Ajuste de curva em python (com exemplos)
Muitas vezes você pode querer ajustar uma curva a um conjunto de dados em Python.
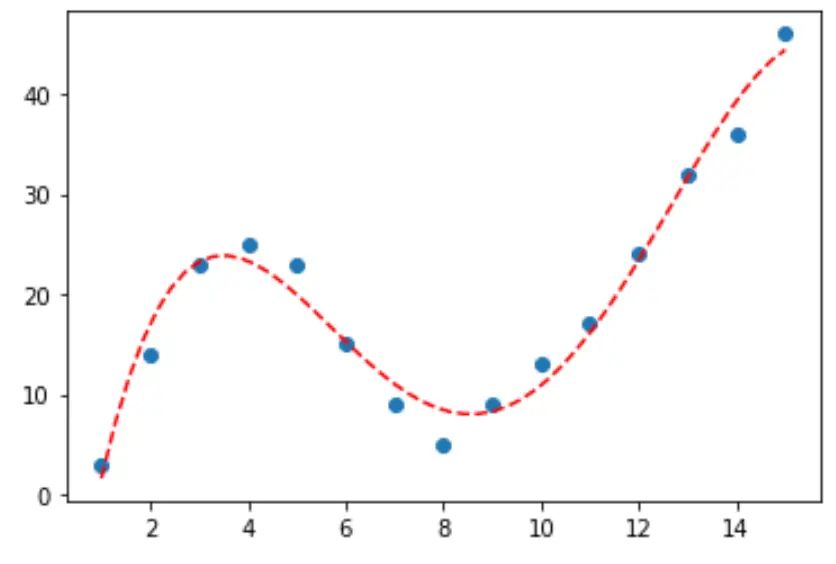
O exemplo passo a passo a seguir explica como ajustar curvas aos dados em Python usando a função numpy.polyfit() e como determinar qual curva melhor se ajusta aos dados.
Etapa 1: criar e visualizar dados
Vamos começar criando um conjunto de dados falso e, em seguida, criar um gráfico de dispersão para visualizar os dados:
import pandas as pd import matplotlib. pyplot as plt #createDataFrame df = pd. DataFrame ({' x ': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15], ' y ': [3, 14, 23, 25, 23, 15, 9, 5, 9, 13, 17, 24, 32, 36, 46]}) #create scatterplot of x vs. y plt. scatter (df. x , df. y )
Etapa 2: ajustar múltiplas curvas
Vamos então ajustar vários modelos de regressão polinomial aos dados e visualizar a curva de cada modelo no mesmo gráfico:
import numpy as np
#fit polynomial models up to degree 5
model1 = np. poly1d (np. polyfit (df. x , df. y , 1))
model2 = np. poly1d (np. polyfit (df. x , df. y , 2))
model3 = np. poly1d (np. polyfit (df. x , df. y , 3))
model4 = np. poly1d (np. polyfit (df. x , df. y , 4))
model5 = np. poly1d (np. polyfit (df. x , df. y , 5))
#create scatterplot
polyline = np. linspace (1, 15, 50)
plt. scatter (df. x , df. y )
#add fitted polynomial lines to scatterplot
plt. plot (polyline, model1(polyline), color=' green ')
plt. plot (polyline, model2(polyline), color=' red ')
plt. plot (polyline, model3(polyline), color=' purple ')
plt. plot (polyline, model4(polyline), color=' blue ')
plt. plot (polyline, model5(polyline), color=' orange ')
plt. show ()
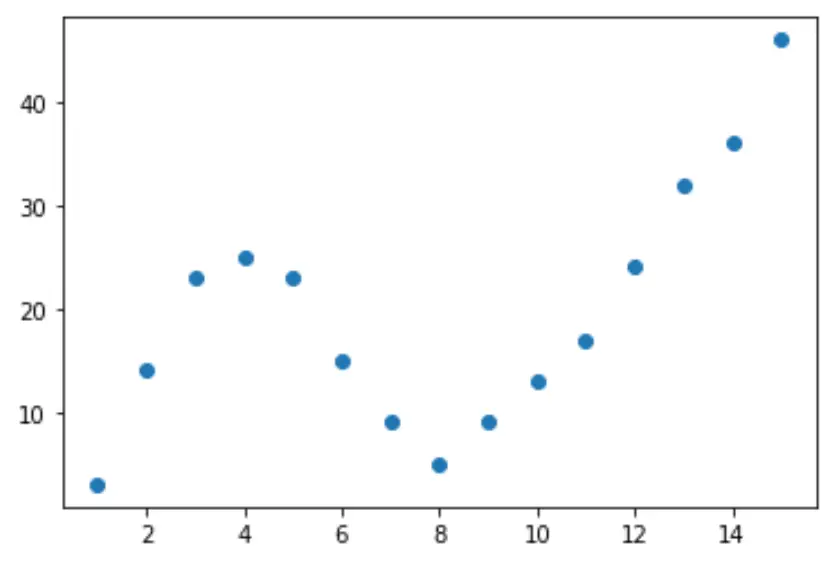
Para determinar qual curva melhor se ajusta aos dados, podemos observar o R quadrado ajustado de cada modelo.
Este valor nos diz a porcentagem de variação na variável resposta que pode ser explicada pela(s) variável(ões) preditora(s) no modelo, ajustada pelo número de variáveis preditoras.
#define function to calculate adjusted r-squared def adjR(x, y, degree): results = {} coeffs = np. polyfit (x, y, degree) p = np. poly1d (coeffs) yhat = p(x) ybar = np. sum (y)/len(y) ssreg = np. sum ((yhat-ybar)**2) sstot = np. sum ((y - ybar)**2) results[' r_squared '] = 1- (((1-(ssreg/sstot))*(len(y)-1))/(len(y)-degree-1)) return results #calculated adjusted R-squared of each model adjR(df. x , df. y , 1) adjR(df. x , df. y , 2) adjR(df. x , df. y , 3) adjR(df. x , df. y , 4) adjR(df. x , df. y , 5) {'r_squared': 0.3144819} {'r_squared': 0.5186706} {'r_squared': 0.7842864} {'r_squared': 0.9590276} {'r_squared': 0.9549709}
Pelo resultado, podemos perceber que o modelo com maior R-quadrado ajustado é o polinômio de quarto grau, que possui um R-quadrado ajustado de 0,959 .
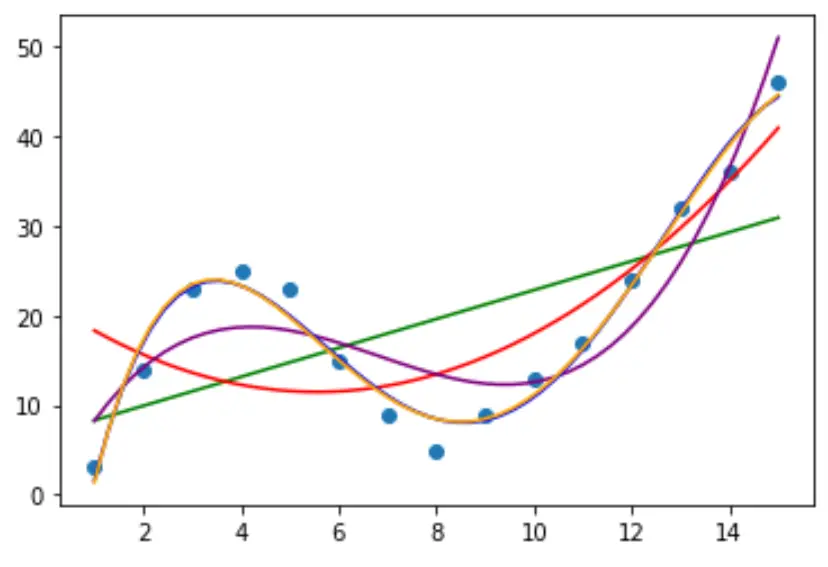
Passo 3: Visualize a curva final
Finalmente, podemos criar um gráfico de dispersão com a curva do modelo polinomial de quarto grau:
#fit fourth-degree polynomial model4 = np. poly1d (np. polyfit (df. x , df. y , 4)) #define scatterplot polyline = np. linspace (1, 15, 50) plt. scatter (df. x , df. y ) #add fitted polynomial curve to scatterplot plt. plot (polyline, model4(polyline), ' -- ', color=' red ') plt. show ()
Também podemos obter a equação desta linha usando a função print() :
print (model4)
4 3 2
-0.01924x + 0.7081x - 8.365x + 35.82x - 26.52
A equação da curva é a seguinte:
y = -0,01924x 4 + 0,7081x 3 – 8,365x 2 + 35,82x – 26,52
Podemos usar esta equação para prever o valor da variável de resposta com base nas variáveis preditoras do modelo. Por exemplo, se x = 4, então preveríamos que y = 23,32 :
y = -0,0192(4) 4 + 0,7081(4) 3 – 8,365(4) 2 + 35,82(4) – 26,52 = 23,32
Recursos adicionais
Uma introdução à regressão polinomial
Como realizar regressão polinomial em Python
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais