Distribuição de frequência não agrupada: definição e exemplo
Suponhamos que realizamos um inquérito no qual perguntamos a 15 famílias quantos animais têm em casa. Os resultados são os seguintes:
1, 1, 1, 1, 2, 2, 2, 3, 3, 4, 5, 5, 6, 7, 8
Uma forma de resumir esses resultados é criar uma distribuição de frequência , que nos informa com que frequência valores diferentes aparecem em um conjunto de dados.
Freqüentemente usamos distribuições de frequência agrupadas , nas quais criamos grupos de valores e depois resumimos o número de observações em um conjunto de dados que se enquadram nesses grupos.
Aqui está um exemplo de distribuição de frequência agrupada para nossos dados de pesquisa:
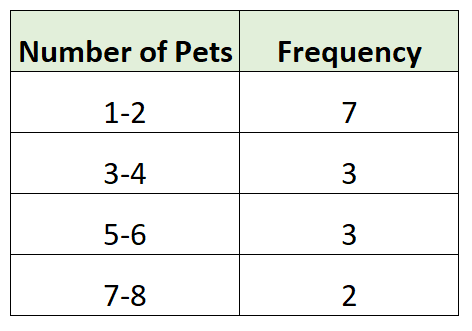
Primeiro criamos grupos de tamanho 2 e depois contamos o número de observações individuais do conjunto de dados que se enquadram em cada grupo. Por exemplo:
- 7 famílias tinham 1 ou 2 animais
- 3 famílias tinham 3 ou 4 animais
- 3 famílias tinham 5 ou 6 animais
- 2 famílias tinham 7 ou 8 animais
Outro tipo de distribuição de frequência que poderíamos criar é uma distribuição de frequência desagrupada , que exibe a frequência de cada valor de dados individual em vez de grupos de valores de dados.
Aqui está um exemplo de distribuição de frequência não agrupada para nossos dados de pesquisa:
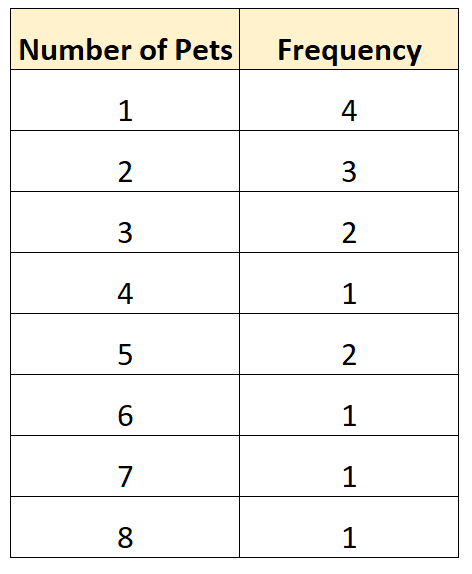
Este tipo de distribuição de frequência nos permite ver diretamente com que frequência valores diferentes ocorreram em nosso conjunto de dados. Por exemplo:
- 4 famílias tinham 1 animal
- 3 famílias tinham 2 animais
- 2 famílias tinham 3 animais
- 1 família tinha 4 animais
E assim por diante.
Quando usar distribuições de frequência desagrupadas
Distribuições de frequência desagrupadas podem ser úteis quando você deseja ver com que frequência cada valor individual aparece em um conjunto de dados.
Observe que as distribuições de frequência não agrupadas funcionam melhor com pequenos conjuntos de dados nos quais existem apenas alguns valores exclusivos.
Por exemplo, nos dados da nossa pesquisa anterior, havia apenas 8 valores únicos, por isso fazia sentido criar uma distribuição de frequência não agrupada.
No entanto, se tivéssemos um conjunto de milhares de dados contendo centenas ou valores únicos, uma distribuição de frequência não agrupada consumiria muito tempo e seria difícil coletar informações.
Para conjuntos de dados maiores, faz sentido construir distribuições de frequência agrupadas.
Como visualizar distribuições de frequência desagrupadas
A maneira mais simples de visualizar os valores em uma distribuição de frequência desagrupada é criar um polígono de frequência , que exibe as frequências de cada valor individual em um gráfico simples.
Esta é a aparência de um polígono de frequência para nossos dados de amostra:
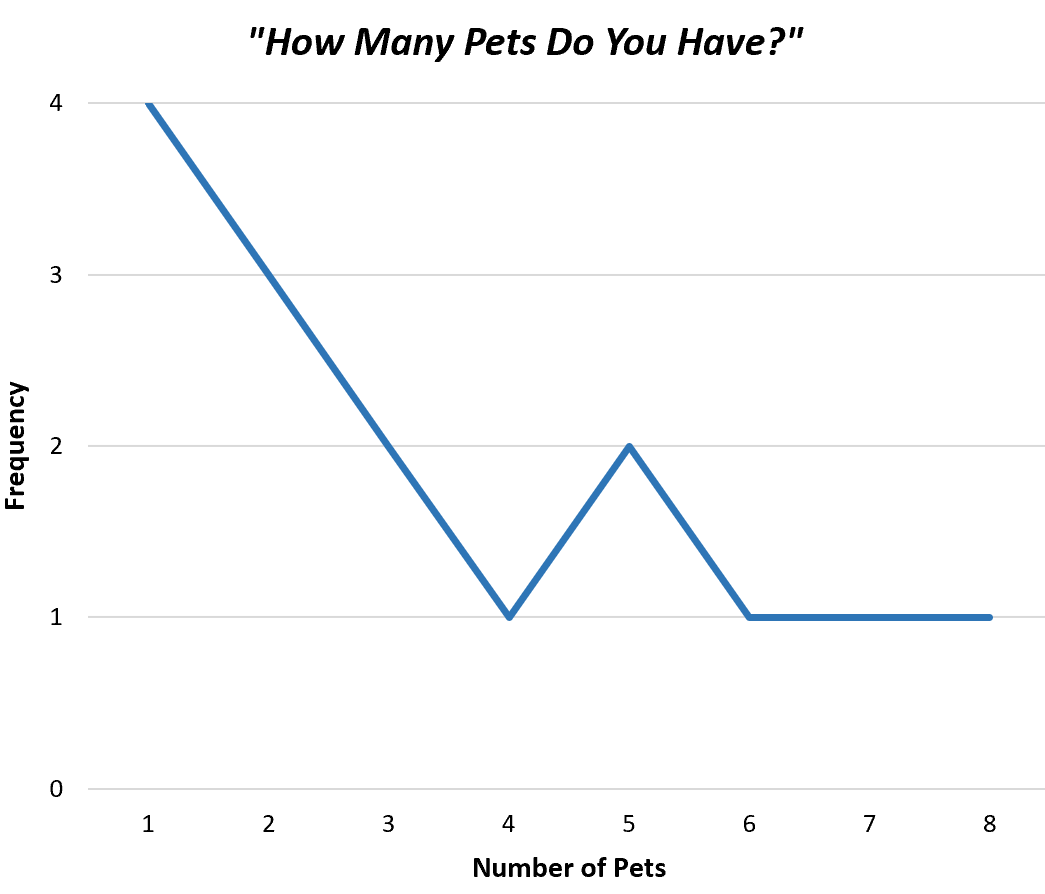
Isso nos ajuda a entender rapidamente com que frequência cada valor aparece no conjunto de dados.
Alternativamente, poderíamos criar um gráfico de barras para exibir exatamente os mesmos dados usando barras em vez de uma única linha:
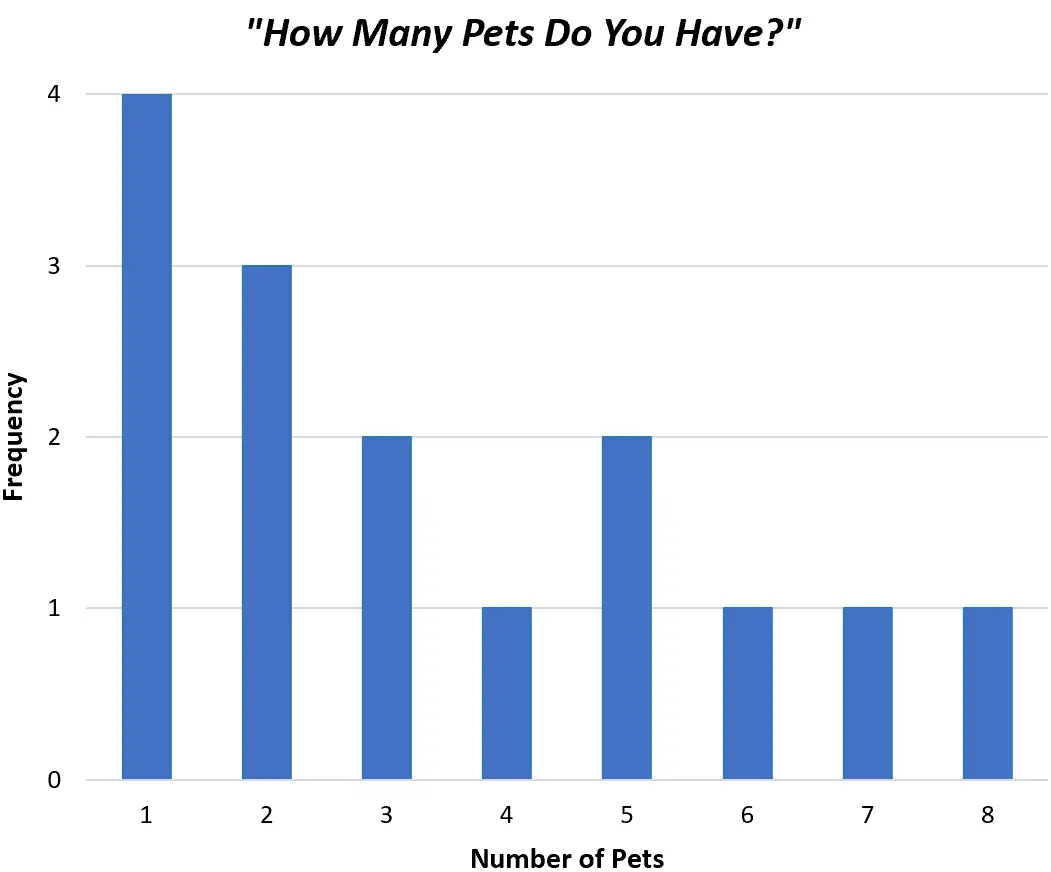
Ambos os gráficos nos permitem compreender rapidamente a distribuição dos valores em nosso conjunto de dados.
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais