Kompletny przewodnik po zbiorze danych iris w r
Zbiór danych tęczówki to zintegrowany zbiór danych w języku R, który zawiera pomiary 4 różnych atrybutów (w centymetrach) dla 50 kwiatów 3 różnych gatunków.
W tym samouczku wyjaśniono, jak eksplorować i podsumowywać zbiór danych w języku R na przykładzie zbioru danych iris.
Powiązane: Kompletny przewodnik po zbiorze danych mtcars w języku R
Załaduj zbiór danych Iris
Ponieważ zbiór danych iris jest wbudowanym zbiorem danych w R, możemy go załadować za pomocą następującego polecenia:
data(iris)
Możemy przyjrzeć się pierwszym sześciu wierszom zbioru danych za pomocą funkcji head() :
#view first six rows of iris dataset
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
Podsumuj zbiór danych Iris
Możemy użyć funkcji podsumowania() , aby szybko podsumować każdą zmienną w zbiorze danych:
#summarize iris dataset
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4,300 Min. :2,000 Min. :1,000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median: 5,800 Median: 3,000 Median: 4,350 Median: 1,300
Mean:5.843 Mean:3.057 Mean:3.758 Mean:1.199
3rd Qu.:6,400 3rd Qu.:3,300 3rd Qu.:5,100 3rd Qu.:1,800
Max. :7,900 Max. :4,400 Max. :6,900 Max. :2,500
Species
setosa:50
versicolor:50
virginica :50
Dla każdej ze zmiennych numerycznych możemy zobaczyć następujące informacje:
- Min .: Wartość minimalna.
- 1. Qu : Wartość pierwszego kwartyla (25. percentyl).
- Mediana : Wartość mediana.
- Średnia : Wartość średnia.
- 3rd Qu : Wartość trzeciego kwartyla (75. percentyl).
- Maks .: Wartość maksymalna.
Dla jedynej zmiennej kategorycznej w zbiorze danych (gatunki) widzimy częstotliwość występowania każdej wartości:
- setosa : gatunek ten występuje 50 razy.
- versicolor : Gatunek ten występuje 50 razy.
- virginica : gatunek ten występuje 50 razy.
Możemy użyć funkcji dim() , aby uzyskać wymiary zbioru danych pod względem liczby wierszy i kolumn:
#display rows and columns
dim(iris)
[1] 150 5
Widzimy, że zbiór danych ma 150 wierszy i 5 kolumn.
Możemy również użyć funkcji Names() do wyświetlenia nazw kolumn ramki danych:
#display column names
names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
Wizualizuj zbiór danych Iris
Możemy także tworzyć wykresy w celu wizualizacji wartości zbioru danych.
Możemy na przykład użyć funkcji hist() do stworzenia histogramu wartości określonej zmiennej:
#create histogram of values for sepal length
hist(iris$Sepal.Length,
col=' steelblue ',
main=' Histogram ',
xlab=' Length ',
ylab=' Frequency ')
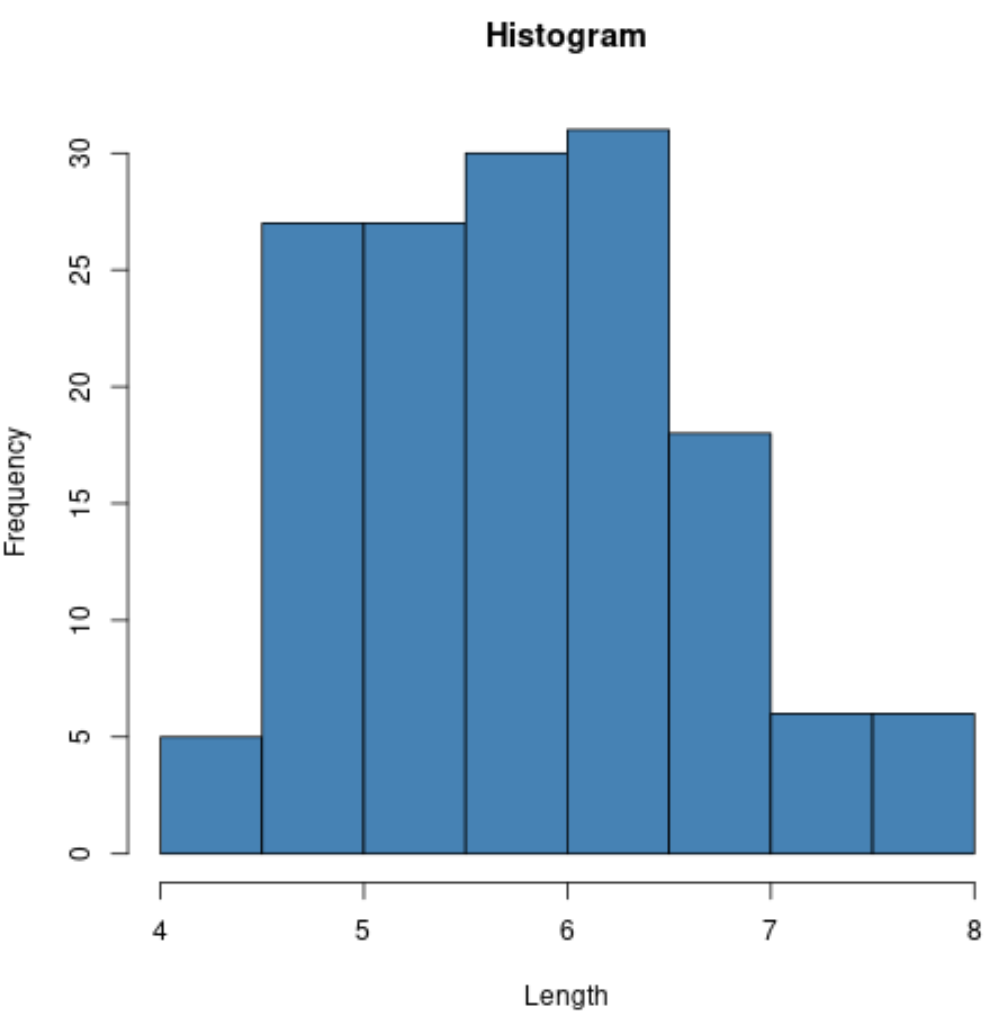
Możemy również użyć funkcji plot() do utworzenia wykresu rozrzutu dowolnej kombinacji zmiennych parami:
#create scatterplot of sepal width vs. sepal length
plot(iris$Sepal.Width, iris$Sepal.Length,
col=' steelblue ',
main=' Scatterplot ',
xlab=' Sepal Width ',
ylab=' Sepal Length ',
pch= 19 )
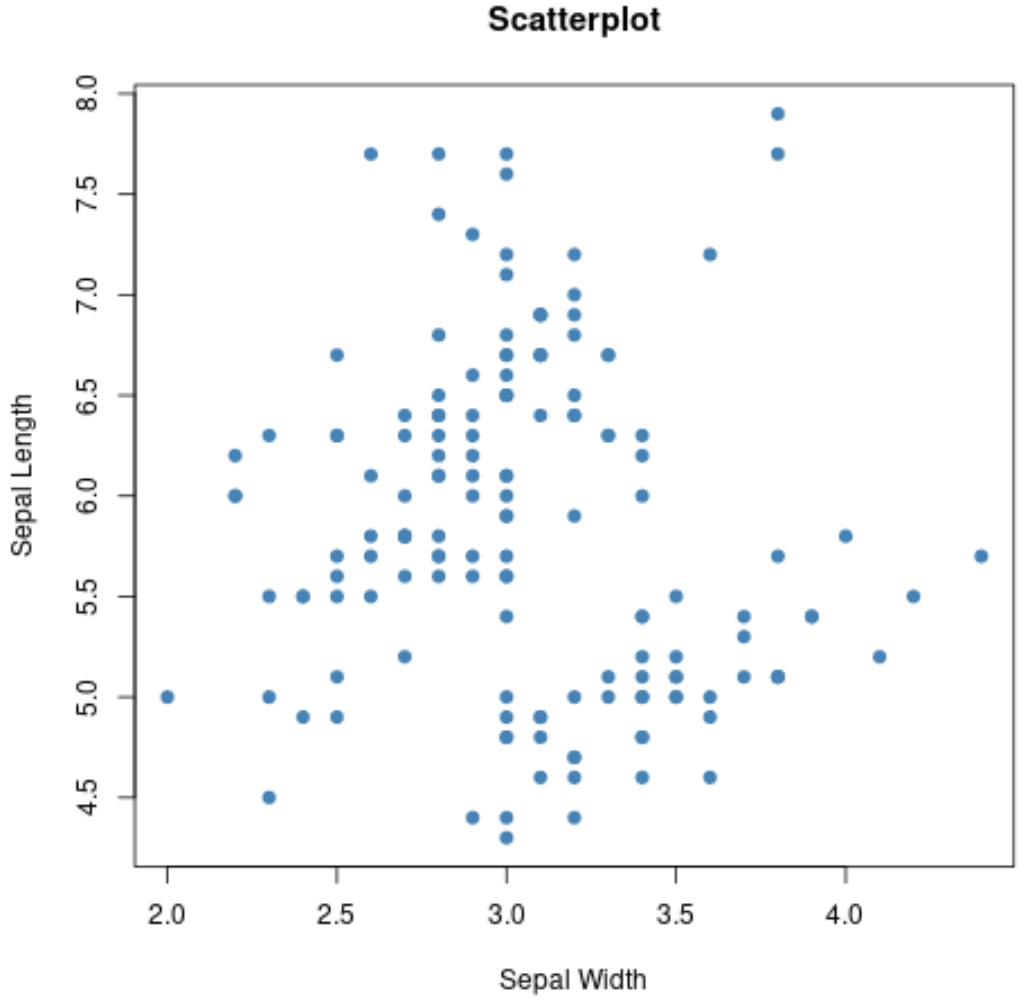
Możemy również użyć funkcji boxplot() , aby utworzyć wykres pudełkowy dla każdej grupy:
#create scatterplot of sepal width vs. sepal length
boxplot(Sepal.Length~Species,
data=iris,
main=' Sepal Length by Species ',
xlab=' Species ',
ylab=' Sepal Length ',
col=' steelblue ',
border=' black ')
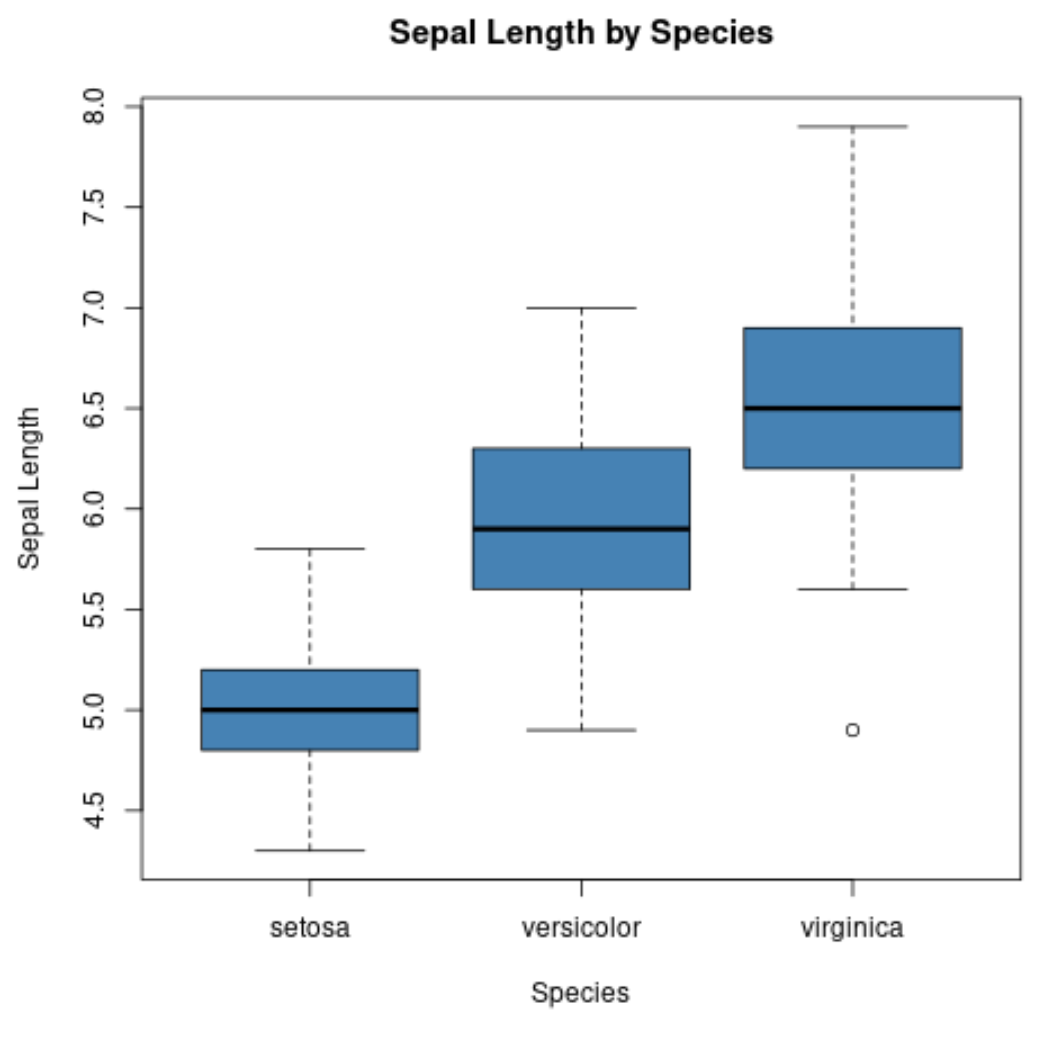
Oś x przedstawia trzy gatunki, a oś y przedstawia rozkład wartości długości działek dla każdego gatunku.
Ten typ wykresu pozwala nam szybko zauważyć, że długość działek jest zwykle największa u gatunku Virginia, a najmniejsza u gatunku setosa.
Dodatkowe zasoby
Poniższe samouczki wyjaśniają bardziej szczegółowo, jak podsumowywać zbiory danych w R:
Najłatwiejszy sposób tworzenia tabel podsumowań w R
Jak obliczyć podsumowanie pięciu liczb w R
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej