Jak obliczyć średnią ruchomą w pandach
Średnia ruchoma to po prostu średnia liczby poprzednich okresów w szeregu czasowym.
Aby obliczyć średnią kroczącą jednej lub większej liczby kolumn w ramce DataFrame pand, możemy zastosować następującą składnię:
df[' column_name ']. rolling ( rolling_window ). mean ()
W tym samouczku przedstawiono kilka przykładów praktycznego wykorzystania tej funkcji.
Przykład: obliczanie średniej ruchomej w pandach
Załóżmy, że mamy następującą ramkę DataFrame pand:
import numpy as np import pandas as pd #make this example reproducible n.p. random . seeds (0) #create dataset period = np. arange (1, 101, 1) leads = np. random . uniform (1, 20, 100) sales = 60 + 2*period + np. random . normal (loc=0, scale=.5*period, size=100) df = pd. DataFrame ({' period ': period, ' leads ': leads, ' sales ': sales}) #view first 10 rows df. head (10) period leads sales 0 1 11.427457 61.417425 1 2 14.588598 64.900826 2 3 12.452504 66.698494 3 4 11.352780 64.927513 4 5 9.049441 73.720630 5 6 13.271988 77.687668 6 7 9.314157 78.125728 7 8 17.943687 75.280301 8 9 19.309592 73.181613 9 10 8.285389 85.272259
Możemy użyć następującej składni, aby utworzyć nową kolumnę zawierającą średnią ruchomą „sprzedaży” z poprzednich 5 okresów:
#find rolling mean of previous 5 sales periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 0 1 11.427457 61.417425 NaN 1 2 14.588598 64.900826 NaN 2 3 12.452504 66.698494 NaN 3 4 11.352780 64.927513 NaN 4 5 9.049441 73.720630 66.332978 5 6 13.271988 77.687668 69.587026 6 7 9.314157 78.125728 72.232007 7 8 17.943687 75.280301 73.948368 8 9 19.309592 73.181613 75.599188 9 10 8.285389 85.272259 77.909514
Możemy ręcznie sprawdzić, czy krocząca średnia sprzedaży wyświetlana dla okresu 5 jest średnią z poprzednich 5 okresów:
Średnia krocząca w okresie 5: (61,417+64,900+66,698+64,927+73,720)/5 = 66,33
Możemy użyć podobnej składni do obliczenia średniej ruchomej wielu kolumn:
#find rolling mean of previous 5 leads periods df[' rolling_leads_5 '] = df[' leads ']. rolling (5). mean () #find rolling mean of previous 5 leads periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 rolling_leads_5 0 1 11.427457 61.417425 NaN NaN 1 2 14.588598 64.900826 NaN NaN 2 3 12.452504 66.698494 NaN NaN 3 4 11.352780 64.927513 NaN NaN 4 5 9.049441 73.720630 66.332978 11.774156 5 6 13.271988 77.687668 69.587026 12.143062 6 7 9.314157 78.125728 72.232007 11.088174 7 8 17.943687 75.280301 73.948368 12.186411 8 9 19.309592 73.181613 75.599188 13.777773 9 10 8.285389 85.272259 77.909514 13.624963
Możemy również utworzyć szybki wykres liniowy za pomocą Matplotlib do wizualizacji sprzedaży brutto w porównaniu ze średnią ruchomą sprzedaży:
import matplotlib. pyplot as plt
plt. plot (df[' rolling_sales_5 '], label=' Rolling Mean ')
plt. plot (df[' sales '], label=' Raw Data ')
plt. legend ()
plt. ylabel (' Sales ')
plt. xlabel (' Period ')
plt. show ()
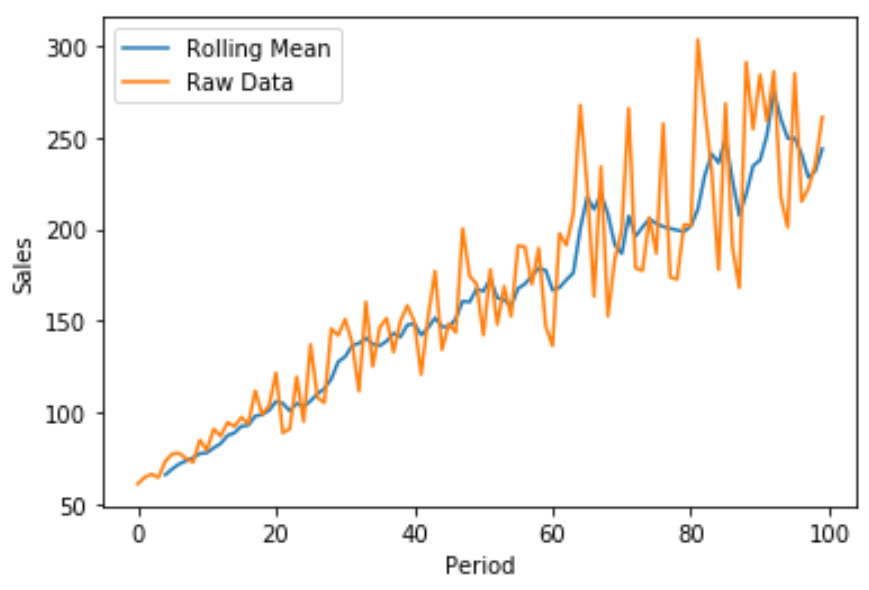
Niebieska linia pokazuje 5-okresową średnią ruchomą sprzedaży, a pomarańczowa linia pokazuje surowe dane dotyczące sprzedaży.
Dodatkowe zasoby
Poniższe samouczki wyjaśniają, jak wykonywać inne typowe zadania w pandach:
Jak obliczyć korelację przesuwną w pandach
Jak obliczyć średnią kolumn w Pandach
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej