Como usar pandas get dummies – pd.get_dummies
Muitas vezes, nas estatísticas, os conjuntos de dados com os quais trabalhamos incluem variáveis categóricas .
Estas são variáveis que levam nomes ou rótulos. Exemplos incluem:
- Estado civil (“casado”, “solteiro”, “divorciado”)
- Status de tabagismo (“fumante”, “não fumante”)
- Cor dos olhos (“azul”, “verde”, “avelã”)
- Nível de escolaridade (por exemplo, “ensino médio”, “bacharelado”, “mestrado”)
Ao ajustar algoritmos de aprendizado de máquina (como regressão linear , regressão logística , florestas aleatórias , etc.), frequentemente convertemos variáveis categóricas em variáveis fictícias , que são variáveis numéricas usadas para representar dados categóricos.
Por exemplo, suponha que temos um conjunto de dados contendo a variável categórica Gender . Para utilizar esta variável como preditora em um modelo de regressão, primeiro seria necessário convertê-la em uma variável dummy.
Para criar esta variável dummy, podemos escolher um dos valores (“Masculino”) para representar 0 e o outro valor (“Feminino”) para representar 1:
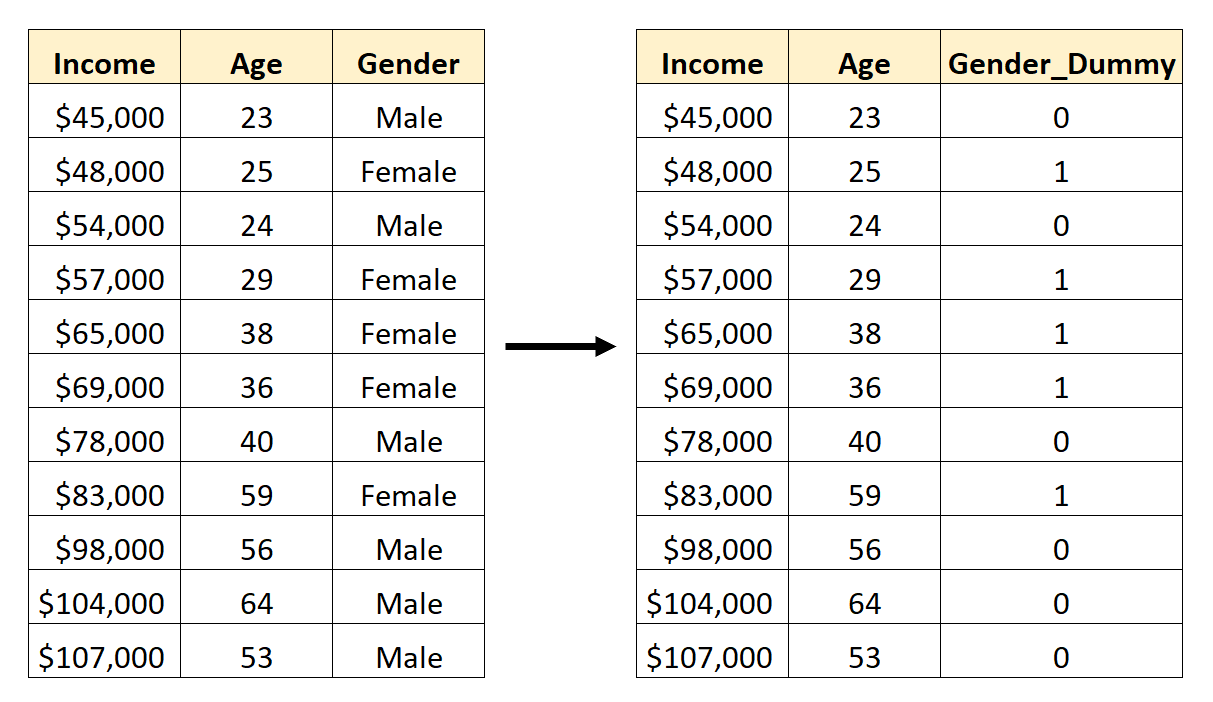
Como criar variáveis fictícias no Pandas
Para criar manequins para uma variável em um DataFrame do pandas, podemos usar a função pandas.get_dummies() , que usa a seguinte sintaxe básica:
pandas.get_dummies(dados, prefix=Nenhum, colunas=Nenhum, drop_first=Falso)
Ouro:
- data : O nome do DataFrame do pandas
- prefix : uma string a ser adicionada ao início da nova coluna de variável fictícia
- colunas : o nome da(s) coluna(s) a ser convertida em uma variável fictícia
- drop_first : se deve ou não eliminar a primeira coluna de variável fictícia
Os exemplos a seguir mostram como usar esta função na prática.
Exemplo 1: Crie uma única variável fictícia
Suponha que temos o seguinte DataFrame do pandas:
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M']}) #view DataFrame df income age gender 0 45 23 M 1 48 25 F 2 54 24 M 3 57 29 F 4 65 38 F 5 69 36 F 6 78 40 M
Podemos usar a função pd.get_dummies() para transformar o gênero em uma variável fictícia:
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender '], drop_first= True ) income age gender_M 0 45 23 1 1 48 25 0 2 54 24 1 3 57 29 0 4 65 38 0 5 69 36 0 6 78 40 1
A coluna de gênero agora é uma variável fictícia onde:
- Um valor de 0 representa “Feminino”
- Um valor de 1 representa “Masculino”
Exemplo 2: Crie múltiplas variáveis fictícias
Suponha que temos o seguinte DataFrame do pandas:
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M'], ' college ': ['Y', 'N', 'N', 'N', 'Y', 'Y', 'Y']}) #view DataFrame df income age gender college 0 45 23 M Y 1 48 25 F N 2 54 24 M N 3 57 29 F N 4 65 38 F Y 5 69 36 F Y 6 78 40 M Y
Podemos usar a função pd.get_dummies() para converter gênero e faculdade em variáveis fictícias:
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender ', ' college '], drop_first= True ) income age gender_M college_Y 0 45 23 1 1 1 48 25 0 0 2 54 24 1 0 3 57 29 0 0 4 65 38 0 1 5 69 36 0 1 6 78 40 1 1
A coluna de gênero agora é uma variável fictícia onde:
- Um valor de 0 representa “Feminino”
- Um valor de 1 representa “Masculino”
E a coluna da faculdade agora é uma variável fictícia onde:
- Um valor de 0 representa universidade “Não”
- Um valor de 1 representa “Sim” para a faculdade
Recursos adicionais
Como usar variáveis fictícias na análise de regressão
Qual é a armadilha da variável fictícia?
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais