Jak obliczyć odległość cooka w pythonie
Odległość Cooka służy do identyfikacji wpływowych obserwacji w modelu regresji.
Wzór na odległość Cooka to:
re ja = (r ja 2 / p*MSE) * (h ii / (1-h ii ) 2 )
Złoto:
- r i jest i- tą resztą
- p to liczba współczynników w modelu regresji
- MSE to błąd średniokwadratowy
- h ii to i- wartość dźwigni
Zasadniczo odległość Cooka mierzy, jak bardzo zmienią się wszystkie dopasowane wartości modelu po usunięciu i- tej obserwacji.
Im większa wartość odległości Cooka, tym większy wpływ ma dana obserwacja.
Z reguły każdą obserwację z odległością Cooka większą niż 4/n (gdzie n = liczba obserwacji ogółem) uważa się za mającą duży wpływ.
W tym samouczku przedstawiono krok po kroku przykład obliczenia odległości Cooka dla danego modelu regresji w języku Python.
Krok 1: Wprowadź dane
Najpierw utworzymy mały zbiór danych do pracy w Pythonie:
import pandas as pd #create dataset df = pd. DataFrame ({' x ': [8, 12, 12, 13, 14, 16, 17, 22, 24, 26, 29, 30], ' y ': [41, 42, 39, 37, 35, 39, 45, 46, 39, 49, 55, 57]})
Krok 2: Dopasuj model regresji
Następnie dopasujemy prosty model regresji liniowej :
import statsmodels. api as sm
#define response variable
y = df[' y ']
#define explanatory variable
x = df[' x ']
#add constant to predictor variables
x = sm. add_constant (x)
#fit linear regression model
model = sm. OLS (y,x). fit ()
Krok 3: Oblicz odległość gotowania
Następnie obliczymy odległość Cooka dla każdej obserwacji w modelu:
#suppress scientific notation
import numpy as np
n.p. set_printoptions (suppress= True )
#create instance of influence
influence = model. get_influence ()
#obtain Cook's distance for each observation
cooks = influence. cooks_distance
#display Cook's distances
print (cooks)
(array([0.368, 0.061, 0.001, 0.028, 0.105, 0.022, 0.017, 0. , 0.343,
0. , 0.15 , 0.349]),
array([0.701, 0.941, 0.999, 0.973, 0.901, 0.979, 0.983, 1. , 0.718,
1. , 0.863, 0.713]))
Domyślnie funkcja Cooks_distance() wyświetla tablicę wartości odległości Cooka dla każdej obserwacji, po której następuje tablica odpowiednich wartości p.
Na przykład:
- Odległość Cooka dla obserwacji nr 1: 0,368 (wartość p: 0,701)
- Odległość Cooka dla obserwacji nr 2: 0,061 (wartość p: 0,941)
- Odległość Cooka dla obserwacji nr 3: 0,001 (wartość p: 0,999)
I tak dalej.
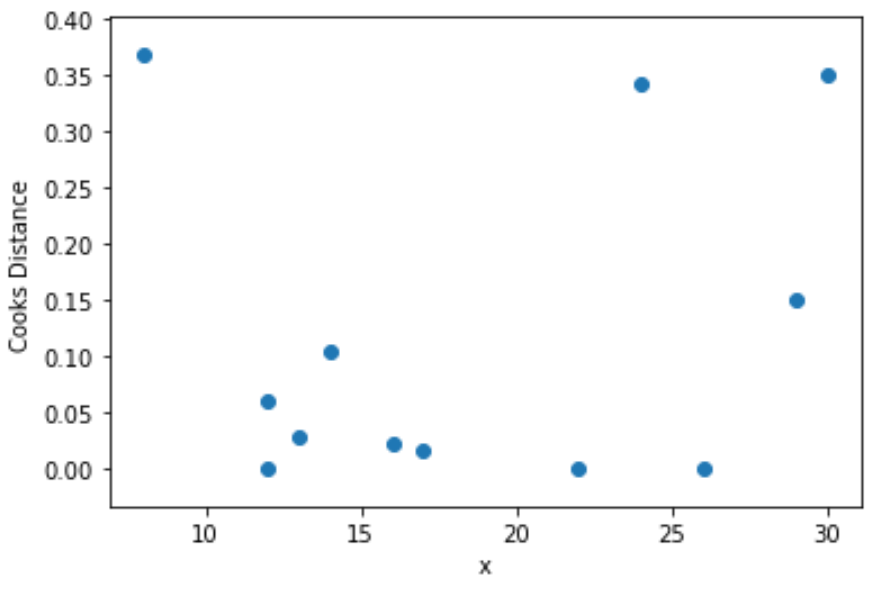
Krok 4: Wizualizuj odległości kucharza
Na koniec możemy utworzyć wykres rozrzutu, aby zwizualizować wartości zmiennej predykcyjnej w funkcji odległości Cooka dla każdej obserwacji:
import matplotlib. pyplot as plt
plt. scatter (df.x, cooks[0])
plt. xlabel (' x ')
plt. ylabel (' Cooks Distance ')
plt. show ()
Końcowe przemyślenia
Należy zauważyć, że do identyfikacji potencjalnie wpływających obserwacji należy stosować odległość Cooka. To, że obserwacja ma wpływ, nie oznacza, że należy ją usunąć ze zbioru danych.
Najpierw należy sprawdzić, czy obserwacja nie jest wynikiem błędu we wpisie danych lub innego dziwnego zdarzenia. Jeśli okaże się, że jest to prawidłowa wartość, możesz zdecydować, czy należy ją usunąć, pozostawić bez zmian, czy po prostu zastąpić ją wartością alternatywną, taką jak mediana.
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej