Jak wyśrodkować dane w r (z przykładami)
Centrowanie zbioru danych oznacza odjęcie średniej wartości każdej pojedynczej obserwacji w zbiorze danych.
Załóżmy na przykład, że mamy następujący zestaw danych:
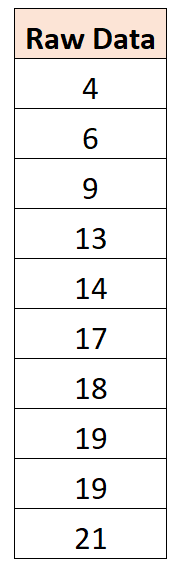
Okazuje się, że średnia wartość wynosi 14. Aby więc wyśrodkować ten zbiór danych, od każdej indywidualnej obserwacji odejmiemy 14:
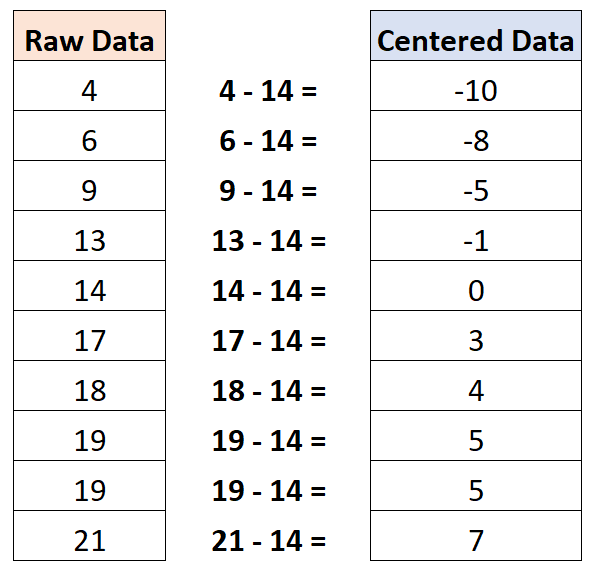
Należy zauważyć, że średnia wartość wyśrodkowanego zbioru danych wynosi zero.
W tym samouczku przedstawiono kilka przykładów wyśrodkowania danych w języku R.
Przykład 1: Wyśrodkuj wartości wektora
Poniższy kod pokazuje, jak użyć podstawowej funkcji Rscale() do wyśrodkowania wartości w wektorze:
#createvector data <- c(4, 6, 9, 13, 14, 17, 18, 19, 19, 21) #subtract the mean value from each observation in the vector scale(data, scale= FALSE ) [,1] [1,] -10 [2,] -8 [3,] -5 [4,] -1 [5,] 0 [6,] 3 [7,] 4 [8,] 5 [9,] 5 [10,] 7 attr(,"scaled:center") [1] 14
Wynikowe wartości są wyśrodkowanymi wartościami zbioru danych. Funkcja skala() mówi nam również, że średnia wartość zbioru danych wynosi 14.
Należy zauważyć, że funkcjascale () domyślnie odejmuje średnią z każdej indywidualnej obserwacji, a następnie dzieli ją przez odchylenie standardowe.
Podając skalę=FAŁSZ, mówimy R, aby nie dzielił przez odchylenie standardowe.
Przykład 2: Wyśrodkuj kolumny w ramce danych
Poniższy kod pokazuje, jak używać funkcji sapply() i funkcjiscale() bazy danych R do wyśrodkowania wartości każdej kolumny ramki danych:
#create data frame df <- data.frame(x = c(1, 4, 5, 6, 6, 8, 9), y = c(7, 7, 8, 8, 8, 9, 12), z = c(3, 3, 4, 4, 6, 7, 7)) #center each column in the data frame df_new <- sapply(df, function (x) scale(x, scale= FALSE )) #display data frame df_new X Y Z [1,] -4.5714286 -1.4285714 -1.8571429 [2,] -1.5714286 -1.4285714 -1.8571429 [3,] -0.5714286 -0.4285714 -0.8571429 [4,] 0.4285714 -0.4285714 -0.8571429 [5,] 0.4285714 -0.4285714 1.1428571 [6,] 2.4285714 0.5714286 2.1428571 [7,] 3.4285714 3.5714286 2.1428571
Możemy sprawdzić, czy średnia każdej kolumny w nowej ramce danych wynosi zero, korzystając z funkcji colMeans() :
colMeans(df_new)
xyz 2.537653e-16 -2.537653e-16 3.806479e-16
Wartości są pokazane w notacji naukowej, ale każda wartość jest w zasadzie zerowa.
Dodatkowe zasoby
Jak uśredniać kolumny w R
Jak sumować określone kolumny w R
Jak usunąć wartości odstające z wielu kolumn w R
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej