Jak wygenerować rozkład normalny w pythonie (z przykładami)
Możesz szybko wygenerować rozkład normalny w Pythonie za pomocą funkcji numpy.random.normal() , która wykorzystuje następującą składnię:
numpy. random . normal (loc=0.0, scale=1.0, size=None)
Złoto:
- loc: Średnia dystrybucji. Wartość domyślna to 0.
- skala: Odchylenie standardowe rozkładu. Wartość domyślna to 1.
- rozmiar: wielkość próbki.
W tym samouczku pokazano przykład użycia tej funkcji do wygenerowania rozkładu normalnego w Pythonie.
Powiązane: Jak utworzyć krzywą dzwonową w Pythonie
Przykład: generowanie rozkładu normalnego w Pythonie
Poniższy kod pokazuje, jak wygenerować rozkład normalny w Pythonie:
from numpy. random import seed
from numpy. random import normal
#make this example reproducible
seed(1)
#generate sample of 200 values that follow a normal distribution
data = normal (loc=0, scale=1, size=200)
#view first six values
data[0:5]
array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
Możemy szybko znaleźć średnią i odchylenie standardowe tego rozkładu:
import numpy as np
#find mean of sample
n.p. mean (data)
0.1066888148479486
#find standard deviation of sample
n.p. std (data, ddof= 1 )
0.9123296653173484
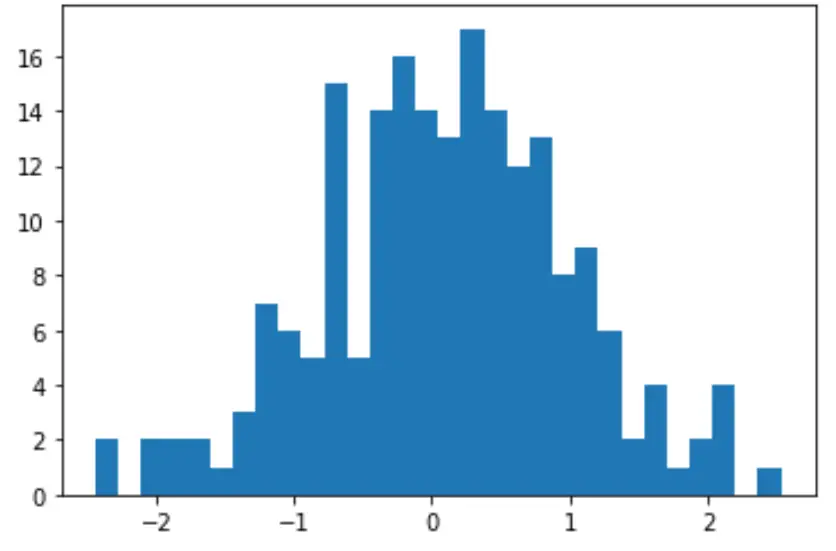
Możemy również utworzyć szybki histogram w celu wizualizacji rozkładu wartości danych:
import matplotlib. pyplot as plt
count, bins, ignored = plt. hist (data, 30)
plt. show ()
Możemy nawet wykonać test Shapiro-Wilka, aby sprawdzić, czy zbiór danych pochodzi z normalnej populacji:
from scipy. stats import shapiro
#perform Shapiro-Wilk test
shapiro(data)
ShapiroResult(statistic=0.9958659410, pvalue=0.8669294714)
Wartość p testu wynosi 0,8669 . Ponieważ wartość ta jest nie mniejsza niż 0,05, możemy założyć, że przykładowe dane pochodzą z populacji o rozkładzie normalnym.
Wynik ten nie powinien być zaskakujący, ponieważ dane wygenerowaliśmy za pomocą funkcji numpy.random.normal() , która generuje losową próbkę danych z rozkładu normalnego.
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej