Como realizar análise univariada em python: com exemplos
O termo análise univariada refere-se à análise de uma variável. Você pode se lembrar disso porque o prefixo “uni” significa “um”.
Existem três maneiras comuns de realizar análise univariada em uma variável:
1. Estatísticas resumidas – Mede o centro e a distribuição dos valores.
2. Tabela de Frequência – Descreve com que frequência aparecem valores diferentes.
3. Gráficos – Utilizados para visualizar a distribuição de valores.
Este tutorial fornece um exemplo de como realizar análise univariada com o seguinte DataFrame do pandas:
import pandas as pd #createDataFrame df = pd. DataFrame ({' points ': [1, 1, 2, 3.5, 4, 4, 4, 5, 5, 6.5, 7, 7.4, 8, 13, 14.2], ' assists ': [5, 7, 7, 9, 12, 9, 9, 4, 6, 8, 8, 9, 3, 2, 6], ' rebounds ': [11, 8, 10, 6, 6, 5, 9, 12, 6, 6, 7, 8, 7, 9, 15]}) #view first five rows of DataFrame df. head () points assists rebounds 0 1.0 5 11 1 1.0 7 8 2 2.0 7 10 3 3.5 9 6 4 4.0 12 6
1. Calcule estatísticas resumidas
Podemos usar a seguinte sintaxe para calcular várias estatísticas resumidas para a variável “pontos” no DataFrame:
#calculate mean of 'points' df[' points ']. mean () 5.706666666666667 #calculate median of 'points' df[' points ']. median () 5.0 #calculate standard deviation of 'points' df[' points ']. std () 3.858287308169384
2. Crie uma tabela de frequência
Podemos usar a seguinte sintaxe para criar uma tabela de frequência para a variável ‘pontos’:
#create frequency table for 'points' df[' points ']. value_counts () 4.0 3 1.0 2 5.0 2 2.0 1 3.5 1 6.5 1 7.0 1 7.4 1 8.0 1 13.0 1 14.2 1 Name: points, dtype: int64
Isso nos diz que:
- O valor 4 aparece 3 vezes
- O valor 1 aparece duas vezes
- O valor 5 aparece duas vezes
- O valor 2 aparece 1 vez
E assim por diante.
Relacionado: Como criar tabelas de frequência em Python
3. Crie gráficos
Podemos usar a seguinte sintaxe para criar um boxplot para a variável ‘pontos’:
import matplotlib. pyplot as plt df. boxplot (column=[' points '], grid= False , color=' black ')
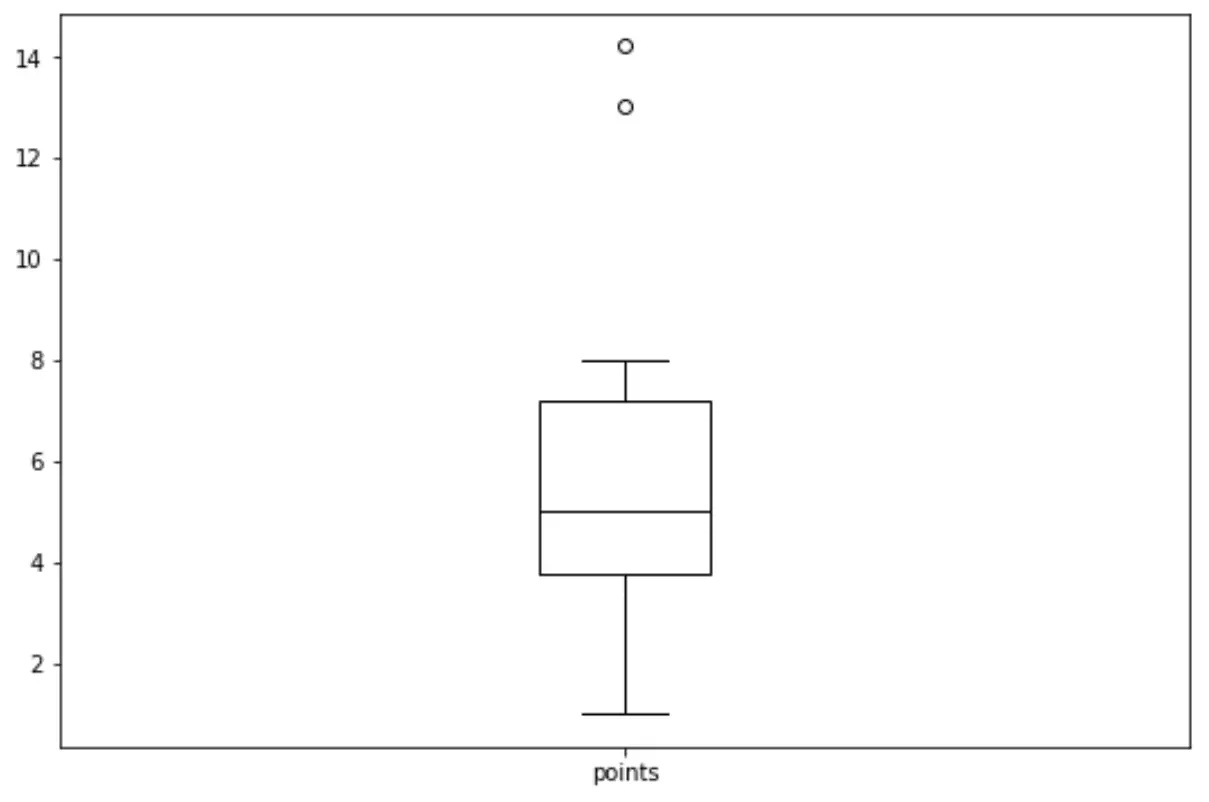
Relacionado: Como criar um Boxplot a partir do Pandas DataFrame
Podemos usar a seguinte sintaxe para criar um histograma para a variável ‘pontos’:
import matplotlib. pyplot as plt df. hist (column=' points ', grid= False , edgecolor=' black ')
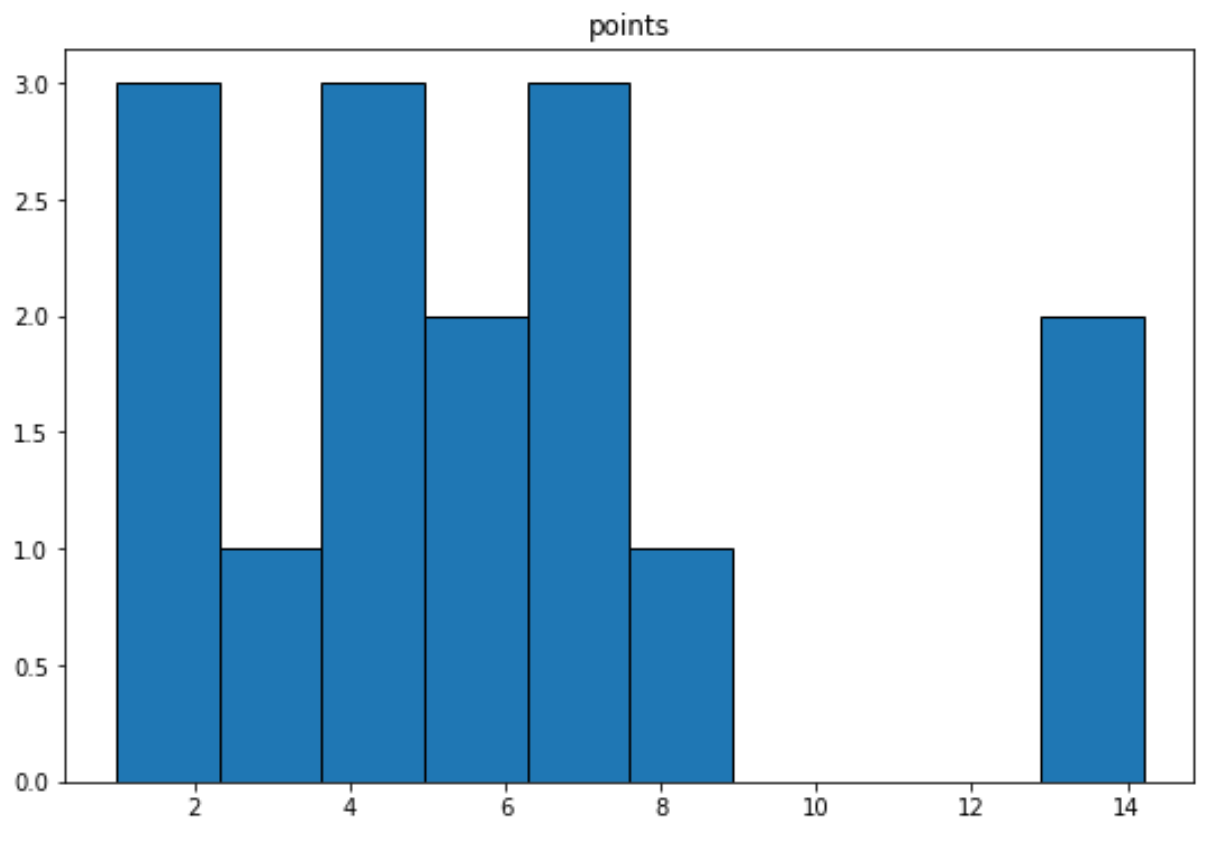
Relacionado: Como criar um histograma a partir do Pandas DataFrame
Podemos usar a seguinte sintaxe para criar uma curva de densidade para a variável “pontos”:
import seaborn as sns sns. kdeplot (df[' points '])
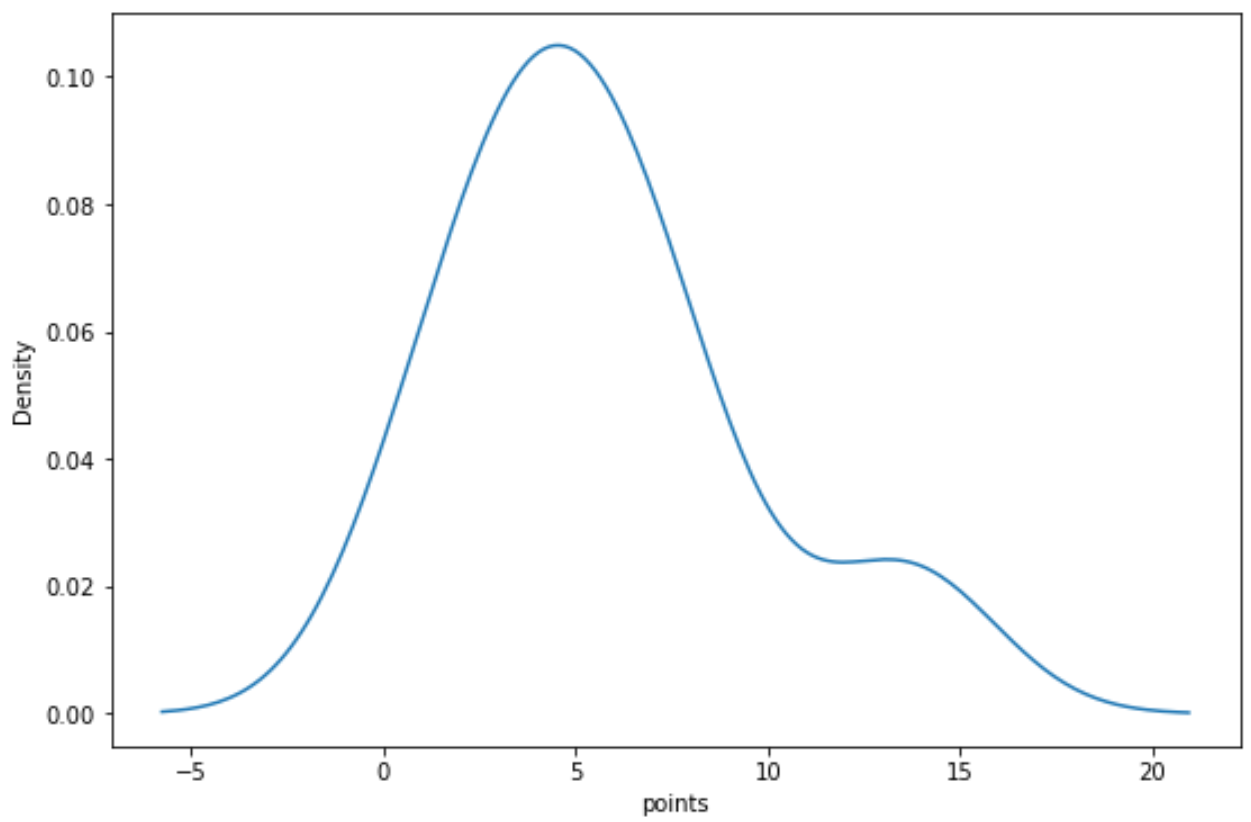
Relacionado:Como criar um gráfico de densidade no Matplotlib
Cada um desses gráficos nos dá uma forma única de visualizar a distribuição dos valores da variável “pontos”.
About Author
Dr. benjamim anderson
Olá, sou Benjamin, um professor aposentado de estatística que se tornou professor dedicado na Statorials. Com vasta experiência e conhecimento na área de estatística, estou empenhado em compartilhar meu conhecimento para capacitar os alunos por meio de Statorials. Saber mais