Jak uzyskać przewidywane wartości i reszty w stata
Regresja liniowa to metoda, której możemy użyć do zrozumienia związku między jedną lub większą liczbą zmiennych objaśniających a zmienną odpowiedzi.
Kiedy przeprowadzamy regresję liniową na zbiorze danych, otrzymujemy równanie regresji, które można wykorzystać do przewidywania wartości zmiennej odpowiedzi, biorąc pod uwagę wartości zmiennych objaśniających.
Możemy następnie zmierzyć różnicę między wartościami przewidywanymi a wartościami rzeczywistymi, aby uzyskać reszty dla każdej prognozy. Pomaga nam to zorientować się, jak dobrze nasz model regresji przewiduje wartości odpowiedzi.
W tym samouczku wyjaśniono, jak uzyskać zarówno wartości przewidywane , jak i reszty dla modelu regresji w Stata.
Przykład: Jak uzyskać przewidywane wartości i reszty
W tym przykładzie użyjemy wbudowanego zbioru danych Stata o nazwie auto . Użyjemy mpg i pojemności skokowej jako zmiennych objaśniających, a ceny jako zmiennej odpowiedzi.
Wykonaj poniższe kroki, aby przeprowadzić regresję liniową, a następnie uzyskać przewidywane wartości i reszty dla modelu regresji.
Krok 1: Załaduj i wyświetl dane.
Najpierw załadujemy dane za pomocą następującego polecenia:
automatyczne korzystanie z systemu
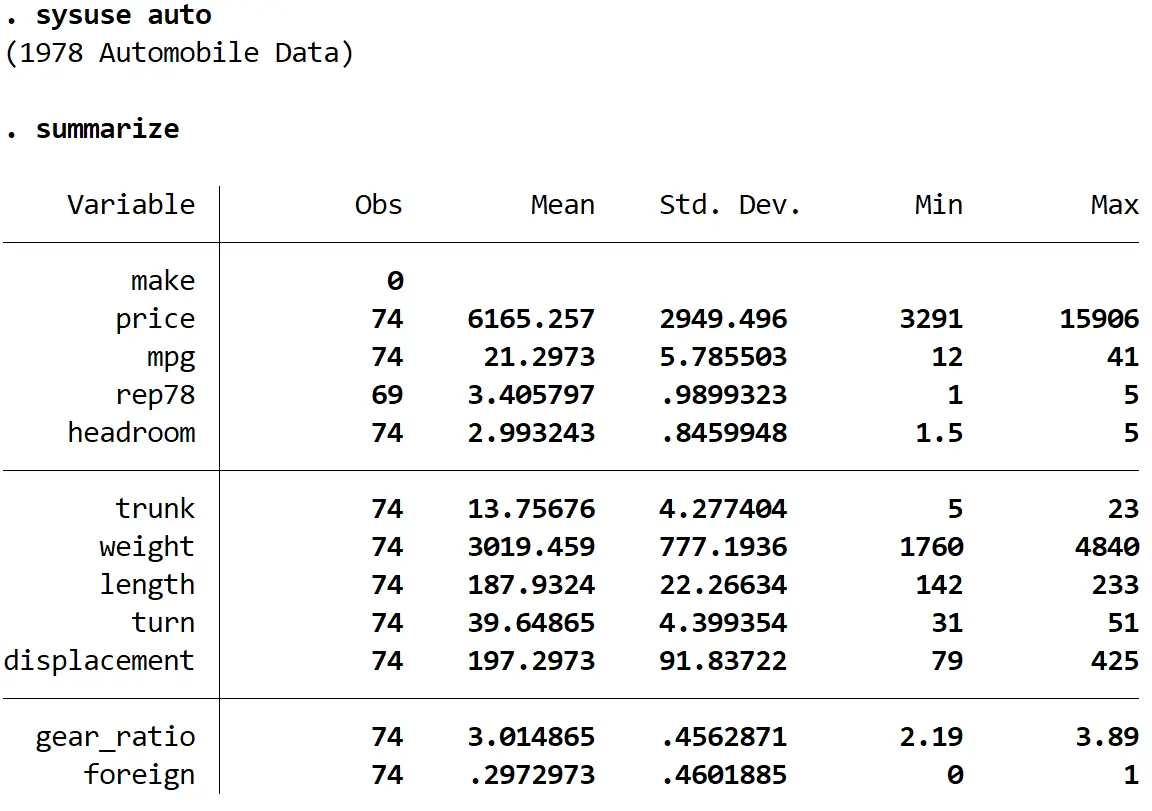
Następnie uzyskamy szybkie podsumowanie danych za pomocą następującego polecenia:
podsumować
Krok 2: Dopasuj model regresji.
Następnie użyjemy następującego polecenia, aby dopasować model regresji:
regresja cena mpg przemieszczenie
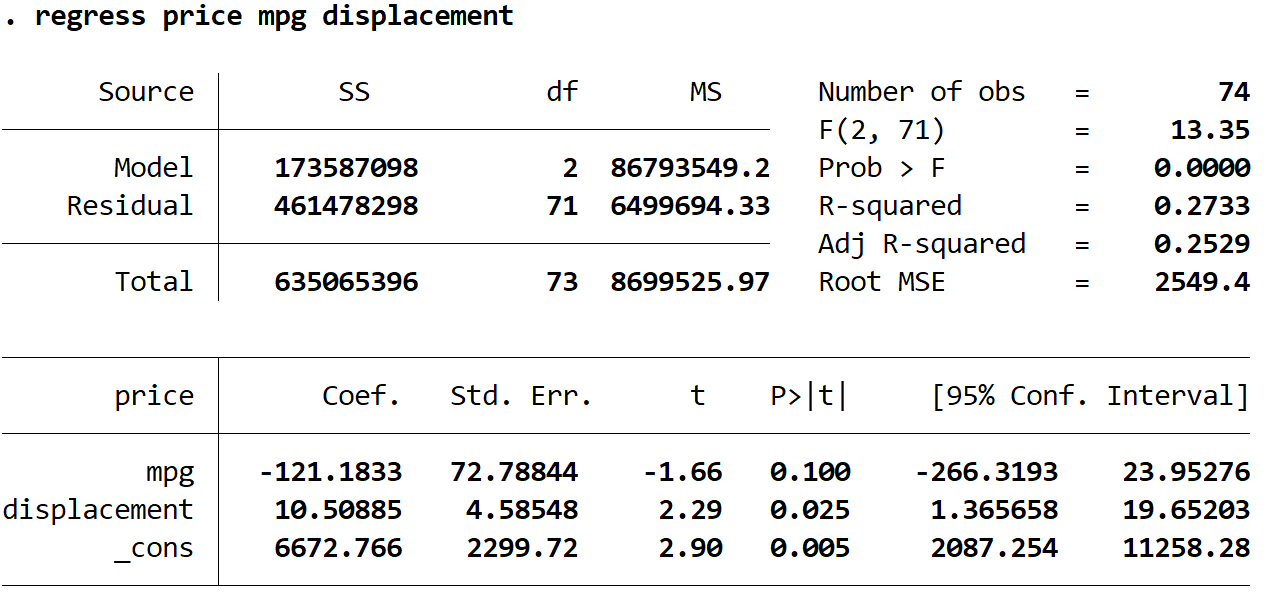
Szacowane równanie regresji to:
szacunkowa cena = 6672,766 -121,1833*(mpg) + 10,50885*(pojemność)
Krok 3: Uzyskaj przewidywane wartości.
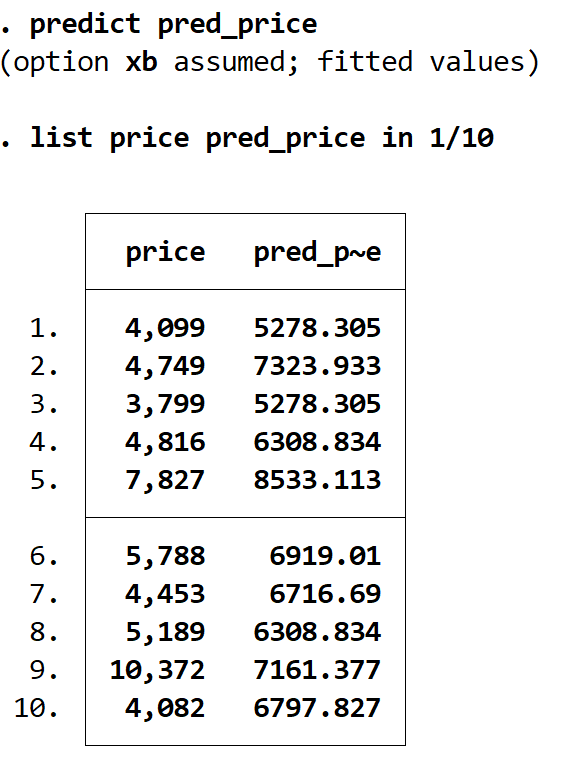
Przewidywane wartości możemy uzyskać za pomocą polecenia przewidywania i przechowywania tych wartości w zmiennej o dowolnej nazwie. W tym przypadku użyjemy nazwy pred_price :
przewiduj pred_price
Za pomocą polecenia list możemy wyświetlić obok siebie ceny aktualne i ceny przewidywane. W sumie przewidywanych wartości jest 74, ale my wyświetlimy tylko pierwsze 10 za pomocą polecenia in 1/10 :
cena katalogowa pred_price w 1/10
Krok 4: Zdobądź pozostałość.
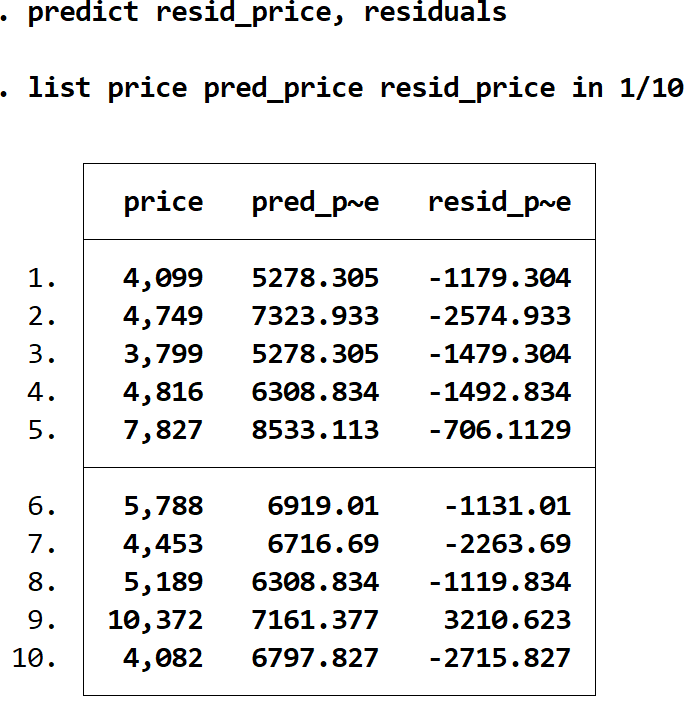
Reszty każdej prognozy możemy uzyskać za pomocą polecenia reszt i przechowując te wartości w zmiennej o dowolnej nazwie. W tym przypadku użyjemy nazwy resid_price :
przewidzieć cenę_rezydencji, pozostałości
Możemy wyświetlić obok siebie cenę rzeczywistą, cenę oczekiwaną i resztę, używając ponownie polecenia list :
cena katalogowa pred_price resid_price w 1/10
Krok 5: Utwórz wykres przewidywanych wartości względem reszt.
Na koniec możemy stworzyć wykres rozrzutu, aby zwizualizować związek między przewidywanymi wartościami a resztami:
dyspersja rezydencja_cena pred_cena
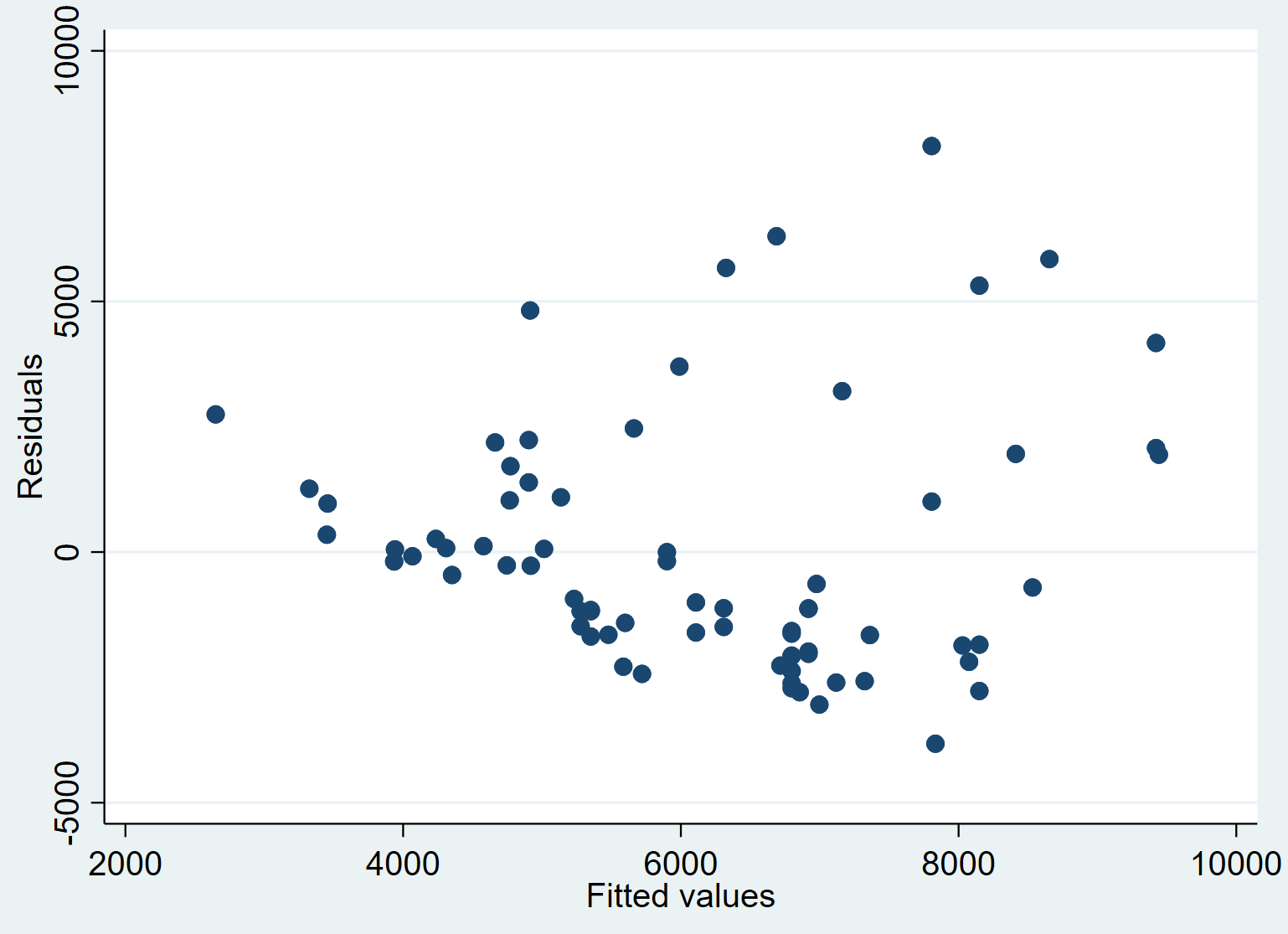
Widzimy, że średnio reszty mają tendencję do zwiększania się wraz ze wzrostem dopasowanych wartości. Może to być oznaką heteroskedastyczności – gdy rozkład reszt nie jest stały na każdym poziomie odpowiedzi.
Moglibyśmy formalnie przetestować heteroskedastyczność za pomocą testu Breuscha-Pagana i rozwiązać ten problem za pomocą solidnych błędów standardowych .
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej