Como centralizar dados em r (com exemplos)
Centralizar um conjunto de dados significa subtrair o valor médio de cada observação individual no conjunto de dados.
Por exemplo, suponha que temos o seguinte conjunto de dados:
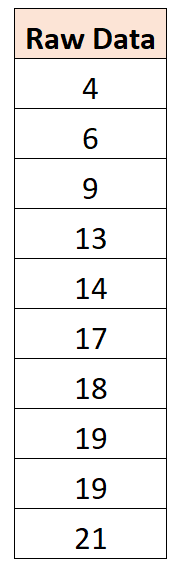
Acontece que o valor médio é 14. Portanto, para centralizar este conjunto de dados, subtrairíamos 14 de cada observação individual:
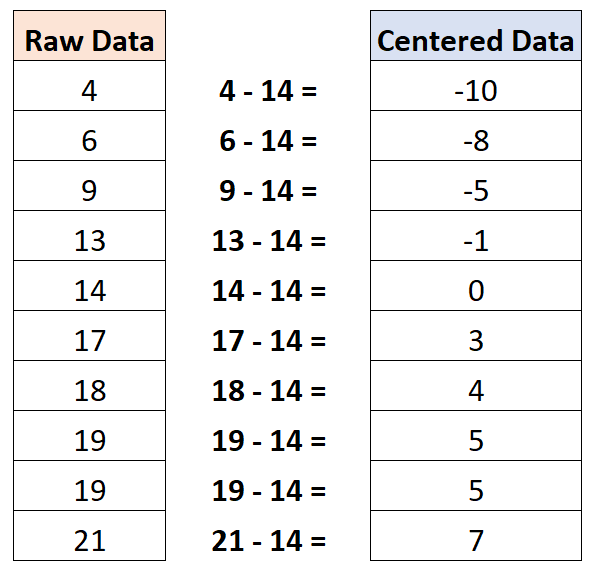
Observe que o valor médio do conjunto de dados centralizado é zero.
Este tutorial fornece vários exemplos de como centralizar dados em R.
Exemplo 1: Centralize os valores de um vetor
O código a seguir mostra como usar a função base R scale() para centralizar valores em um vetor:
#createvector data <- c(4, 6, 9, 13, 14, 17, 18, 19, 19, 21) #subtract the mean value from each observation in the vector scale(data, scale= FALSE ) [,1] [1,] -10 [2,] -8 [3,] -5 [4,] -1 [5,] 0 [6,] 3 [7,] 4 [8,] 5 [9,] 5 [10,] 7 attr(,"scaled:center") [1] 14
Os valores resultantes são os valores centralizados do conjunto de dados. A função scale() também nos diz que o valor médio do conjunto de dados é 14.
Observe que a função scale() , por padrão, subtrai a média de cada observação individual e depois a divide pelo desvio padrão.
Ao especificar scale=FALSE dizemos a R para não dividir pelo desvio padrão.
Exemplo 2: Centralizar colunas em um quadro de dados
O código a seguir mostra como usar a função sapply() e a função scale() do banco de dados R para centralizar os valores de cada coluna de um quadro de dados:
#create data frame df <- data.frame(x = c(1, 4, 5, 6, 6, 8, 9), y = c(7, 7, 8, 8, 8, 9, 12), z = c(3, 3, 4, 4, 6, 7, 7)) #center each column in the data frame df_new <- sapply(df, function (x) scale(x, scale= FALSE )) #display data frame df_new X Y Z [1,] -4.5714286 -1.4285714 -1.8571429 [2,] -1.5714286 -1.4285714 -1.8571429 [3,] -0.5714286 -0.4285714 -0.8571429 [4,] 0.4285714 -0.4285714 -0.8571429 [5,] 0.4285714 -0.4285714 1.1428571 [6,] 2.4285714 0.5714286 2.1428571 [7,] 3.4285714 3.5714286 2.1428571
Podemos verificar se a média de cada coluna no novo quadro de dados é zero usando a função colMeans() :
colMeans(df_new)
xyz 2.537653e-16 -2.537653e-16 3.806479e-16
Os valores são mostrados em notação científica, mas cada valor é essencialmente zero.
Recursos adicionais
Como calcular a média das colunas em R
Como somar colunas específicas em R
Como remover outliers de múltiplas colunas em R
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais