Krótkie wprowadzenie do uczenia się pod nadzorem i bez nadzoru
Dziedzina uczenia maszynowego zawiera ogromny zestaw algorytmów, które można wykorzystać do zrozumienia danych. Algorytmy te można podzielić na jedną z dwóch kategorii:
1. Algorytmy uczenia się nadzorowanego: obejmują budowanie modelu w celu oszacowania lub przewidzenia wyniku na podstawie jednego lub większej liczby danych wejściowych.
2. Algorytmy uczenia się bez nadzoru: obejmują znajdowanie struktury i zależności na podstawie danych wejściowych. Nie ma wyjścia „nadzorczego”.
W tym samouczku wyjaśniono różnicę między tymi dwoma typami algorytmów wraz z kilkoma przykładami każdego z nich.
Algorytmy uczenia się nadzorowanego
Algorytmu nadzorowanego uczenia się można użyć , gdy mamy jedną lub więcej zmiennych objaśniających ( X1, zmienna odpowiedzi:
Y = fa (X) + ε
gdzie f reprezentuje informację systematyczną, którą X dostarcza na temat Y, a ε jest składnikiem błędu losowego niezależnym od X ze średnią wynoszącą zero.
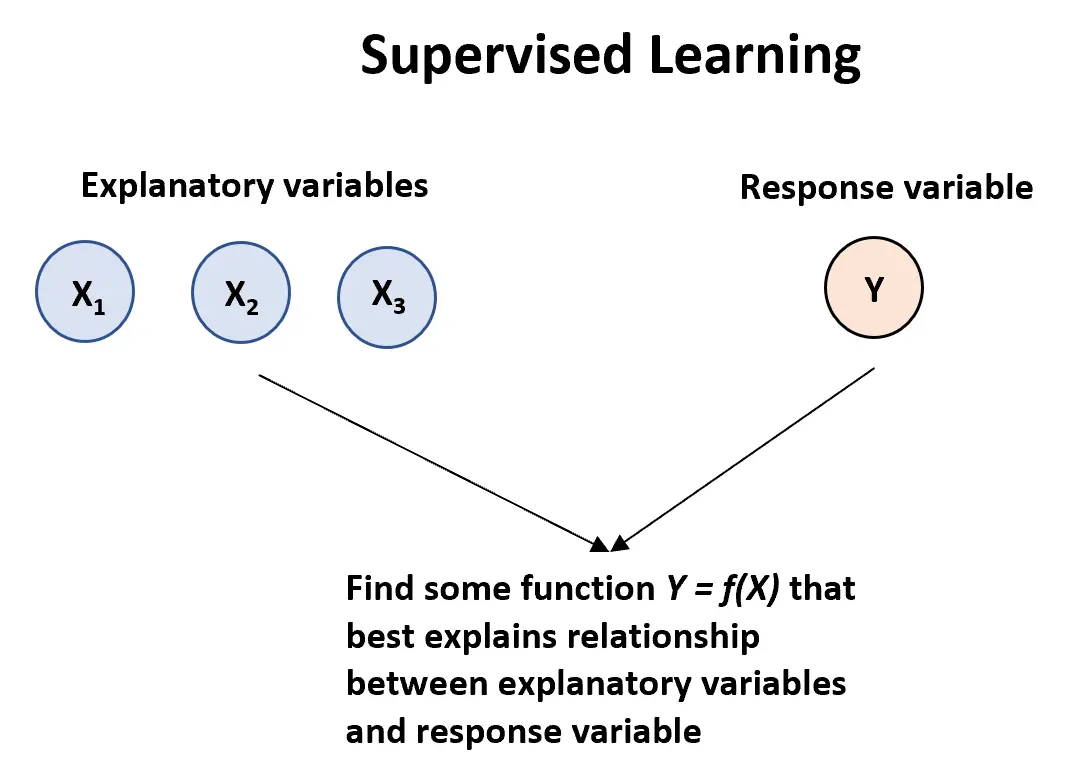
Istnieją dwa główne typy algorytmów uczenia się nadzorowanego:
1. Regresja: zmienna wyjściowa ma charakter ciągły (np. waga, wzrost, czas itp.)
2. Klasyfikacja: Zmienna wyjściowa jest kategoryczna (np. mężczyzna lub kobieta, sukces lub porażka, nowotwór łagodny lub złośliwy itp.).
Istnieją dwa główne powody, dla których używamy algorytmów uczenia się nadzorowanego:
1. Prognoza: Często używamy zestawu zmiennych objaśniających, aby przewidzieć wartość zmiennej odpowiedzi (na przykład wykorzystując powierzchnię i liczbę sypialni do przewidzenia ceny domu ).
2. Wniosek: Możemy być zainteresowani zrozumieniem, jak na zmienną odpowiedzi wpływa zmiana wartości zmiennych objaśniających (np. o ile średnio wzrasta cena nieruchomości, gdy liczba pokoi wzrasta o jeden?)
W zależności od tego, czy naszym celem jest wnioskowanie, czy przewidywanie (lub połączenie obu), możemy zastosować różne metody estymacji funkcji f . Na przykład modele liniowe oferują łatwiejszą interpretację, ale trudne w interpretacji modele nieliniowe mogą zapewniać dokładniejsze przewidywania.
Oto lista najczęściej używanych algorytmów uczenia się nadzorowanego:
- Regresja liniowa
- Regresja logistyczna
- Liniowa analiza dyskryminacyjna
- Kwadratowa analiza dyskryminacyjna
- Drzewa decyzyjne
- Naiwny Bayes
- Obsługa maszyn wektorowych
- Sieci neuronowe
Algorytmy uczenia się bez nadzoru
Algorytm uczenia się bez nadzoru można zastosować, gdy mamy listę zmiennych ( X 1 , data.
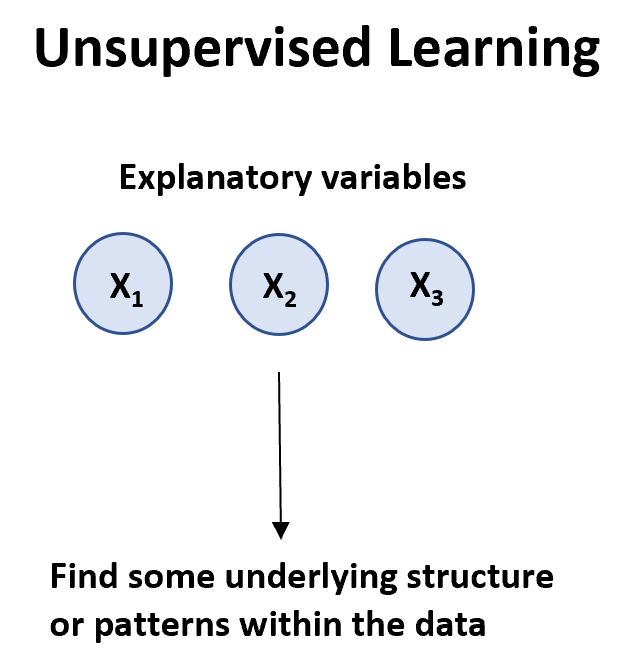
Istnieją dwa główne typy algorytmów uczenia się bez nadzoru:
1. Grupowanie: Używając tego typu algorytmów, staramy się znaleźć „skupiska” obserwacji w zbiorze danych, które są do siebie podobne. Jest to często stosowane w handlu detalicznym, gdy firma chce zidentyfikować grupy klientów o podobnych nawykach zakupowych, aby móc stworzyć konkretne strategie marketingowe skierowane do określonych grup klientów.
2. Asocjacje: Używając tego typu algorytmów, staramy się znaleźć „reguły”, które można wykorzystać do ustanowienia asocjacji. Na przykład sprzedawcy detaliczni mogą opracować algorytm skojarzeń, który będzie wskazywał, że „jeśli klient kupi produkt X, z dużym prawdopodobieństwem kupi także produkt Y”.
Oto lista najczęściej używanych algorytmów uczenia się bez nadzoru:
- Analiza głównych składowych
- K-oznacza grupowanie
- Grupowanie K-medoidów
- Klasyfikacja hierarchiczna
- Algorytm aprioryczny
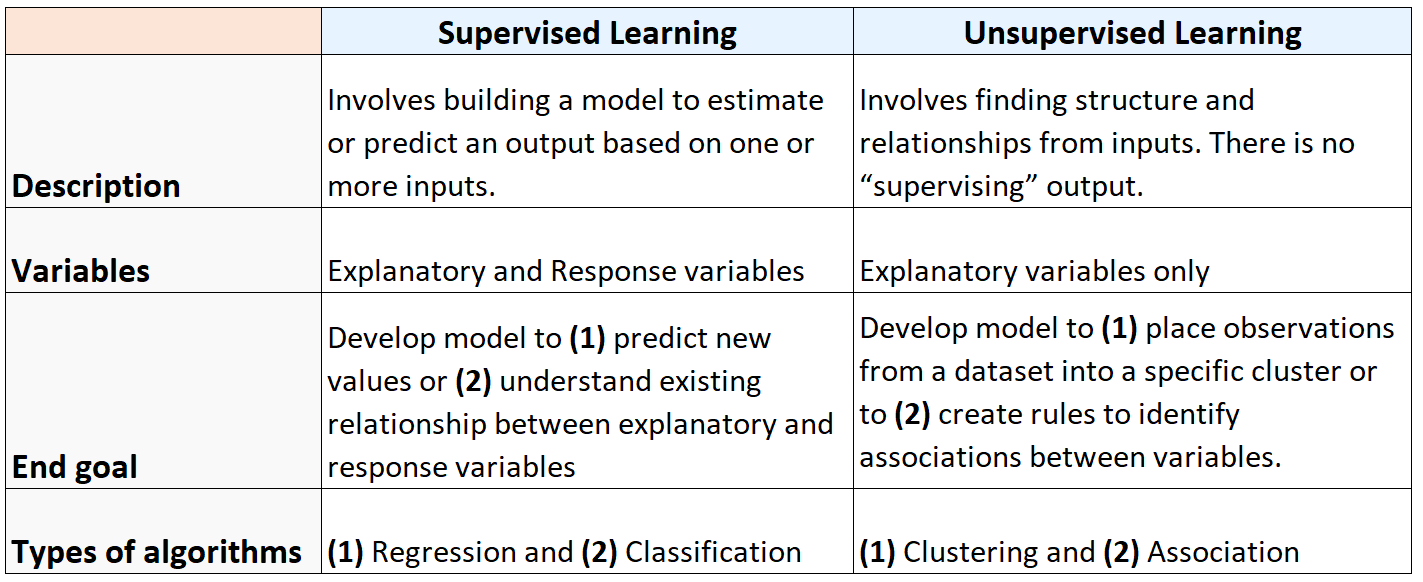
Podsumowanie: Uczenie się pod nadzorem czy bez nadzoru
Poniższa tabela podsumowuje różnice pomiędzy algorytmami uczenia się nadzorowanego i nienadzorowanego:
Poniższy diagram podsumowuje typy algorytmów uczenia maszynowego:

o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej