Árvore de decisão vs florestas aleatórias: qual a diferença?
Uma árvore de decisão é um tipo de modelo de aprendizado de máquina usado quando o relacionamento entre um conjunto de variáveis preditoras e uma variável de resposta não é linear.
A ideia básica por trás de uma árvore de decisão é construir uma “árvore” usando um conjunto de variáveis preditoras que prevê o valor de uma variável de resposta usando regras de decisão.
Por exemplo, poderíamos utilizar as variáveis preditoras “anos jogados” e “média de home runs” para prever o salário anual de jogadores profissionais de beisebol.
Usando este conjunto de dados, o modelo de árvore de decisão poderia ser assim:
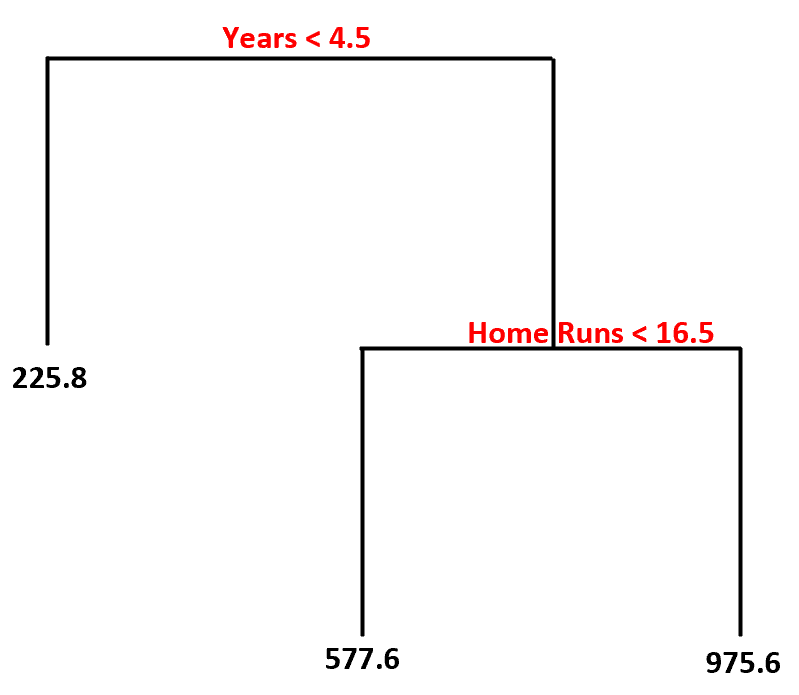
Aqui está como interpretaríamos esta árvore de decisão:
- Jogadores que jogaram menos de 4,5 anos têm um salário projetado de US$ 225,8 mil .
- Jogadores que jogaram mais de 4,5 anos ou mais e menos de 16,5 home runs em média têm um salário projetado de US$ 577,6 mil .
- Jogadores com 4,5 anos ou mais de experiência e uma média de 16,5 ou mais home runs têm um salário esperado de $ 975,6 mil .
A principal vantagem de uma árvore de decisão é que ela pode ser adaptada rapidamente a um conjunto de dados e o modelo final pode ser claramente visualizado e interpretado usando um diagrama de “árvore” como o acima.
A principal desvantagem é que uma árvore de decisão tende a se ajustar demais a um conjunto de dados de treinamento, o que significa que é provável que tenha um desempenho insatisfatório em dados não vistos. Isso também pode ser fortemente influenciado por valores discrepantes no conjunto de dados.
Uma extensão da árvore de decisão é um modelo conhecido como floresta aleatória , que é essencialmente um conjunto de árvores de decisão.
Aqui estão as etapas que usamos para criar um modelo de floresta aleatório:
1. Obtenha amostras inicializadas do conjunto de dados original.
2. Para cada amostra de bootstrap, crie uma árvore de decisão usando um subconjunto aleatório de variáveis preditoras.
3. Calcule a média das previsões de cada árvore para obter um modelo final.
A vantagem das florestas aleatórias é que elas tendem a ter um desempenho muito melhor do que as árvores de decisão em dados não vistos e são menos propensas a valores discrepantes.
A desvantagem das florestas aleatórias é que não há como visualizar o modelo final e construí-las pode levar muito tempo se você não tiver poder de computação suficiente ou se o conjunto de dados com o qual você está trabalhando for extremamente volumoso.
Vantagens e Desvantagens: Árvores de Decisão vs. Florestas Aleatórias
A tabela a seguir resume as vantagens e desvantagens das árvores de decisão em comparação com as florestas aleatórias:
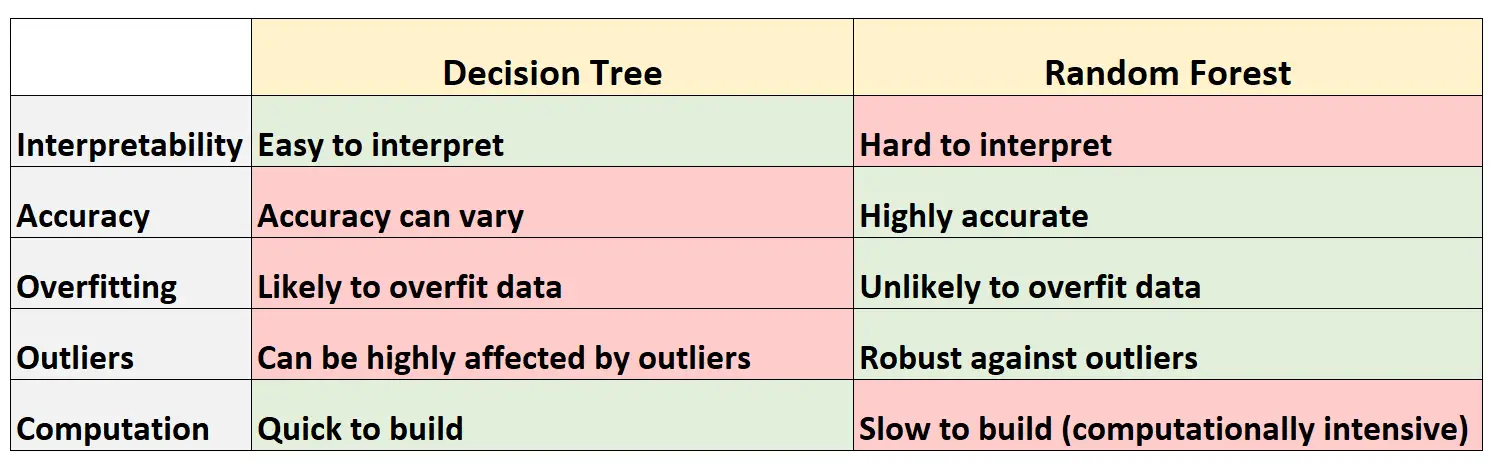
Aqui está uma breve explicação de cada linha da tabela:
1. Interpretabilidade
As árvores de decisão são fáceis de interpretar porque podemos criar um diagrama de árvore para visualizar e compreender o modelo final.
Por outro lado, não podemos visualizar uma floresta aleatória e muitas vezes pode ser difícil entender como o modelo final da floresta aleatória toma decisões.
2. Precisão
Como as árvores de decisão provavelmente se ajustam demais a um conjunto de dados de treinamento, elas tendem a ter pior desempenho em conjuntos de dados não vistos.
Por outro lado, florestas aleatórias tendem a ser muito precisas em conjuntos de dados não vistos porque evitam o ajuste excessivo de conjuntos de dados de treinamento.
3. Sobreajuste
Conforme mencionado anteriormente, as árvores de decisão muitas vezes se ajustam demais aos dados de treinamento: isso significa que elas provavelmente se adaptarão ao “ruído” de um conjunto de dados, em oposição ao verdadeiro modelo subjacente.
Por outro lado, como as florestas aleatórias usam apenas certas variáveis preditoras para construir cada árvore de decisão individual, as árvores finais tendem a ser decoradas, o que significa que é improvável que os modelos florestais aleatórios se ajustem excessivamente aos conjuntos de dados.
4. Valores discrepantes
As árvores de decisão são muito suscetíveis a serem afetadas por valores discrepantes.
Por outro lado, como um modelo florestal aleatório constrói muitas árvores de decisão individuais e depois obtém a média das previsões dessas árvores, é muito menos provável que seja afetado por valores discrepantes.
5. Cálculo
As árvores de decisão podem ser rapidamente adaptadas aos conjuntos de dados.
Por outro lado, as florestas aleatórias são muito mais intensivas em termos computacionais e podem levar muito tempo para serem criadas, dependendo do tamanho do conjunto de dados.
Quando usar árvores de decisão ou florestas aleatórias
Geralmente:
Você deve usar uma árvore de decisão se quiser criar rapidamente um modelo não linear e poder interpretar facilmente como o modelo toma decisões.
No entanto, você deve usar uma floresta aleatória se tiver muito poder computacional e quiser criar um modelo que provavelmente será muito preciso, sem se preocupar em como interpretar o modelo.
No mundo real, engenheiros de aprendizado de máquina e cientistas de dados costumam usar florestas aleatórias porque são muito precisas e os computadores e sistemas modernos muitas vezes podem lidar com grandes conjuntos de dados que antes não podiam ser manipulados.
Recursos adicionais
Os tutoriais a seguir fornecem uma introdução às árvores de decisão e aos modelos de floresta aleatórios:
Os tutoriais a seguir explicam como ajustar árvores de decisão e florestas aleatórias em R:
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais