjemy proc univariate z poleceniem normal , aby wykonać test normalności Shapiro-Wilka:
/*perform Shapiro-Wilk test*/ proc univariate data =my_data normal ; run ;
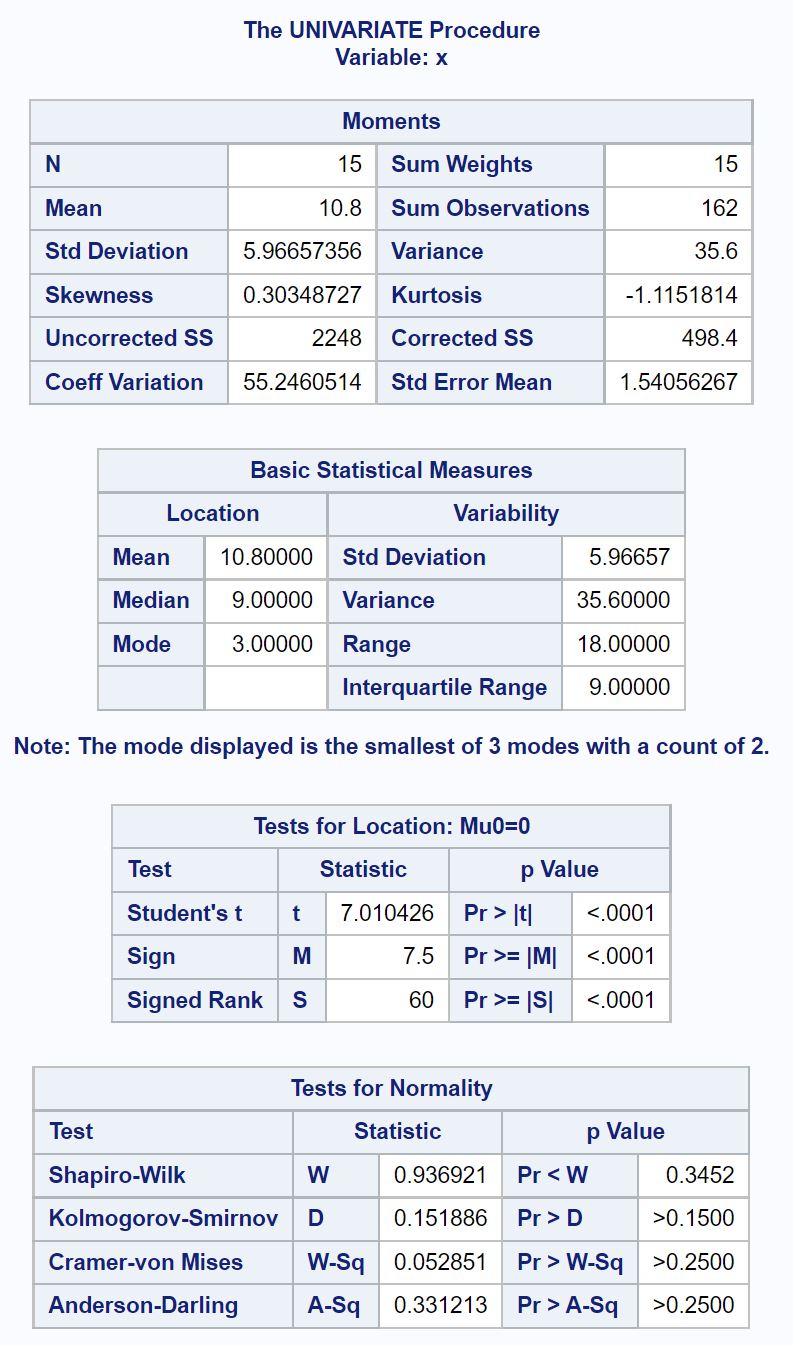
Wynik dostarcza nam mnóstwo informacji, ale jedyną tabelą, której musimy się przyjrzeć, jest ta o nazwie Testy normalności .
Ta tabela zawiera statystyki testów i wartości p dla kilku testów normalności, w tym:
- Test Shapiro-Wilka
- Test Kołmogorowa-Smirnowa
- Test Cramera-von Misesa
- Test Andersona-Darlinga
Z tej tabeli widzimy, że wartość p dla testu Shapiro-Wilka wynosi 0,3452 .
Przypomnijmy, że test Shapiro-Wilka wykorzystuje następujące hipotezy zerowe i alternatywne:
- H 0 : Dane mają rozkład normalny.
- H A : Dane nie mają rozkładu normalnego.
Ponieważ wartość p ( 0,3452 ) jest nie mniejsza niż 0,05, nie możemy odrzucić hipotezy zerowej.
Oznacza to, że nie mamy wystarczających dowodów, aby stwierdzić, że zbiór danych nie ma rozkładu normalnego.
Innymi słowy, można założyć, że zbiór danych ma rozkład normalny.
Dodatkowe zasoby
Poniższe samouczki wyjaśniają, jak wykonywać inne popularne testy statystyczne w SAS-ie:
Jak wykonać test Kołmogorowa-Smirnowa w SAS
Jak wykonać test dobroci dopasowania chi-kwadrat w SAS
Jak wykonać dokładny test Fishera w SAS
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej