Jak wygenerować rozkład normalny w r (z przykładami)
Możesz szybko wygenerować rozkład normalny w R za pomocą funkcji rnorm() , która wykorzystuje następującą składnię:
rnorm(n, mean=0, sd=1)
Złoto:
- n: Liczba obserwacji.
- średnia: średnia rozkładu normalnego. Wartość domyślna to 0.
- sd: odchylenie standardowe rozkładu normalnego. Wartość domyślna to 1.
W tym samouczku pokazano przykład użycia tej funkcji do wygenerowania rozkładu normalnego w języku R.
Powiązane: Przewodnik po dnorm, pnorm, qnorm i rnorm w R
Przykład: generowanie rozkładu normalnego w R
Poniższy kod pokazuje, jak wygenerować rozkład normalny w R:
#make this example reproducible set.seed(1) #generate sample of 200 obs. that follows normal dist. with mean=10 and sd=3 data <- rnorm(200, mean=10, sd=3) #view first 6 observations in sample head(data) [1] 8.120639 10.550930 7.493114 14.785842 10.988523 7.538595
Możemy szybko znaleźć średnią i odchylenie standardowe tego rozkładu:
#find mean of sample
mean(data)
[1] 10.10662
#find standard deviation of sample
sd(data)
[1] 2.787292
Możemy również utworzyć szybki histogram w celu wizualizacji rozkładu wartości danych:
hist(data, col=' steelblue ')
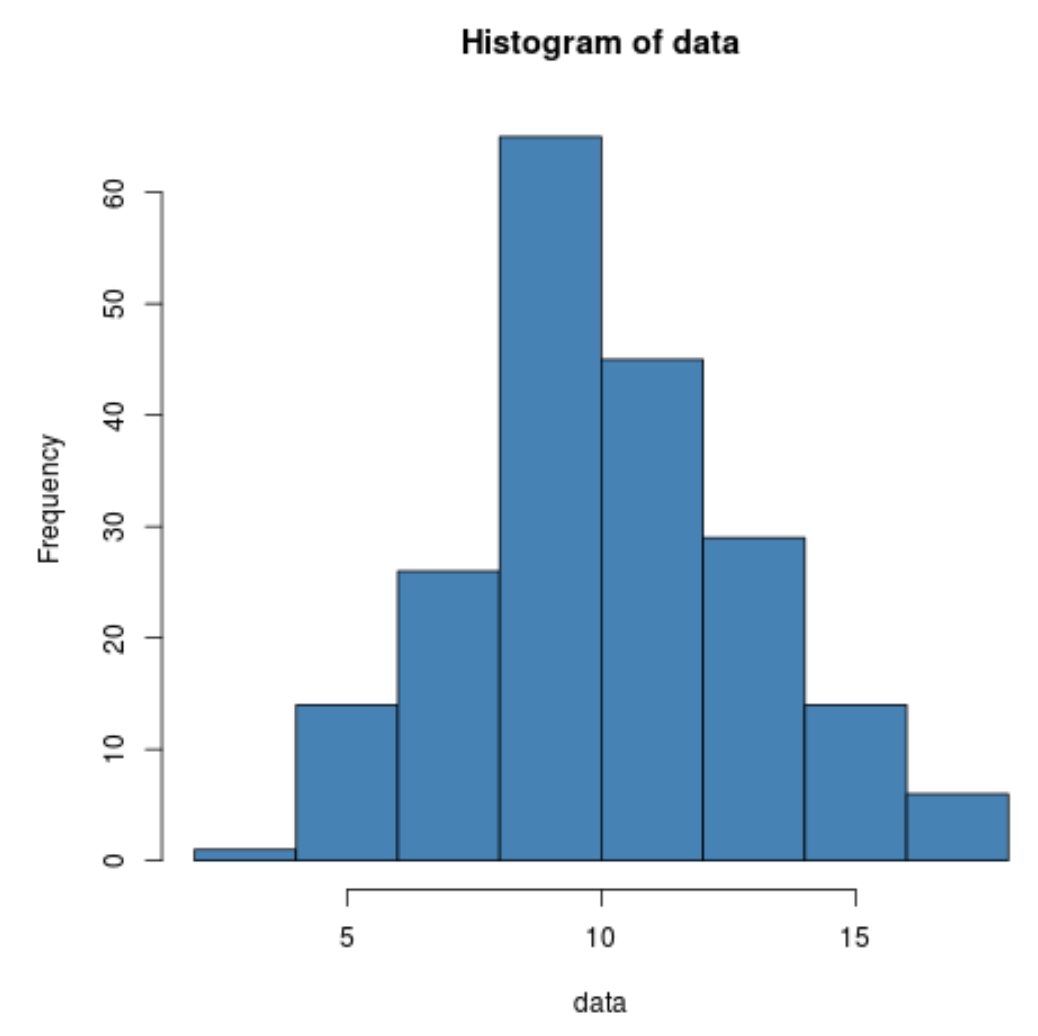
Możemy nawet wykonaćtest Shapiro-Wilka, aby sprawdzić, czy zbiór danych pochodzi z normalnej populacji:
shapiro.test(data)
Shapiro-Wilk normality test
data:data
W = 0.99274, p-value = 0.4272
Wartość p testu wynosi 0,4272 . Ponieważ wartość ta jest nie mniejsza niż 0,05, możemy założyć, że przykładowe dane pochodzą z populacji o rozkładzie normalnym.
Wynik ten nie powinien być zaskakujący, ponieważ dane wygenerowaliśmy za pomocą funkcji rnorm() , która w naturalny sposób generuje losową próbkę danych z rozkładu normalnego.
Dodatkowe zasoby
Jak wykreślić rozkład normalny w R
Przewodnik po dnorm, pnorm, qnorm i rnorm w R
Jak wykonać test Shapiro-Wilka na normalność w R
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej